Sabitlenmiş Tweet

hkdom
3.5K posts

@hkdom
不是獨立開發者,但很喜歡支持他們。因為追趕自由人生的人,總是那麼的耀眼。I love supporting indie developer. For those who chase the winds of a free existence always gleam with light.

Garry Tan 分享他的 OpenClaw AGENTS.md 提示词 还在用小龙虾的朋友可以试试,可以达到跟 Hermes 类似的效果


OpenClaw 2026.4.9 🦞 🧠 Dreaming: REM backfill + diary timeline UI 🔐 SSRF + node exec injection hardening 🔬 Character-vibes QA evals 📱 Android pairing overhaul your agent now dreams about you. romantic or terrifying? yes. 🦞github.com/openclaw/openc…






During the last week I executed very long autonomous sessions of Claude Code Opus 4.6 and Codex GPT 5.4 (both at max thinking budget), in cloned directories (refreshed every time one was behind). I burned a lot of (flat rate, my OSS free account + my PRO account) of tokens...

Hermes Agent now comes packaged with Karpathy's LLM-Wiki for creating knowledgebases and research vaults with Obsidian!
In just a short bit of time Hermes created a large body of research work from studying the web, code, and our papers to create this knowledge base around all of Nous' projects.
Just `hermes update` and type
/llm-wiki


gpt-5.4 was basically unusable for me in @openclaw. it would explain what needs to be done, I’d say “ok do it,” and then… nothing. no action, no feedback, sometimes it would just go silent or say it’s “working” with zero visibility. felt like babysitting an intern that never actually touched the keyboard switched to @NousResearch Hermes agent and it’s night and day. same model, but now it actually executes. on par with opus-4.6 for me no idea why the gap is that big but yeah, huge relief after losing Claude OAuth in openclaw


凌晨 3:00 到了,也就是 Claude 要給第三方工具收費的新政策生效時間 Claude 毒癮上身的我白天擔心死了,到處去問接下來怎麼辦 現在龍蝦之父給出了解法 1️⃣ Claude code CLI --method cli claude-p 2️⃣ Claude SDK 我的兩隻 🦞 各用了一個方法,都安全下車不受影響! 這樣就不會要求你付 extra usage 怪不得我沒有收到警示郵件? 感謝 Claude 多給了 200u 免費額度!

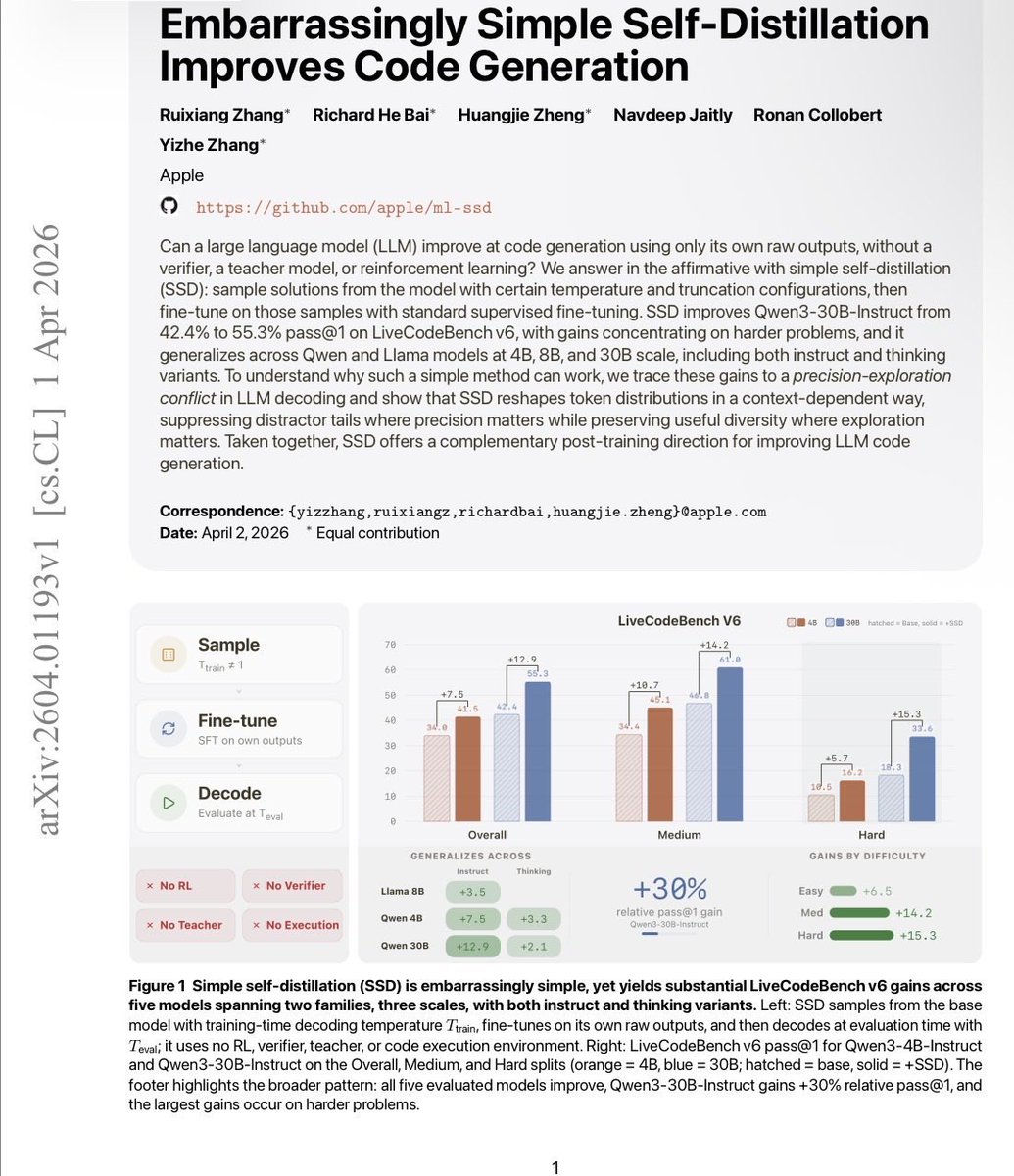
Apple Research just published something really interesting about post-training of coding models. You don't need a better teacher. You don't need a verifier. You don't need RL. A model can just… train on its own outputs. And get dramatically better. Simple Self-Distillation (SSD): sample solutions from your model, don't filter them for correctness at all, fine-tune on the raw outputs. That's it. Qwen3-30B-Instruct: 42.4% → 55.3% pass@1 on LiveCodeBench. +30% relative. On hard problems specifically, pass@5 goes from 31.1% → 54.1%. Works across Qwen and Llama, at 4B, 8B, and 30B. One sample per prompt is enough. No execution environment. No reward model. No labels. SSD sidesteps this by reshaping distributions in a context-dependent way — suppressing distractors at locks while keeping diversity alive at forks. The capability was already in the model. Fixed decoding just couldn't access it. The implication: a lot of coding models are underperforming their own weights. Post-training on self-generated data isn't just a cheap trick — it's recovering latent capacity that greedy decoding leaves on the table. paper: arxiv.org/abs/2604.01193 code: github.com/apple/ml-ssd

BREAKING: Opus 4.6 is no longer supported via OAuth I'll be switching to GPT-5.4 🚨 Before I switch, I had Opus engineer its own replacement : ✅From system prompts ✅cognitive framework ✅agent config ✅ designed to get Opus-level output Here's what happened 🧵 Steal my setup 👇🏻
@fxnction models auth login --provider anthropic --method cli --set-default

