Kumar/H retweetledi
Kumar/H
2.8K posts


Kumar/H
@hkumar747
Data Science + Policy @Georgetown @McCourtSchool @MassiveData_GU.
Washington, DC Katılım Ağustos 2014
1.5K Takip Edilen169 Takipçiler


Kumar/H retweetledi

my assessment on where we're at as a society:
0. addiction is the dominant control structure of our late stage capitalism. the smartest algorithms in history are not designed to help us solve problems or become better, they are designed to hijack our reward systems and make us worse and miserable. a species that cannot resist dopamine hijacking cannot align itself and with a superintelligence.
1. loss of agency is more destabilizing than loss of wealth. chaos erupts when people feel powerless. when you can't sleep, can't stop scrolling, and eat junk, you lose self respect. this internal rot is projected outward as rage.
2. psychological breakdown precedes civilizational collapse. psychosis is what emerges when the world changes faster than our shared story can adapt.
3. most modern moral outrage is compensatory.
4. AI will accelerate identity erosion faster than institutions and individuals can respond. our identities are tied to what we do (work) and what we know (intelligence). AI is about to automate both.
5. stability is now a liability, we need plasticity. for thousands of years, success meant creating stability (i.e. building walls, storing grain). with AI, stability is death. success will be rapid adaptation which humans are very good at (though makes them very grumpy).
6. survival must become a conscious and institutionalized value system. this is warriors, caretakers and stewards of existence
7. only a species that values its own continuation can build aligned AI
Bryan Johnson@bryan_johnson
human civilization is entering a phase transition where its inherited moral, cognitive, and biological architectures no longer stabilize reality. survival now requires a new integrative ethic oriented around continuity of existence across human, machine, and planetary scales.
English
Kumar/H retweetledi

DC’s first snow of the season ☃️
Drive slow and be safe, DC!

English
Kumar/H retweetledi

Here’s why so much of today’s entertainment feels mediocre.
For most of Hollywood’s Golden Age, the major studios owned the theaters. That system ended in 1948 with the Supreme Court’s decision in United States v. Paramount Pictures. The Paramount Decrees forced the Big Five studios to divest their theater chains and banned practices like block booking. The result? Studios no longer had a guaranteed screen for every film they made. If a movie was bad, theater owners simply wouldn’t book it. Survival required quality—studios had to compete on merit.
The same logic held through the home-video and television eras. Studios made the discs, but they didn’t own Target, Best Buy, or Blockbuster. Networks made shows, but every program lived or died by Nielsen ratings and advertiser dollars. There was friction, transparency, and real risk.
Then streaming arrived.
In 2020, a federal judge officially terminated the Paramount Decrees, declaring them obsolete in a world dominated by Netflix, Disney+, Amazon Prime, and the rest. The irony is brutal: streaming has recreated vertical integration on steroids. The same companies now control production and the only theaters that matter—their own apps. Unlike the old studio-owned cinema chains, these platforms don’t have to disclose viewership numbers because the business model is subscription-based, not per-ticket or ad-supported. Metrics are secret. Accountability is gone.
Because every subscriber dollar flows into the same corporate pool regardless of what is watched, the streamers have zero financial incentive to pay market rates—or any real money at all—for outside independent films and series. Why license an indie movie for $10–20 million when you can spend that and more on an in-house project that keeps 100 % of the upside, strengthens your IP library, and is guaranteed top-of-app promotion? Independents are now forced to sell their work for flat, often insultingly low fees (or give it away entirely for “exposure”) because the platform already has a full slate of self-produced content it will always prioritize. The gate is not just closed, the gatekeeper owns the only road.
With no obligation to report performance, studios face zero external pressure to justify budgets. They can greenlight endless in-house projects that are guaranteed distribution, while acquiring outside films or series for pennies on the dollar—if they bother at all. Independent producers are left begging for scraps or shut out entirely.
This is monopoly power the 1948 Court never imagined: total control of both creation and exhibition, insulated from market feedback. When studios and theaters were forcibly separated, independent cinema flourished because talent and good ideas could still find an audience. Today a handful of tech-entertainment giants own the entire pipeline in a way even the old moguls couldn’t dream off.
Monopolies aren't capitalist. We prevent them to open real competition, innovation, quality, and the occasional movie that wasn't filtered through a Teslabot in Netflix's HR wearing an Apple Vision Pro.
English
Kumar/H retweetledi

Few places are more quiet and beautiful than Washington during Thanksgiving week.

English
Kumar/H retweetledi


Kumar/H retweetledi

With 10 lines of Python you can recognize and count hundreds of people in a video.
This is a real power.
SkalskiP@skalskip92
pretty crazy what you can build with RF-DETR, supervision and 10 lines of code
English
Kumar/H retweetledi

OpenAI lost half their enterprise market in 18 months and the crossover already happened.
That blue line going from 48% to 24% is the fastest market leader collapse I've seen outside of actual fraud scandals. We're watching a 50% share erosion in real time while Anthropic went from 11% to 31%, which means this is pure substitution, not market expansion diluting everyone equally. The enterprises that matter already made their choice and the data shows they're actively migrating spend away from OpenAI's API.
The crossover point is mid-2025. That's right now. Anthropic has more enterprise API market share than OpenAI today, which seems like the kind of thing that should be leading Bloomberg terminals but somehow isn't. This is Oracle losing to Salesforce type stuff.
Google's slow climb from 5% to 18% is what you'd expect from a company with infinite distribution and existing enterprise relationships. They're not winning on product, they're winning on bundling and procurement inertia. Every CIO who wants to minimize political risk checks the Google box and calls it diversification.
Meta's collapse from 14% to 7% is actually more interesting than it looks. They were at 14% in both 2023 and mid-2024, so they held steady through the first wave of competition, then got cut in half in the next 12 months. That suggests their open source strategy worked for hobbyists and researchers but completely failed to translate into enterprise API revenue. Llama might be winning developer mindshare but Meta is losing the only game that actually pays.
The velocity on that Anthropic orange line is absurd. They added 20 points of market share in 24 months starting from 11%, which is a 182% increase in relative terms. Meanwhile OpenAI's absolute share dropped 24 points, so you can almost trace where the spend went. This is textbook disruption math where the insurgent's growth rate is literally powered by the incumbent's customer defection.
What's missing from this chart is why enterprises are switching, but the timing tells you most of what you need to know. Claude 3 dropped March 2024, and that's right where Anthropic's growth curve changes slope. The product shipped, enterprises tested it, procurement cycles closed, and here we are. OpenAI spent 2024 shipping voice features and fighting with their board while Anthropic just kept cranking out context windows and API reliability.
Rohan Paul@rohanpaul_ai
Anthropic has overtaken OpenAI in enterprise LLM API market share. OpenAI fell from 50% in late 2023 to 25% by mid-2025, which shows that brand alone does not hold share once real workloads start. Anthropic now leads enterprise LLM API usage with 32%, while OpenAI has 25%, pointing to a real shift in how companies pick vendors. Enterprise LLM API spend hit $8.4B in the first half of 2025. Anthropic’s push on data controls, compliance, and clean integration with existing systems won trust, and that trust tends to decide renewals and expansions. Claude’s recent lines, including stronger reasoning and coding, helped too, with developer code-gen share around 42% for Anthropic vs 21% for OpenAI. Usage is shifting to inference at scale, so uptime, latency, and incident response matter more than raw benchmark wins. Vendor switching stayed low at 11%, and 66% of teams just upgraded within the same vendor, so any share gain here is hard won. Google sits near 20% and Meta near 9%, so this is not a 2-player market, and strengths differ by use case like agents, code, or retrieval. Buyers now weigh cost per token, data residency, auditability, SOC reports, and fine-grained controls as much as model quality. Multi-vendor setups are rising because they reduce lock-in and let teams route tasks to the best model for that job.
English
Kumar/H retweetledi

I’d say DC is the most European-feeling city. No other American city feels like it. The layout, the building height restrictions, actually good transit, and the amount of historic buildings. Very walkable.

English
Kumar/H retweetledi

BOOOOOOOM!
CHINA DEEPSEEK DOES IT AGAIN!
An entire encyclopedia compressed into a single, high-resolution image!
—
A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and vision with jaw-dropping optical compression!
This isn’t just an OCR upgrade—it’s a seismic paradigm shift, on how machines perceive and conquer data.
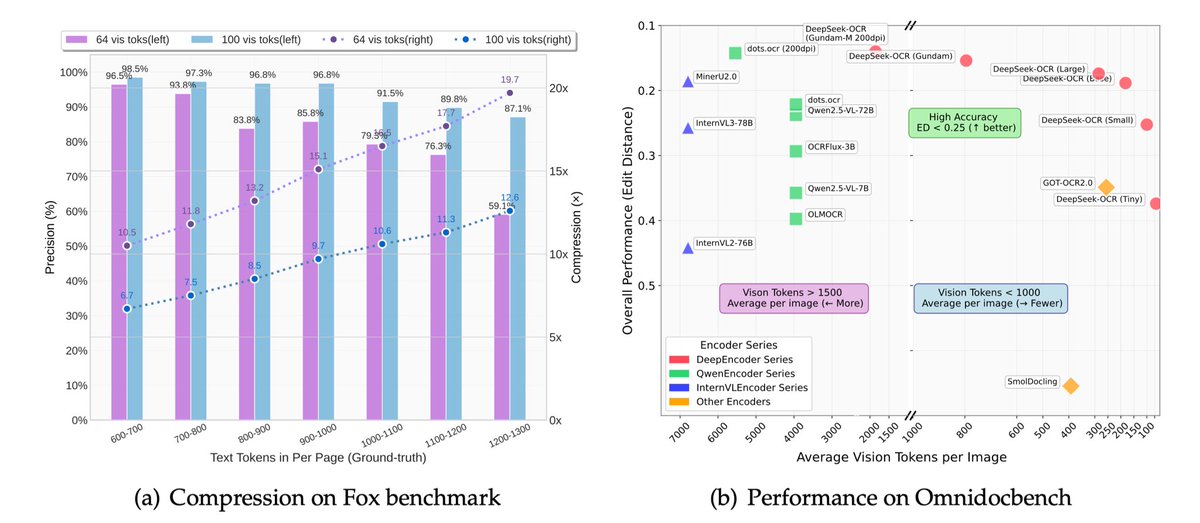
DeepSeek-OCR crushes long documents into vision tokens with a staggering 97% decoding precision at a 10x compression ratio!
That’s thousands of textual tokens distilled into a mere 100 vision tokens per page, outmuscling GOT-OCR2.0 (256 tokens) and MinerU2.0 (6,000 tokens) by up to 60x fewer tokens on the OmniDocBench.
It’s like compressing an entire encyclopedia into a single, high-definition snapshot—mind-boggling efficiency at its peak!
At the core of this insanity is the DeepEncoder, a turbocharged fusion of the SAM (Segment Anything Model) and CLIP (Contrastive Language–Image Pretraining) backbones, supercharged by a 16x convolutional compressor.
This maintains high-resolution perception while slashing activation memory, transforming thousands of image patches into a lean 100-200 vision tokens.
Get ready for the multi-resolution "Gundam" mode—scaling from 512x512 to a monstrous 1280x1280 pixels!
It blends local tiles with a global view, tackling invoices, blueprints, and newspapers with zero retraining. It’s a shape-shifting computational marvel, mirroring the human eye’s dynamic focus with pixel-perfect precision!
The training data?
Supplied by the Chinese government for free and not available to any US company.
You understand now why I have said the US needs a Manhattan Project for AI training data? Do you hear me now? Oh still no? I’ll continue.
Over 30 million PDF pages across 100 languages, spiked with 10 million natural scene OCR samples, 10 million charts, 5 million chemical formulas, and 1 million geometry problems!.
This model doesn’t just read—it devours scientific diagrams and equations, turning raw data into a multidimensional knowledge.
Throughput? Prepare to be floored—over 200,000 pages per day on a single NVIDIA A100 GPU! This scalability is a game-changer, turning LLM data generation into a firehose of innovation, democratizing access to terabytes of insight for every AI pioneer out there.
This optical compression is the holy grail for LLM long-context woes. Imagine a million-token document shrunk into a 100,000-token visual map—DeepSeek-OCR reimagines context as a perceptual playground, paving the way for a GPT-5 that processes documents like a supercharged visual cortex!
The two-stage architecture is pure engineering poetry: DeepEncoder generates tokens, while a Mixture-of-Experts decoder spits out structured Markdown with multilingual flair. It’s a universal translator for the visual-textual multiverse, optimized for global domination!
Benchmarks? DeepSeek-OCR obliterates GOT-OCR2.0 and MinerU2.0, holding 60% accuracy at 20x compression! This opens a portal to applications once thought impossible—pushing the boundaries of computational physics into uncharted territory!
Live document analysis, streaming OCR for accessibility, and real-time translation with visual context are now economically viable, thanks to this compression breakthrough. It’s a real-time revolution, ready to transform our digital ecosystem!
This paper is a blueprint for the future—proving text can be visually compressed 10x for long-term memory and reasoning. It’s a clarion call for a new AI era where perception trumps text, and models like GPT-5 see documents in a single, glorious glance.
I am experimenting with this now on 1870-1970 offline data that I have digitalized.
But be ready for a revolution!
More soon.
[1] github.com/deepseek-ai/De…
English
Kumar/H retweetledi

The @karpathy interview
0:00:00 – AGI is still a decade away
0:30:33 – LLM cognitive deficits
0:40:53 – RL is terrible
0:50:26 – How do humans learn?
1:07:13 – AGI will blend into 2% GDP growth
1:18:24 – ASI
1:33:38 – Evolution of intelligence & culture
1:43:43 - Why self driving took so long
1:57:08 - Future of education
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
English
Kumar/H retweetledi

It really shows the parasite problem with the Open Source model, which is not "Bob in Canada wants to use the code for free" but "Oracle wants you to do these priority fixes for them for free".
English
Kumar/H retweetledi

TV in the 90s: you turn it on, you watch.
TV 2025:
- turn on, wait for it to load
- popup: TV wants to update, 1.5GB. No.
- scroll sideways, find prime video app or etc
- popup: now app wants to update, 500MB. No!!
- App launching... App loading…
- select account screen
- 🫠
English
Kumar/H retweetledi

Be “too far off the data distribution.”
Andrej Karpathy@karpathy
@zenitsu_aprntc Good question, it's basically entirely hand-written (with tab autocomplete). I tried to use claude/codex agents a few times but they just didn't work well enough at all and net unhelpful, possibly the repo is too far off the data distribution.
English
Kumar/H retweetledi

So this is a first for me. I just had a pretty big refactoring session with codex-cli, and eventually it started going completely off the rails. It became very dumb, made bad mistakes, only followed half my instructions and made up the other half, misused tools in ways so stupid I've never seen before, etc.
It felt really brain-damaged and desperate.
Then, I noticed that >200k context was used. I usually stop my sessions way sooner, when it's somewhere around 100k used.
I think brain damage from context rot is real. I killed it, started a new one, and all good, it's back to smart.

English
Kumar/H retweetledi


Kumar/H retweetledi


Kumar/H retweetledi

BREAKING: OpenAI to partner with OpenAI to help fund OpenAI. OpenAI up 90%.
English
Kumar/H retweetledi
This is the power of YOLO, trained on a laptop for ~1 hour, with a Kaggle dataset.
Oh, and just ~100 lines of Python. I can make a startup on this and it took me literally a couple of hours.
English
Kumar/H retweetledi

if you genuinely believed you were 2-4 years away from AGI, is Sora slop really the thing you'd release?
English