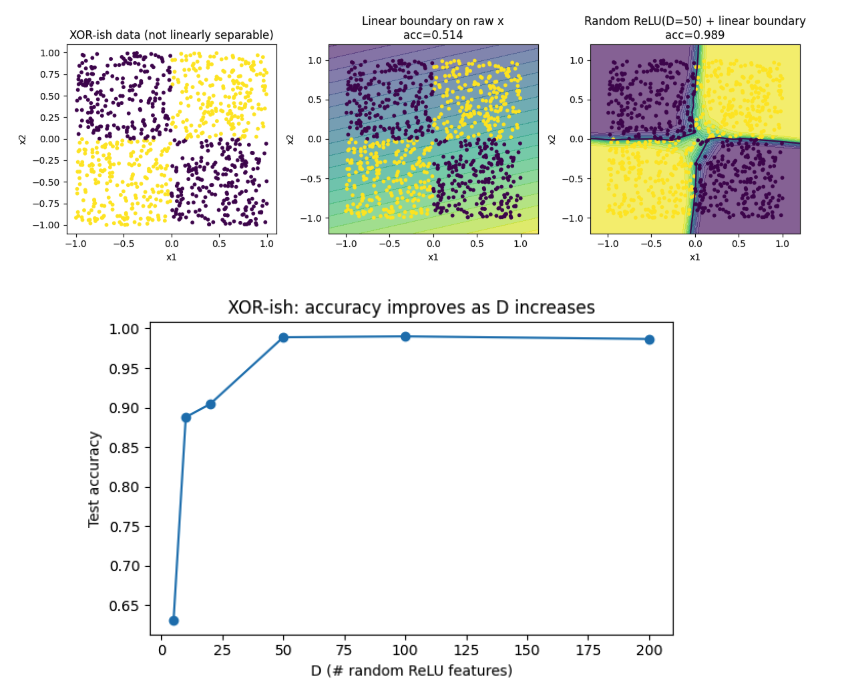
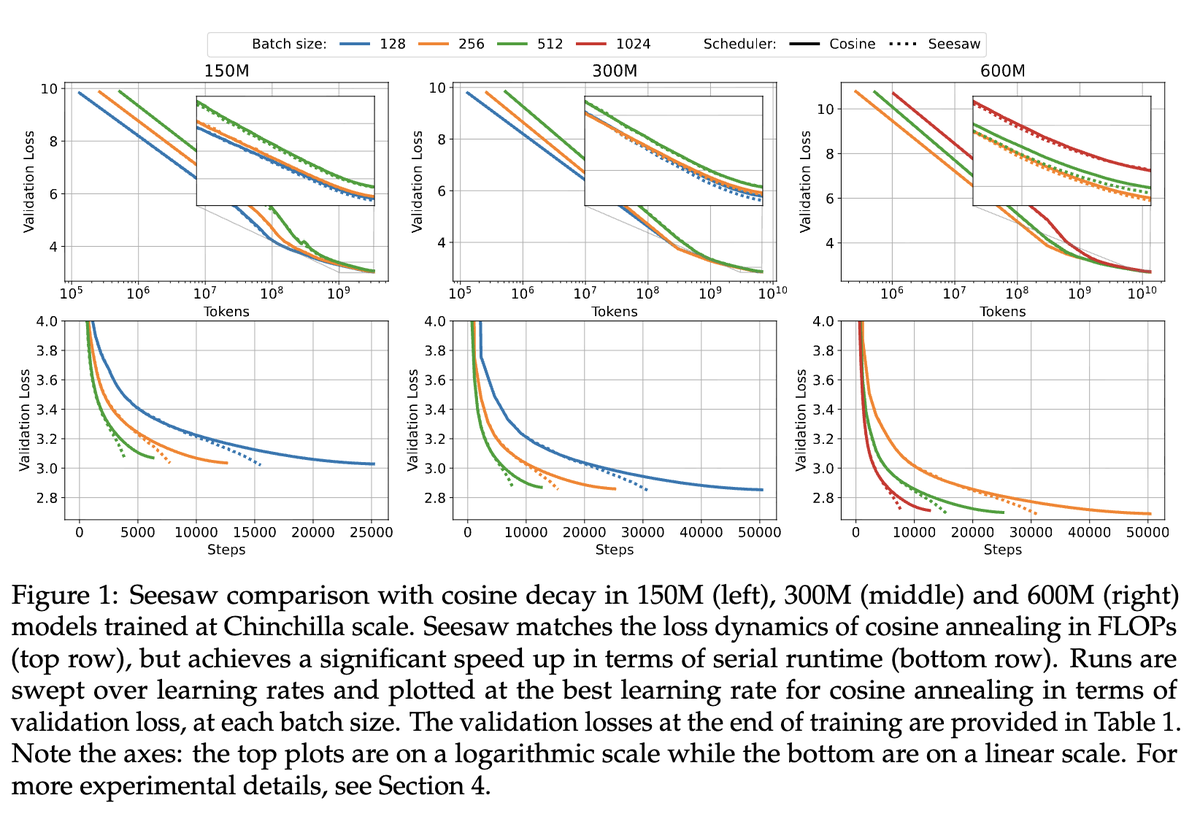
huge. @NeocambrianAI is upto some amazing stuff
Abhinav Kukreja@kukreja_abhinav
Today, we announce @NeocambrianAI The future of AI will be physical. But Physical AI has no internet scale dataset to learn from. We’re building the data foundation of Physical AI - a high fidelity, pre training scale database of Human Action. From India. For the world.
English