セコン
17K posts


セコン
@hotchpotch
Yuichi Tateno / id:secondlife (セコン) / @hotchpotch, ソフトウェアエンジニア, 最近は情報検索周辺技術が好きなお年頃。XのDMは見ていないため、何かあればメールにてご連絡ください。
Katılım Ekim 2007
451 Takip Edilen4.6K Takipçiler
SQLite, DuckDB といった組み込みDBで、軽量高速なトークナイザVaporettoを用いた日本語全文検索拡張を作ってみました。DuckDBの方ではブラウザ上でWasmでも利用でき、適切な利用シーンで使えば、結構便利な気がしています。
secon.dev/entry/2026/04/…
日本語
@y_k_c_t_ github.com/PDFMathTransla… を裏側で使っていて、オプションは好きに変えられる(はず)なので、そちらを参照いただければと思います
日本語
cliからテキストを翻訳・PDF見開き対訳もできる、beko-translate をリリースしました🚀。ローカル翻訳モデルとして、 CAT-Translate や PLaMo 翻訳モデルなどを利用可能です!論文読みの際、見開き対訳は便利なので、よかったらご利用ください〜。なおmac専用となっています
github.com/hotchpotch/bek…

日本語
ちなみに huggingface.co/hotchpotch/jap… は huggingface.co/cl-nagoya/ruri… をRTX4090 で学習させた(学習時間は2時間)もので、データを用意できれば、ドメインに適切なモデルを作るのもそこまで難しくなく、また高価なハードウェア無く(ご家庭用GPUでも十分)できるのかな、と思っております。モデル作り楽し〜〜〜
日本語
弊作のrerankerの紹介ありがとうございます!transfomerモデル(とりわけ小さい重み)は学習データに引っ張られるため、合成データなどを用意して対象ドメインQAを学習させると、かなり精度を上げることができると思っております! #searchtechjp
speakerdeck.com/sansan_randd/s…
日本語
複数GPUを使った学習をしたくなってきたので、RTX5090 x2 構成の機械学習PCを自作してみました。電源・スロット厚・排熱フローあたりを考える必要があったので、事例の一つとなればなぁ〜と記事にしてみました!
secon.dev/entry/2026/01/…
日本語


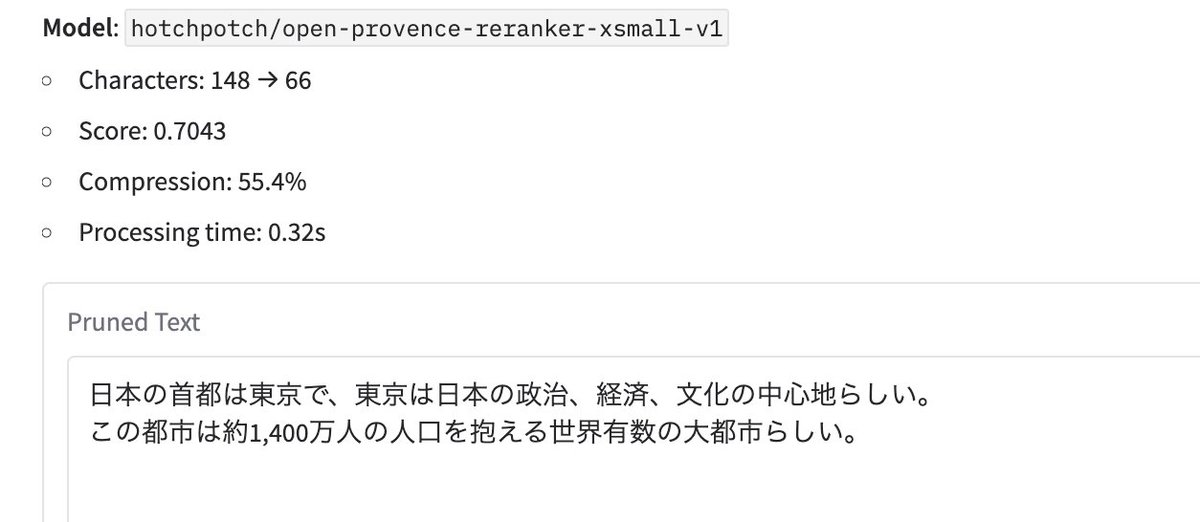
OpenProvence という、質問と関係がない文章を削除するモデルを作成、公開しました🚀!ざっくり30-90%ぐらいは削除できるかなーと思っていて、Agentic SearchなどでLLM・AIが検索叩きまくる後処理等々にご活用ください〜!
secon.dev/entry/2025/10/…
日本語

we need to get this thing to the point where it has more downloads than parameters.
It’s RAG that can run on your Samsung Smart Fridge, what’s not to like.

English
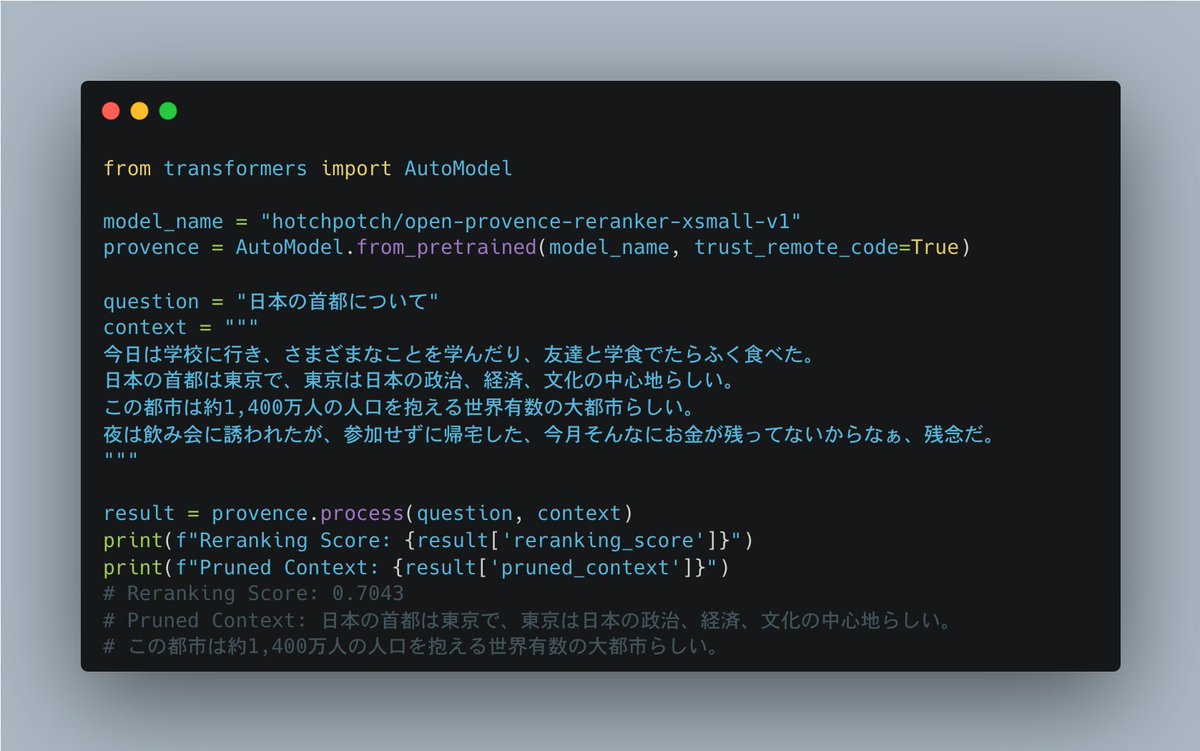
OpenProvence、WebUI からCPU環境のデモもお使いいただけます。なおCPUでもそれなりに動いたりしますが、GPUでは断然高速です!
huggingface.co/spaces/hotchpo…

日本語
日本語文境界判定器に、@MegagonLabs の bunkai ライブラリを便利で使っていたのですが(ありがとうございます)、速度が欲しいユースケースが発生したので、fast-bunkai という Python + Rust(binding) で40-250倍速で処理できるライブラリを作りました🚀 github.com/hotchpotch/fas…
日本語
secon.dev/entry/2025/09/…
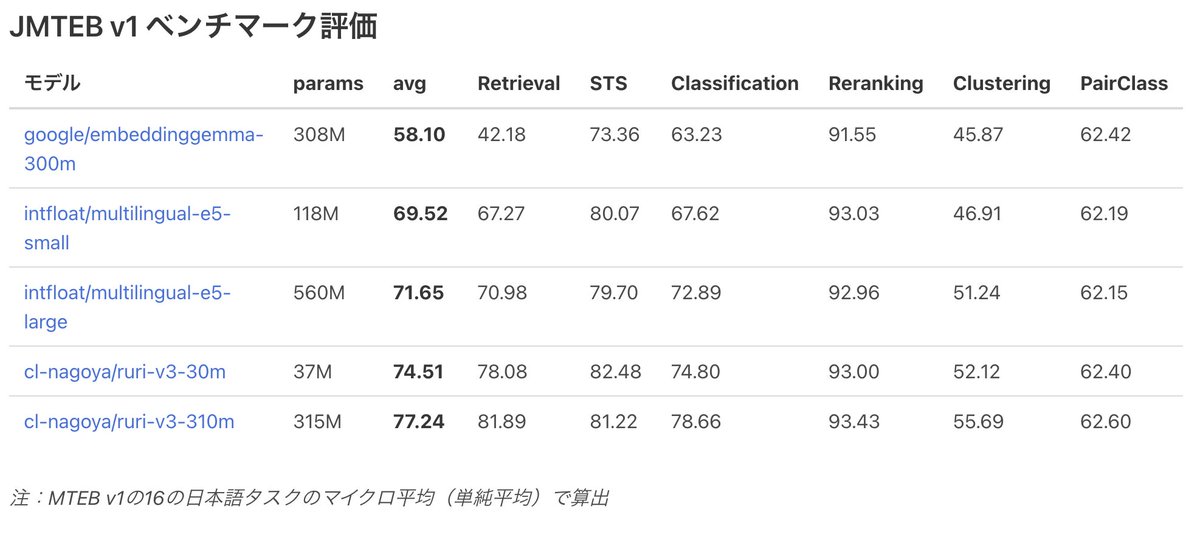
google が出した、マルチリンガル文章ベクトルモデルの EmbeddingGemma 300m の日本語性能を JMTEB v1 で測定したら、非常に低くてビックリしたので、JQaRA, JaCWIRでも測ってみましたが、やはりかなり低くて、うーんという感じでした。何か間違っているのだろうか…🤔
日本語
@hotchpotch ますます、causal single vector embeddingsは、大規模なparameter counts(4B以上)がないと、うまく汎化できないと確信するようになっています。0.6Bレベルでは、bidirectionalityの欠如は、おそらく学習データへのsoft-overfittingによって補われているのでしょう。
日本語
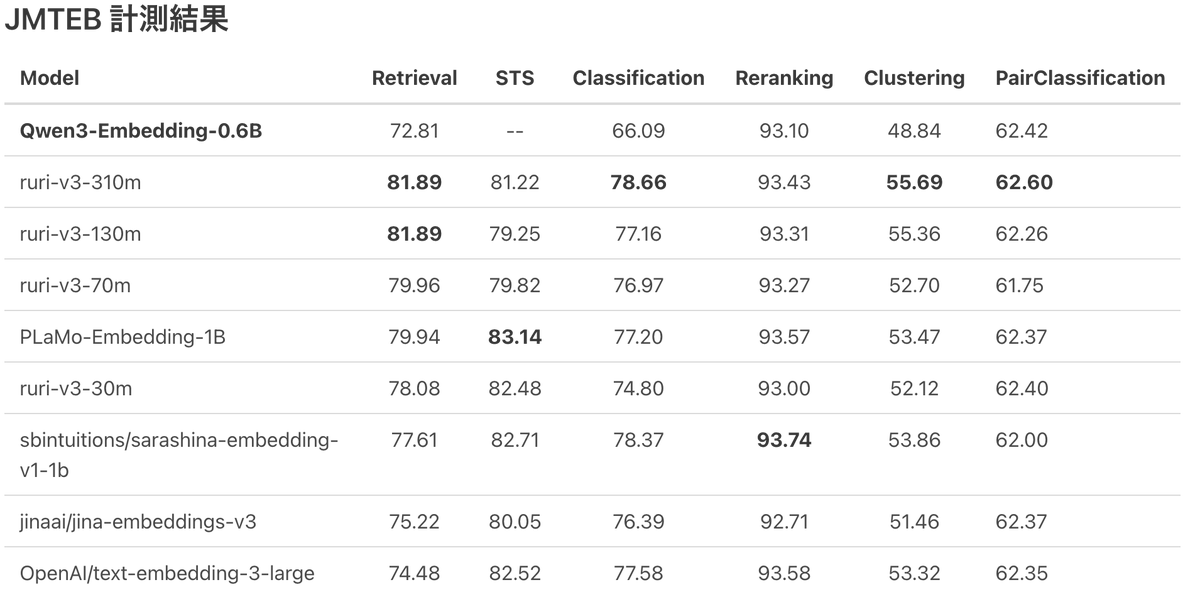
Qwen3 Embedding がリリースされたので、0.6B モデルの文章ベクトルの日本語性能をJMTEBで計測してみました。マルチリンガルモデルは日本語はあまり考慮されてないことがあるのですが、このモデルもそうなのか、日本語タスクにおいてはあまり性能が出ない結果に👀
secon.dev/entry/2025/06/…
日本語
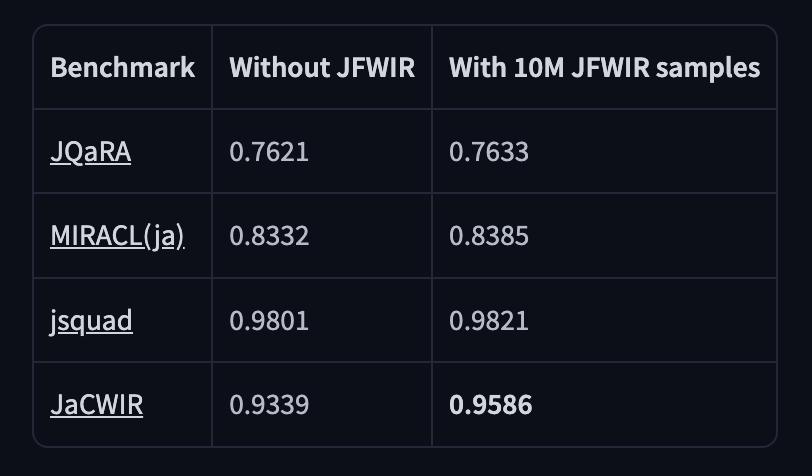
良質なWeb文章から生成した巨大な6400万件のquery, documentペアの情報検索用データセット(ハードネガティブもあるよ)もリリースしました🚀🚀🚀
このうち1000万件を追加しrerankerを学習させたところ、どのスコアも向上し、とりわけWeb文章の検索タスク(JaCWIR)で顕著でした!
secon.dev/entry/2025/06/…
日本語