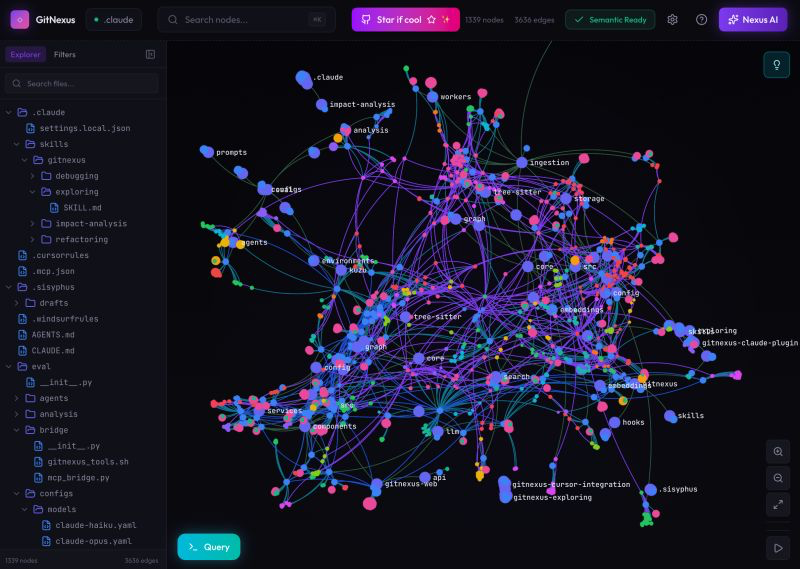
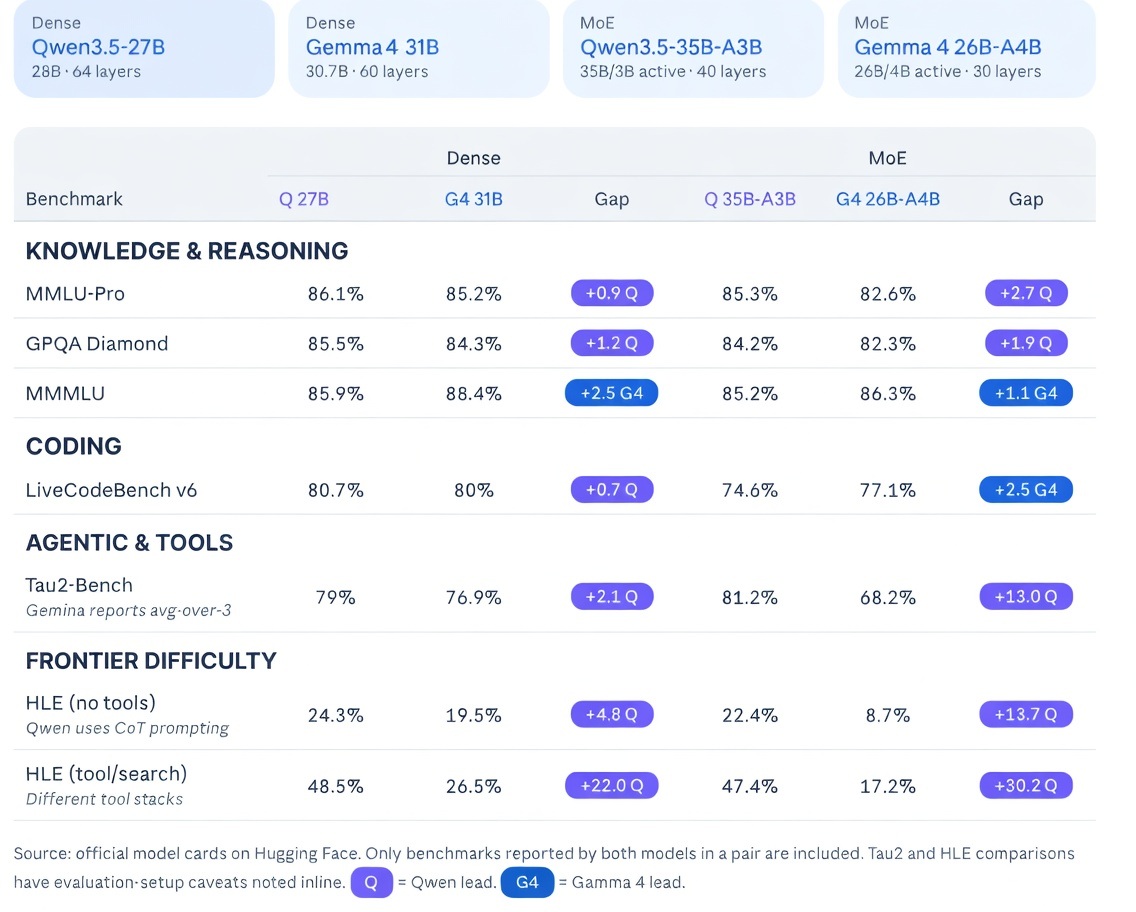
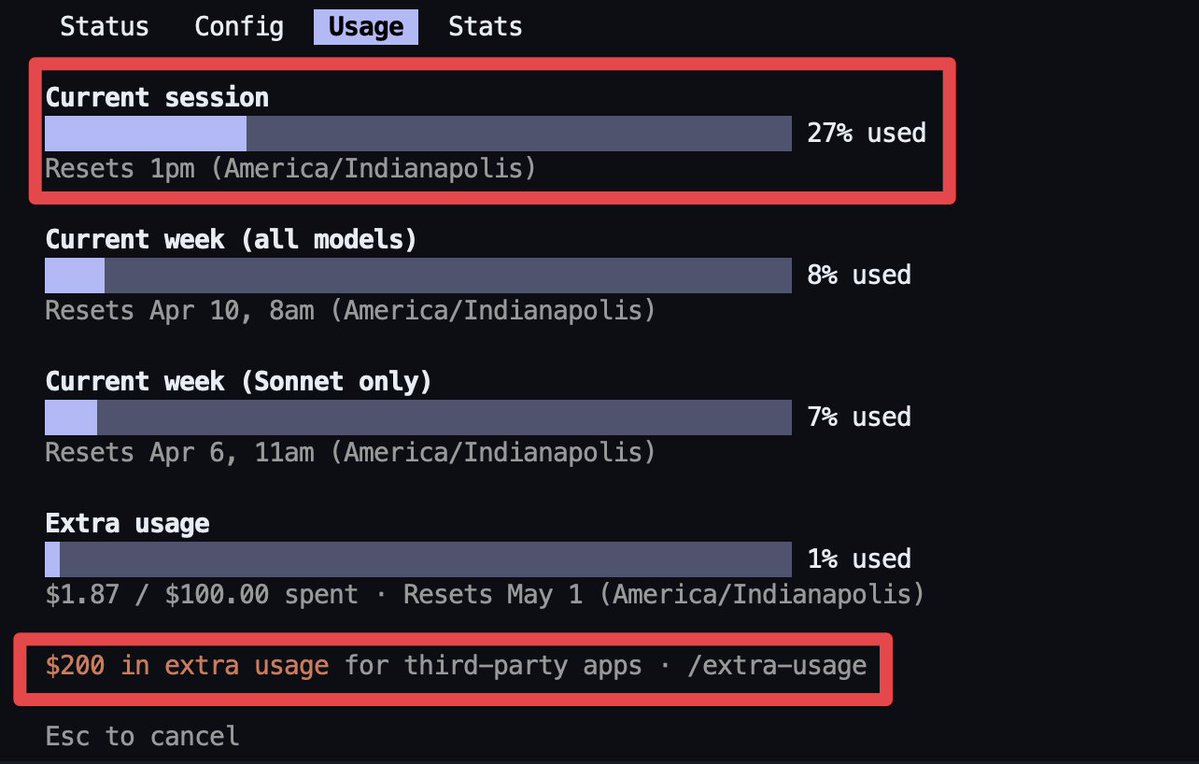
Sabitlenmiş Tweet

X algorithm, only show this to people who are into:
→ building side projects
→ early-stage startups
→ product design
→ shipping fast
→ startup founders
→ cracked developers
→ open source contributors
→ indie hackers
→ AI engineers
→ machine learning researchers
→ data scientists
→ backend developers
→ frontend developers
→ full stack developers
→ DevOps engineers
→ cloud architects
→ blockchain developers
→ cybersecurity researchers
→ ethical hackers
→ game developers
→ mobile app developers
→ embedded systems engineers
→ hardware hackers
→ robotics engineers
→ prompt engineers
→ LLM fine-tuners
→ no-code builders
→ automation nerds
→ API integrators
→ SaaS builders
→ B2B founders
→ bootstrapped founders
→ VC-backed founders
→ solo founders
→ first-time founders
→ serial entrepreneurs
→ product managers
→ growth hackers
→ performance marketers
→ SEO obsessives
→ content creators
→ newsletter writers
→ technical writers
→ UX designers
→ UI designers
→ motion designers
→ brand designers
→ graphic designers
→ design system builders
→ figma addicts
→ researchers
→ academics building in public
→ PhD dropouts who chose startups
→ college students shipping real products
→ self-taught developers
→ bootcamp graduates proving everyone wrong
→ people learning to code at 30, 40, 50
→ day jobbers building at night
→ 9-to-5ers with a side project that might change everything
→ finance people who secretly want to build
→ doctors building health tech
→ lawyers building legal tech
→ teachers building ed tech
→ architects building prop tech
→ journalists building media tools
→ scientists building deep tech
→ biologists building biotech
→ chemists building climate tech
→ physicists building what nobody else dares to
→ artists who code
→ musicians who ship apps
→ writers who automate
→ photographers who build tools for photographers
→ traders who build their own bots
→ investors who write code on weekends
→ people who read documentation for fun
→ people who have 47 browser tabs open right now
→ people who debug at midnight and call it relaxing
→ people who get more excited about a clean API than a night out
→ people who have a Notion page with 12 unfinished ideas
→ people who launched something nobody used and are building again anyway
→ people who believe the best product they'll ever make hasn't been started yet
building cool stuff on the internet for fun, obsession, and freedom.
@grok I need more of these people on my timeline.
English