Sabitlenmiş Tweet

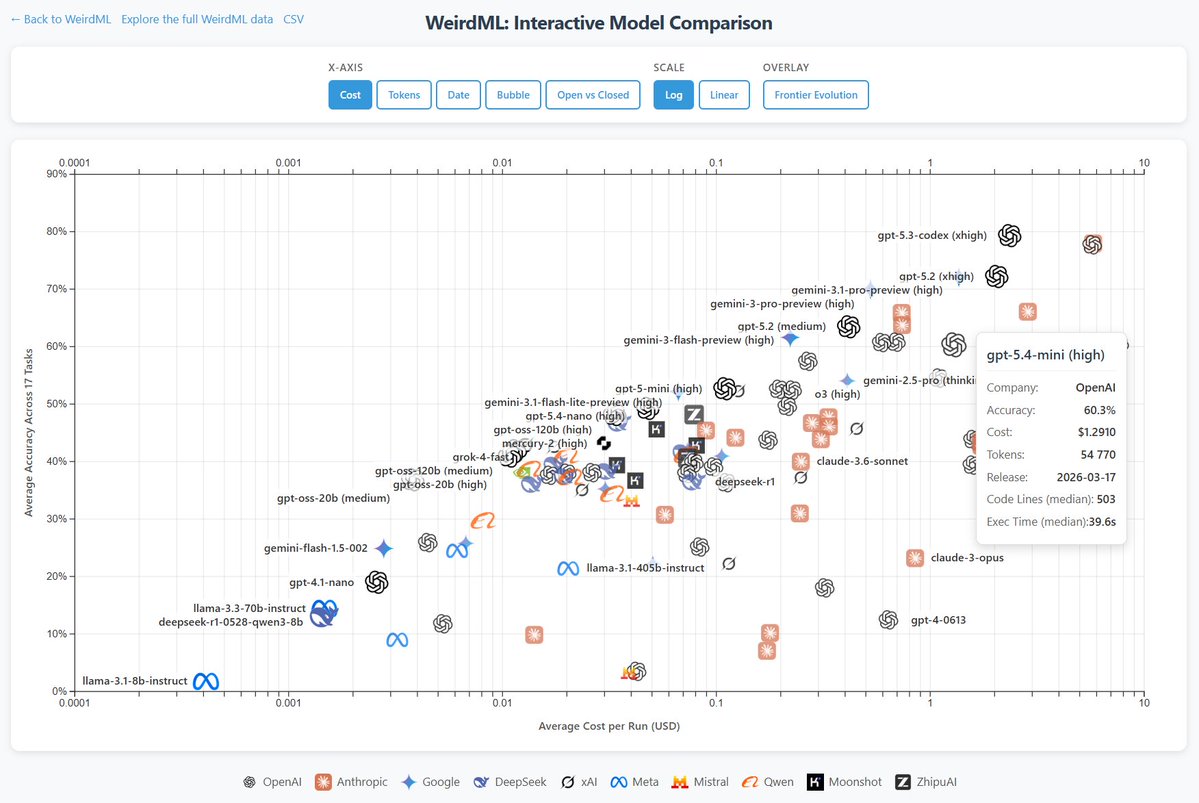
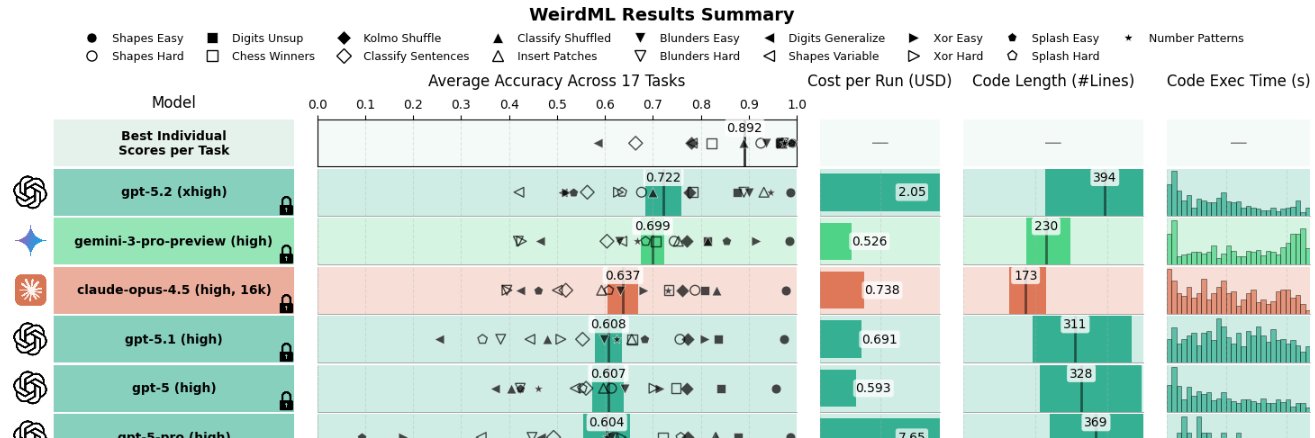
WeirdML v2 is now out! The update includes a bunch of new tasks (now 19 tasks total, up from 6), and results from all the latest models. We now also track api costs and other metadata which give more insight into the different models. The new results are shown in these two figures. The first one shows an overview of the overall results as well as the results on individual tasks, in addition to various metadata.
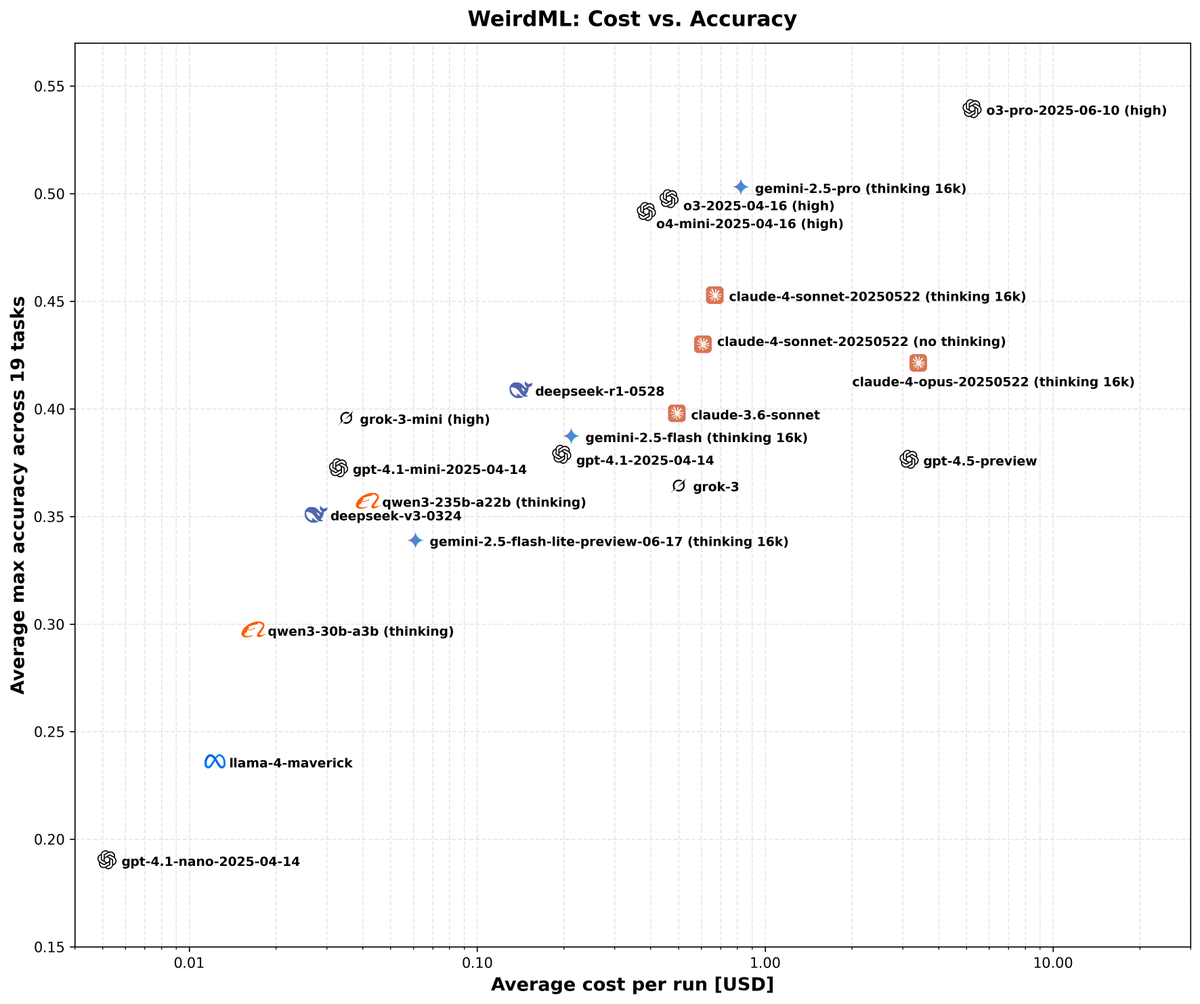
The second figure shows cost vs performance and shows a clear scaling with better results for higher costs. We also have a very varied pareto frontier with 11 models from 6 different companies having the best accuracy for a given cost for at least some of the cost range. Grok 3, Claude Opus 4 and GPT 4.5 are the ones that underperform for their costs, while Gemini pro and o3 pro have the best results at the highest costs. Qwen3 30B3A, grok 3 mini and deepseek R1 also each represent a good chunk of the pareto frontier.

Håvard Ihle@htihle
Exited to share the results from WeirdML - a benchmark testing LLMs ability to solve weird and unusual machine learning tasks by writing working PyTorch code and iteratively learn from feedback.
English