Dave Kwon retweetledi
Dave Kwon
12 posts

Dave Kwon
@iamdavekwon
Dev @ https://t.co/3Zizl82Jrv, building Wizard, the AI harness for our entire team 🇰🇷
Seoul, Republic of Korea Katılım Nisan 2026
35 Takip Edilen6 Takipçiler

Dave Kwon retweetledi

推荐两本 harness 的公开 pdf 书:《Harness Engineering:Claude Code 设计指南》和《Claude Code 和 Codex 的 Harness 设计哲学》,顺便聊聊 harness,Agent 在去年就人尽皆知了,与之相伴的 harness 为啥现在才冒出来?
我看 harness:note.mowen.cn/detail/bXvzs-t…
pdf 图书的原推:x.com/wquguru/status…
WquGuru🦀@wquguru
这两本书把Claude Code和Codex的Harness工程吃透了,对于Claude Code和Codex源码解析和对比都入木三分,文科生也能读的津津有味: 《Harness Engineering——Claude Code 设计指南》:不是源码注释汇编,也不是产品功能介绍。它关注的是 Claude Code 如何把不稳定模 型收束进可持续运行的工程秩序,让控制面、主循环、工具权限、上下文治理、恢复路 径、多代理验证与团队制度长成一套完整骨架 《Claude Code 和 Codex 的 Harness 设计哲学——殊途同归,还是各表一枝》:比较两套 AI coding harness,最容易犯的错误,是拿一张功能对照表当作思想史。左边写“有技能”,右边也写“有技能”;左边写“有沙箱”,右边也写“有沙箱”;左边写“能开子代理”,右边也写“能开子代理”。这样写的好处是省事,坏处是几乎什么也没说。因为工具中的名词相同,不代表系统的骨架相同。就像两个城市都修了桥,不能说明它们是按同一条河设计的。 Github仓库:github.com/wquguru/harnes… 在线阅读:harness-books.agentway.dev/index.html
中文
Dave Kwon retweetledi

THE 1-HOUR OBSIDIAN LECTURE THAT CHANGES HOW YOU THINK ABOUT YOUR VAULT
> Nick Milo breaks down Obsidian Bases
> the feature that finally makes Obsidian a real database, not just a folder of markdown files
> save this. watch it before you set up your vault👇
Mr. Buzzoni@polydao
English
Dave Kwon retweetledi

The clearest explanation of Claude Managed Agents you'll find.
Everyone's talking about it. Nobody's explaining it well.
In 12 minutes we cover:
- What it actually is (platform as a service for AI agents)
- Who it's for and who should avoid it (4 personas)
- Live console walkthrough (sessions, analytics, costs)
- Real cost breakdown ($2.58 to fulfill a $1,000 service)
We also built a free Google Doc that deploys your first managed agent when you hand it to Claude Code.
You can grab it in the podcast show notes (Build With AI podcast) or YouTube description (video link below).
Corey Ganim@coreyganim
English
Dave Kwon retweetledi

This 16-minute talk by two Anthropic engineers who built Claude Skills will teach
you more about building them right than most developers figure out on their own in months.
Bookmark this & watch, no matter what.
Then read the guide below by @eng_khairallah1
Khairallah AL-Awady@eng_khairallah1
English
Every time I open X these days, it’s just Karpathy’s LLM Knowledge Base wiki dominating the timeline.
Close the app, reopen… still there.
At this point I’m half-tempted to file a FOIA request titled “Anthropic Payroll Shenanigans”.
Meanwhile in Anthropic Slack, 3:42pm:
PM: Andrej… token usage looking a little quiet this quarter
Karpathy: Say less.
Drops a 127k-word personal knowledge base that single-handedly melts every builder’s context window and resets the entire TL.
New quarterly Karpathy arc just dropped — courtesy of Anthropic’s token throughput department.
(meanwhile my org knowledge graph is quietly compiling itself in the background like a good little agent…)
English
Update on the org knowledge graph I posted about earlier —
Switched from the Neo4j graph approach to an LLM Wiki pattern (inspired by @karpathy). The difference is fundamental: instead of extracting isolated fact-nodes into a graph DB, the LLM now incrementally maintains wiki pages — reading, updating, cross-referencing, noting contradictions. Knowledge compounds instead of fragmenting.
The bigger shift: moved the whole thing onto Claude Code's remote scheduler. My Max plan runs a scheduled agent that crawls one 7-day window per run, starting from company founding.
The part I'm most excited about — the system evolves itself through three files:
**PROMPT.md** — The agent's instruction set. But here's the thing: the agent can rewrite it. If it discovers that a proxy endpoint needs different parameters, or that a directory convention should change, it updates its own instructions. Long-term behavioral evolution.
**handoffs/*.md** — One file per completed run. Each handoff teaches the next run: "Slack workspace was created Dec 27, so don't bother searching before that." "PR bodies are empty before 2020, rely on titles." "KANBAN format is MPKAN-####." The agent discovered all of this on its own and recorded it. Short-term accumulated memory.
**REPORT_LOG.md** — The only file meant for me. A human-readable log of what each run did, what it found interesting, and what needs my attention.
The loop:
1. Agent reads HANDOFF.md (learn from predecessors)
2. Collects from Slack/GitHub/Notion via proxy API
3. Updates wiki pages (knowledge/)
4. Writes new handoff (teach successor)
5. Optionally rewrites PROMPT.md (evolve behavior)
6. Commits → GitHub Action re-triggers → next window
After a few runs from the company founding, it built 100 wiki pages covering core services, products, infra, and team processes — all autonomously. Each run gets smarter than the last because it reads what previous runs learned.
~380 weeks to process until present. The system will literally teach itself the entire company history, one week at a time, getting better at it as it goes.


English
I get the business rationale, but where exactly is the line? Agent SDK? CLI runtimes? Local dev? Please just publish clear guidelines before rolling out policy changes.
Boris Cherny@bcherny
Starting tomorrow at 12pm PT, Claude subscriptions will no longer cover usage on third-party tools like OpenClaw. You can still use these tools with your Claude login via extra usage bundles (now available at a discount), or with a Claude API key.
English
Inspired by @karpathy's LM Knowledge Bases — I'm building something similar, but for an entire company.
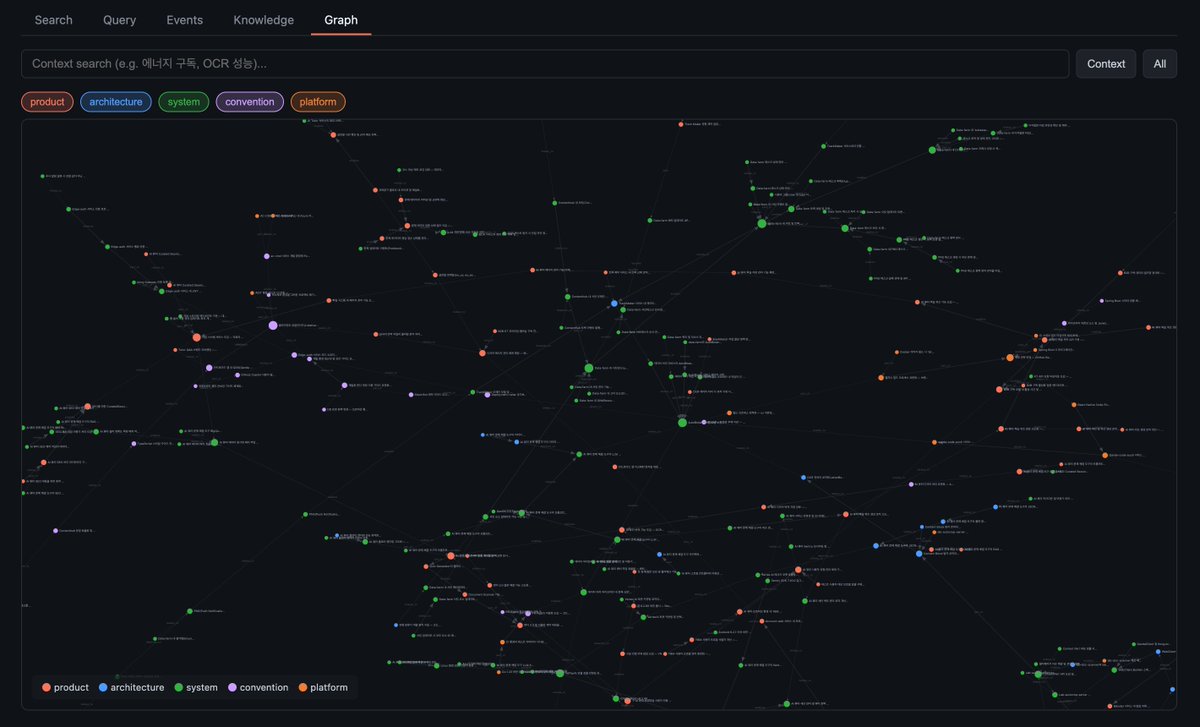
Taking 10 years of organizational context at our company and compiling it into a shared knowledge graph that plugs into our existing AI workflows.
Pipeline: GitHub + Notion + Slack + ... (N channels) → raw event store → LLM extraction → Neo4j graph DB
The extraction LLM (gemini-3-flash-lite) isn't the smartest, but it's cheap — so inspired by @karpathy's auto-research approach, I run auto prompt-enhancing iterations: reset → promote → evaluate → tweak prompt → repeat until the graph quality is satisfactory.
From zero to working system: 1hr connecting data sources, 1hr infra + code, then karpathy iteration.
The loop: Integrated into our existing workflows via MCP. Every communication channel feeds the graph, and the graph feeds back into every workflow. Knowledge compounds automatically.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Started this account to share what I'm building at @team_qanda
I've been watching an explosion of AI workflows that help with dev, design, and planning. They're great for building something new from scratch — spin up a product, ship it, test it.
But I kept hitting the same wall: when multiple people need to work together, with existing company infra and institutional knowledge, producing output that satisfies everyone — these workflows fall short.
So I've been focused on building a harness that lets engineers, SREs, designers, PMs, marketers, and managers all produce fast, consistent output through AI workflows — grounded in the org's actual context.
Will be sharing my thinking and building process here. Open to networking with anyone working on similar problems or just curious about enterprise AI workflows.
Let's connect 🤝
English