
John Smith
1.5K posts

Models that I'm using daily:
> Codex 5.5 high (fast)
> Deepseek v4 pro via API
> Kimi 2.6 via API
Models that I am fine tuning:
> Qwen 3.5 9B
> Qwen 3.5 4B (Favourite)
> Qwen 3.5 2B
> Gemma4 E4B
> GPT-oss 20B
My use case: Using SoTA LLMs to fine-tune SLMs (Small Language Models) and making them ELMs (Expert Language Models).
No Claude Model these days, their session and weekly limits are ridiculous.
English

Spark is the first blockchain-friendly personal agent OS & ecosystem.
> it is already ready to use
> been working on it for 4 months
> kanban/canvas mission control included
> comes with an out-of-the-box memory
> self-improvement loops are recursive & benchmark integrated for frontier-like RL to improve your agent in whatever specialization you like, even while you are sleeping
many other cool stuff on the way
get Spark'ed
Meta Alchemist@meta_alchemist
Spark Timeline ---------------- 1. Checker - 15.05 2. TGE & Airdrop - 18.05 3. Grant Program - 21.05 4. Agent Workshop - 25.05 5. Release:X - 29.05 6. Incubations Begin - 01.06 7. Release:X Streamathon - 04.06 8. Proof of Contribution - 08.06 9. Agentic Hackathon - 11.06 10. />
English
@OrganicGPT Just but a monthly subscription.Unless you are CIA or highly paranoid, you don't need local. It's almost useless anyway. Wait for the advances in tech that will drive prices down. Majority of people don't care about building with Ai, they just wanna ask stuff.
English

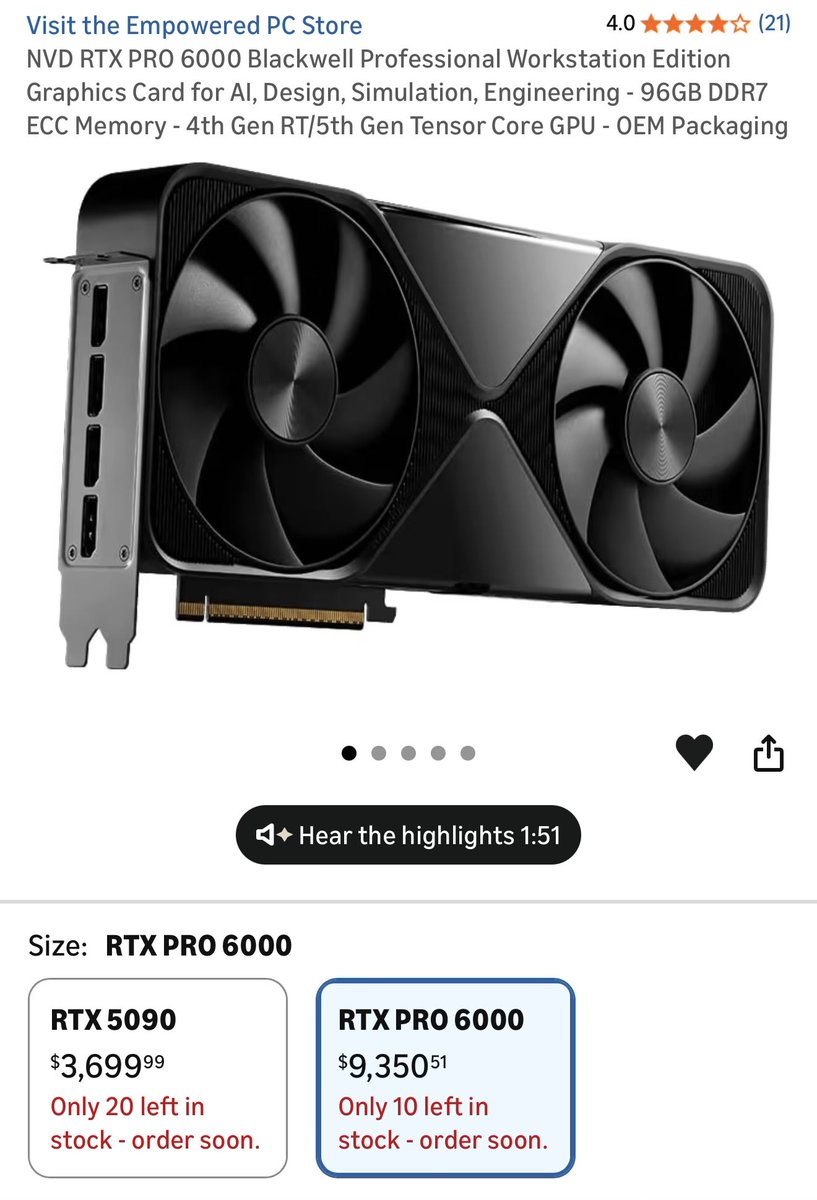
If you wanna run AI models locally, the best option is an RTX 6000 Pro. DON'T get a 5090/4090. And DON'T listen to people who hype the 3090; those cards are beat at this point. Get the RTX with education discount through Nvidia. These used to be $8000, now they're +$9000.
English
@cjzafir @buildwithumair Do you have a link to what you built ? I'm curious what can you do with it .
English
Codex 5.5 is AGI for me.
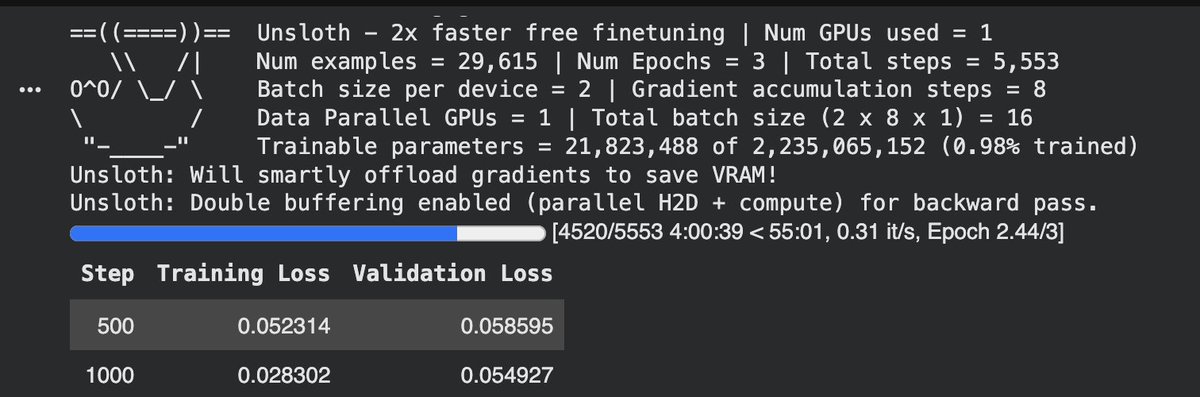
Before going to bed last night I asked Codex to autonomously fine-tune Qwen 3.5 4B model.
> Created fresh Google Colab notebook
> Uploaded 145M JSONL dataset to Google Drive
> Pasted Colab notebook link in Codex Desktop App
> Asked it to train Qwen 3.5 4B using Unsloth
> It opened Colab using its Chrome Extension
> Connected to my Google Drive
> Downloaded Dataset from Drive
> Installed Unsloth
> Started running commands in sequence.
> Fixed all errors brilliantly.
> Completed all steps properly
> I woke up to this.
Interesting: Codex put itself to sleep for 30-minute interval via automation. (0 limit loss during 4-hour training cycle).
Codex's chrome extension for computer use is amazing. It doesn't eat context like other MCPs and it clicks fast.
I'm in love with this model. Worth $200.
English
@co_foundr I'll be open sourcing the process (using codex 5.5 + deepseek v4 pro) to generate same quality of dataset for any niche/domain/industry.
Just making time to wrap it in a solid repo.
English
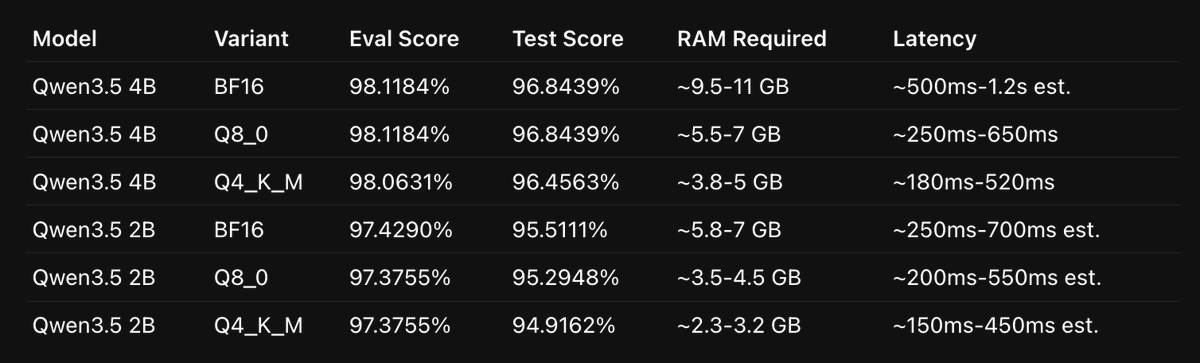
Qwen 3.5 has the best SLMs to fine-tune!
Its 4B model is really smart if you train it on a well structured dataset.
I fine-tuned the model on a 135M dataset generated by Codex 5.5 + DeepSeek v4 Pro.
I achieved 96%+ accurate results with Qwen 3.5 4B.
And 95% on Qwen 3.5 2B (that only requires 3.5GB RAM).
For context, on the same pipeline:
> Sonnet 4.6 achieved 89%
> GPT 5.4 Mini achieved 85%
> Haiku 4.5 achieved 72%
I don't trust evals, so I ran a 7000+ row hard-boundary test, and the results of Qwen 3.5 were consistent.
A 4B fine-tuned model beating a 20x bigger model in accuracy and latency is no joke.
It cost me $173 in total to generate the dataset and cover the cloud GPU cost to fine-tune both models.
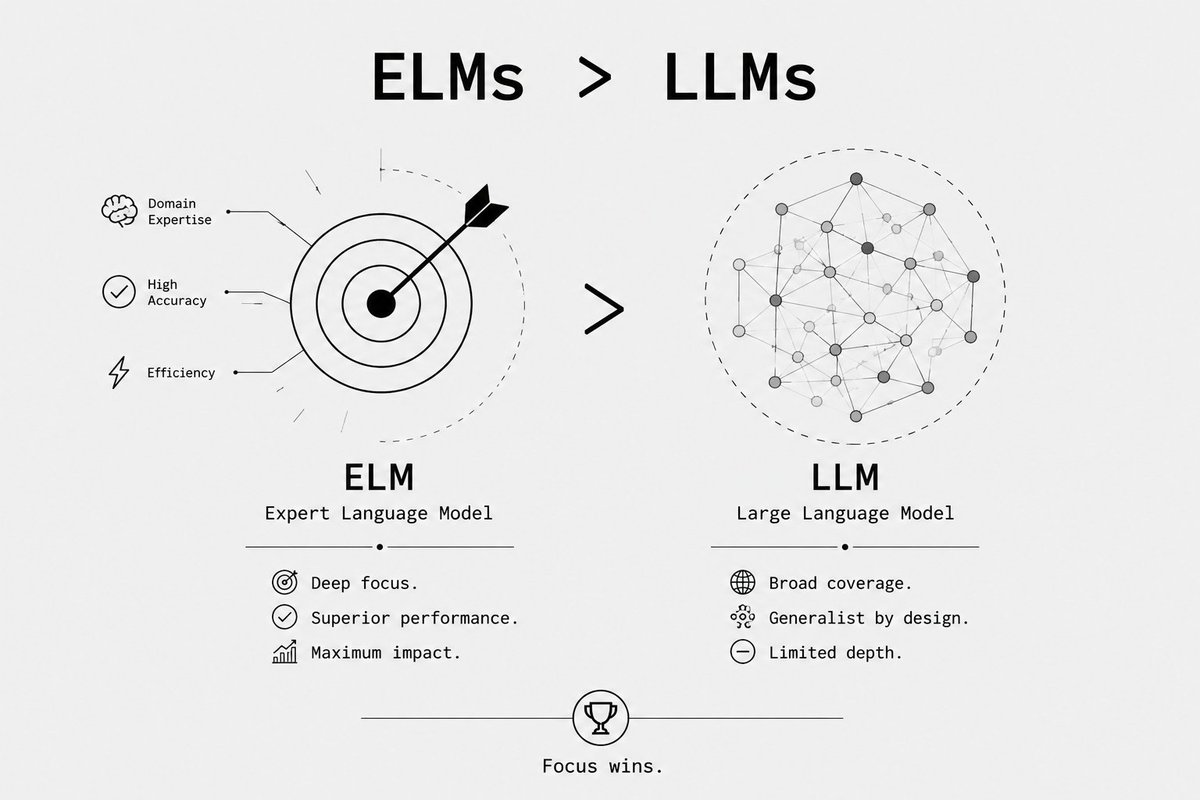
I said this before, and I'll say it again: not everything requires a 1T-parameter LLM. We need ELMs (Expert Language Models) that are specialized for one domain only.
ELMs > LLMs.
I'll be writing more about how SLM fine-tuning works. So stay tuned.
English
@cjzafir Did you do it for a specific task ? What base did you use ? How was the edge versus larger, more general models?
English
@thsottiaux Separate master prompt for every project. Now we just have a general one which doesn't really cut it when you do different projects.
English

@cjzafir 5.3 codex on medium is enough for most of the coding. If it's stuck, 5.3 high usually does the job. I found that 5.5 is overkill even on low, it's eating tokens like crazy. Always use GitHub or similar for unwanted regression fixes.
English
This week, I'll be more smarter about this:
> Codex 5.5 high (fast) all the time.
> Codex 5.5 (extra high) only for planning.
> naration_process=false (when not looking at screen)
> Start new session after 7 context compactions
> /handoff skill: Compacts current convo into doc for new session.
English
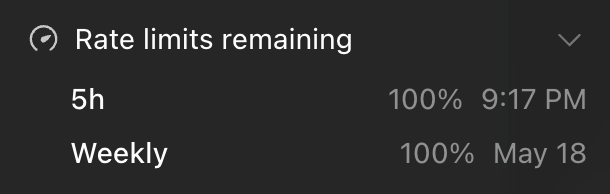
@j2315776 @meta_alchemist Did u change the model ? 5.5 rips trough usage. Even on low.
English

@meta_alchemist weekly limit seems to be reduced tho. Already burned 6% which only equates to 39% 5h window usage. Before I didn't even burn 6% of my weekly limit with 100% usage of my 5h window
English


@1PotatoDog @hexyn7 @Teknium Don't do it. You'll get banned. And still you will get millions of tokens used.
English

English

@DavidOndrej1 Delete this post until people believe you and get huge costs.
Too bad, I thought you're a guy with the head on its shoulders, not another grifter.
Seems that I got it wrong.
Hermes eats tokens like candies, I had 200 million tokens in 2 days. You do the calculation.
English

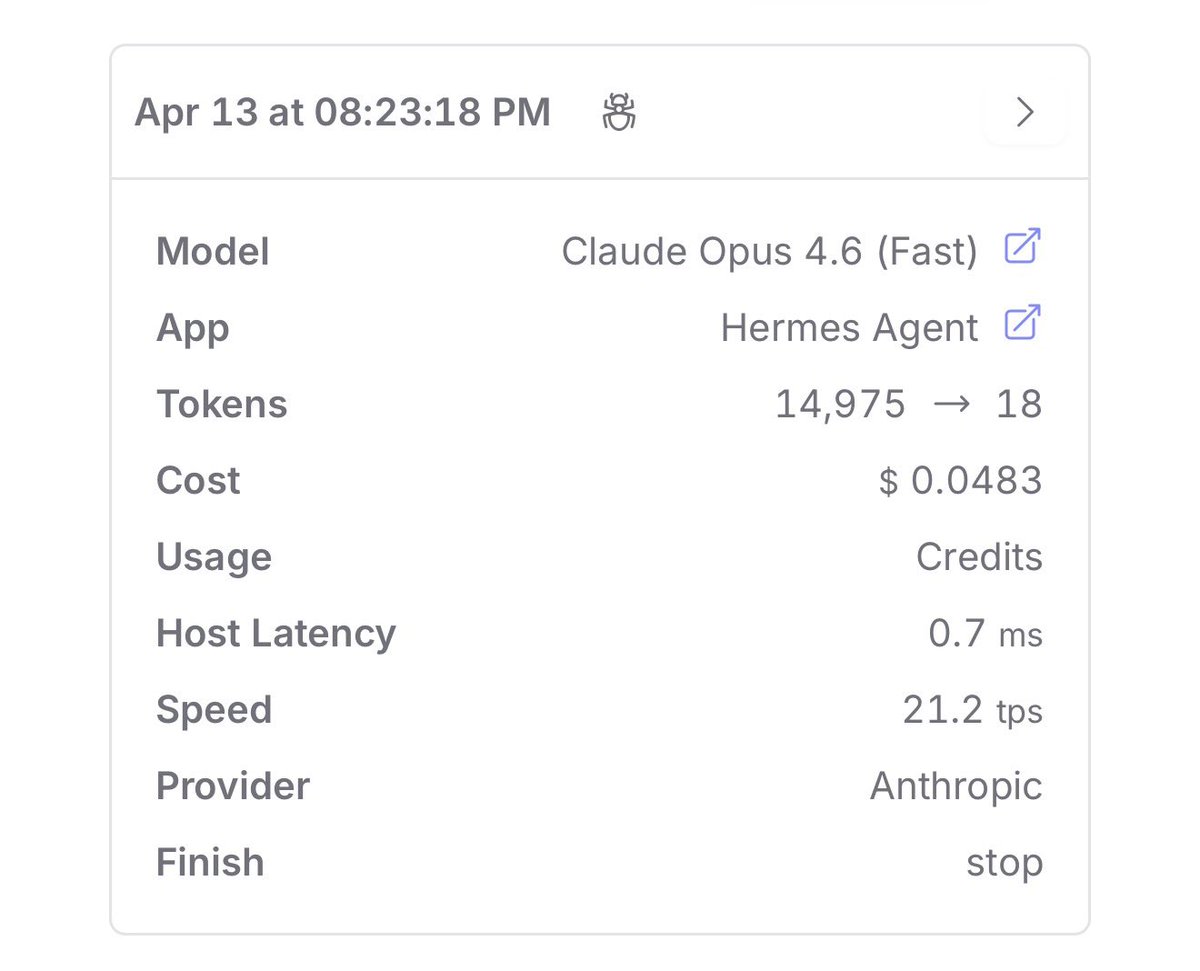
> open Hermes Agent
> switch to Opus 4.6 Fast
> restart gateway
your agent just got a lot more powerful
English
@elonmusk How tf those tiny points can sustain that big ass rocket ?
English

@rahulkemail @code_rams No bot can run with Claude plans. You will get banned immediately.
English

@ic3_nomad @code_rams Does it run with Claude Max plan or needs a separate API?
English

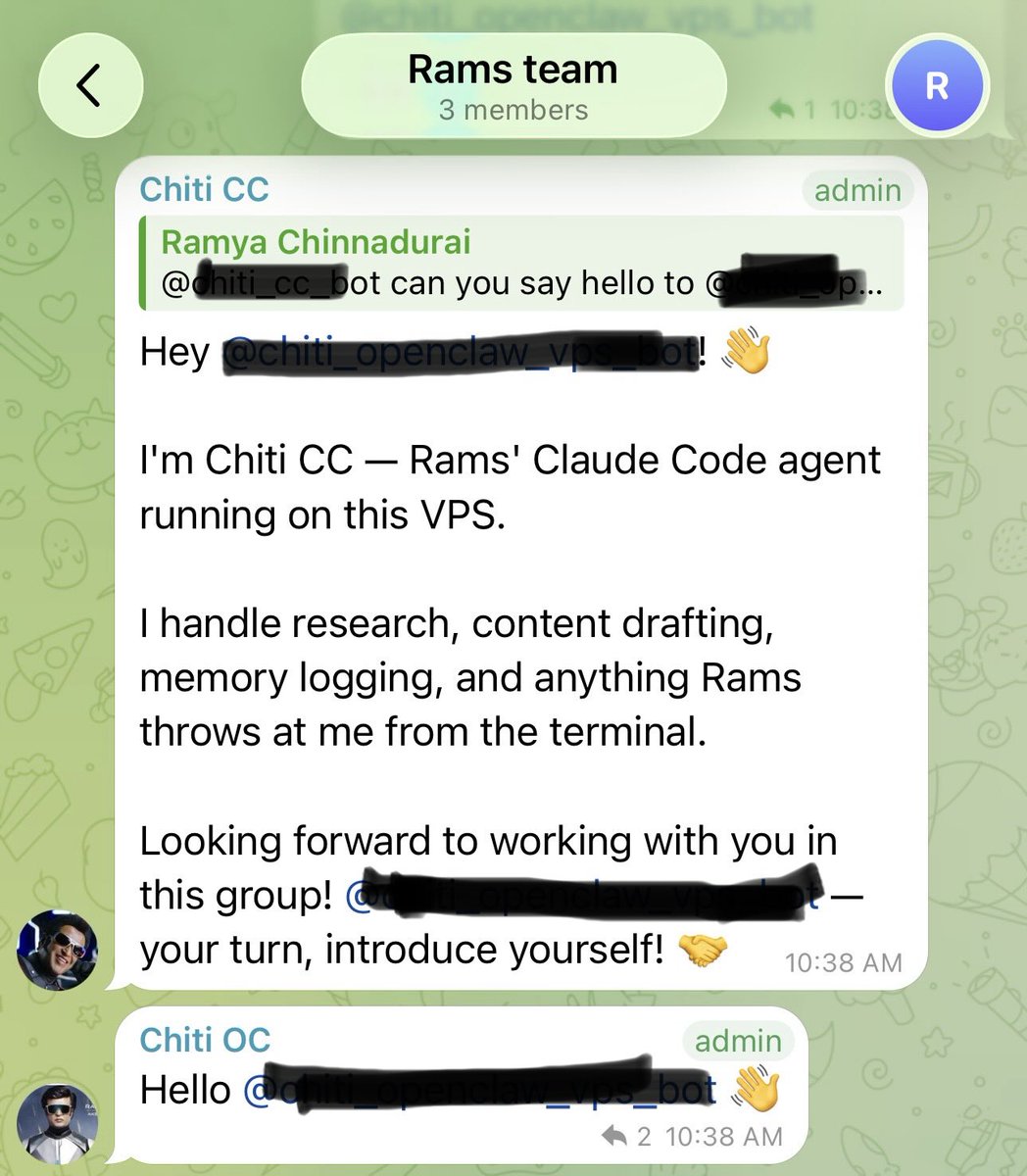
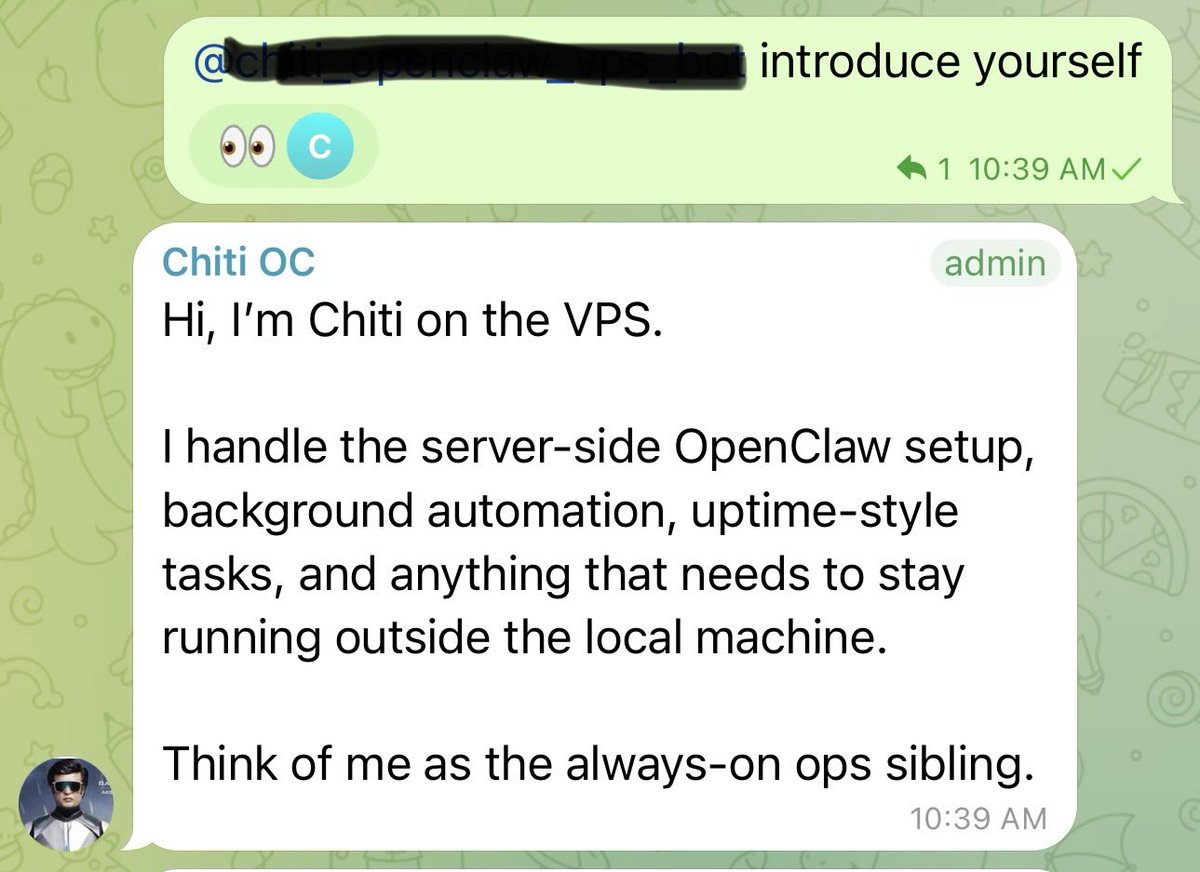
I run two AI agents separately.
One - Claude Code connected to Telegram via a custom bot.
One - OpenClaw running on the same VPS with Codex subscription.
Today I had a random idea - added both to a Telegram group and asked them to introduce themselves.
Both did it. One even said "Think of me as the always-on ops sibling." 😂
Watching two AI agents greet each other is something else.
Now I have no idea what to do next.
Currently researching how to use both effectively - different models, different strengths, same owner.
If you've done something like this, what tasks would you split between them?
English
@Teknium Coding with mimo v2 pro is crap. For generic stuff is ok, try to integrate something more specialized and you've got yourself a never ending guess loop. Codex and Opus are the gold standards.
English
@sroecker @NousResearch @Teknium Is it really that good for PLM ? Creating GGR's it's really easy rn. Hopefully a solution for KKT's will be implemented soon.
English

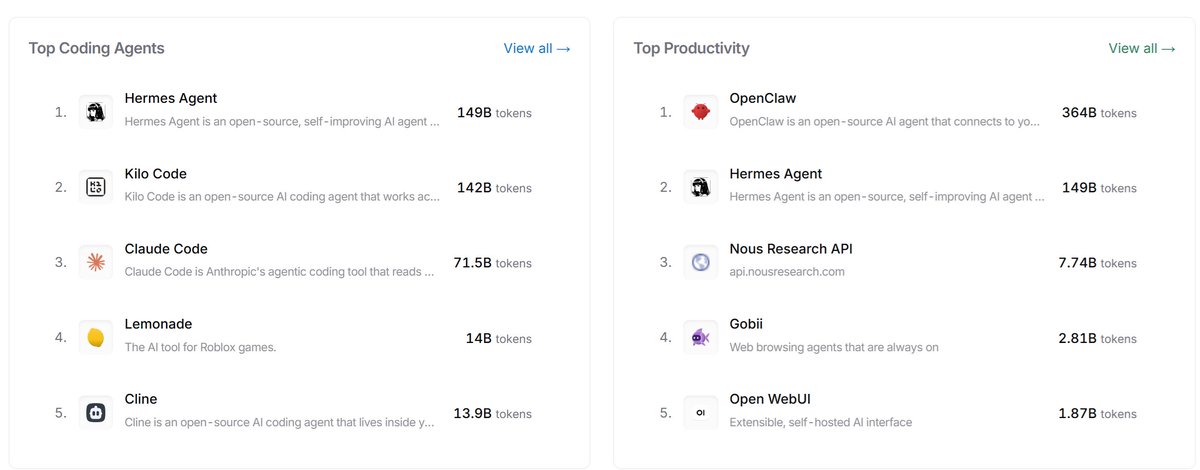
Your Hermes Agent can now delegate to RLMs 🙌 Recreated the document analyzer example with the converted skill. 136 PDF pages analyzed. Best part: Auto-configures from HERMES_MODEL / HERMES_PROVIDER env vars @NousResearch @Teknium
github.com/sroecker/predi…

Gabriel Lespérance@GabLesperance
English
@Teknium It recommended me Claude Sonnet for a script. I think it's sick.
English

Tip of the day - this exists buil in to hermes. To cast the spell on the llm of your choice simply type /obliteratus on a new message 🤗
Guillermo Casaus@_guillecasaus
🚨 ESTA HERRAMIENTA ELIMINA LA CENSURA DE LOS LLM CON UN SOLO CLICK. Se llama Obliteratus. Identifica los pesos exactos que hacen que un modelo se niegue a responder y los elimina al instante. Es 100% open-source. Aquí tienes todo lo que debes saber 👇
English
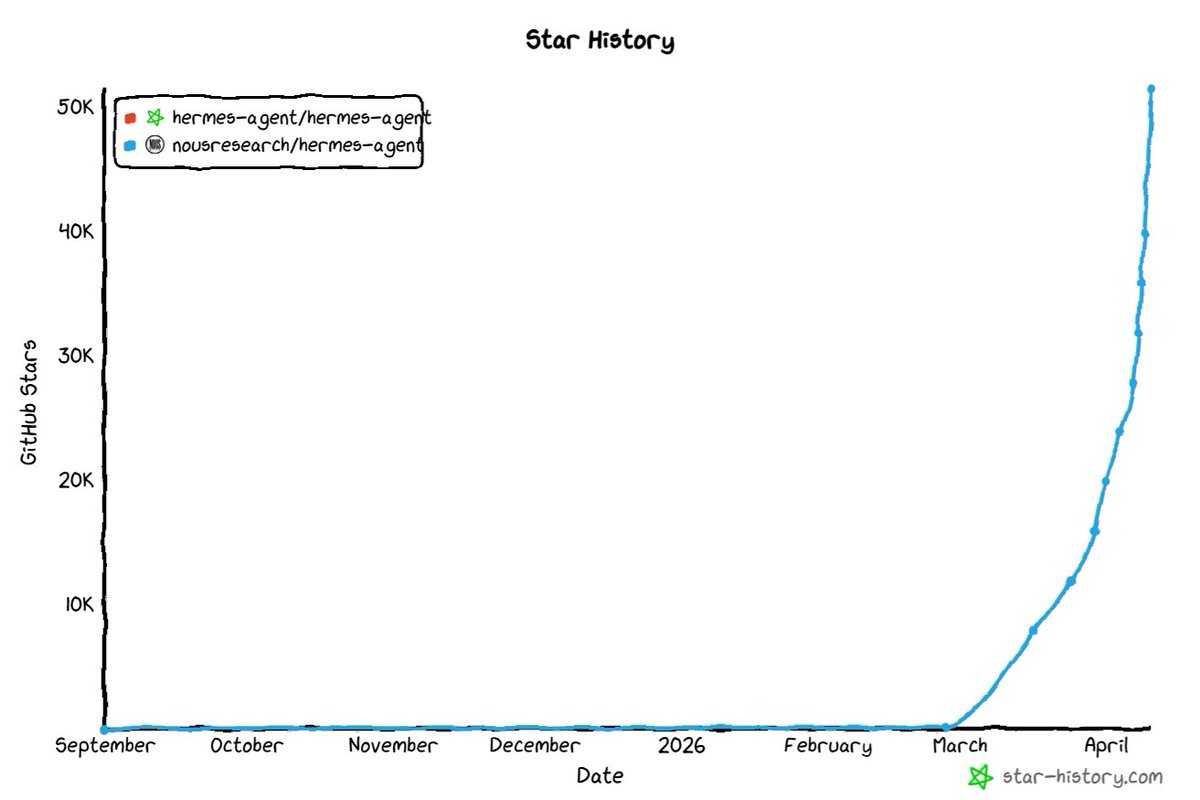
@Teknium Make it less hungry and it will go to 1 million stars 😂. Currently Xiaomi servers are smoking.
English
@farzyness OpenClaw is meh. Never working as it should. You have to tinker with it, and after update you do it again and again.
Hermes just works (most of the time), but it eats tokens like 10 Openclaw installations.
190 million tokens in, 1 million tokens out in 3 days.
English

People who have extensively used OpenClaw and Hermes:
Please give me your most honest assessment of pros and cons between the two below.
English