Christos retweetledi

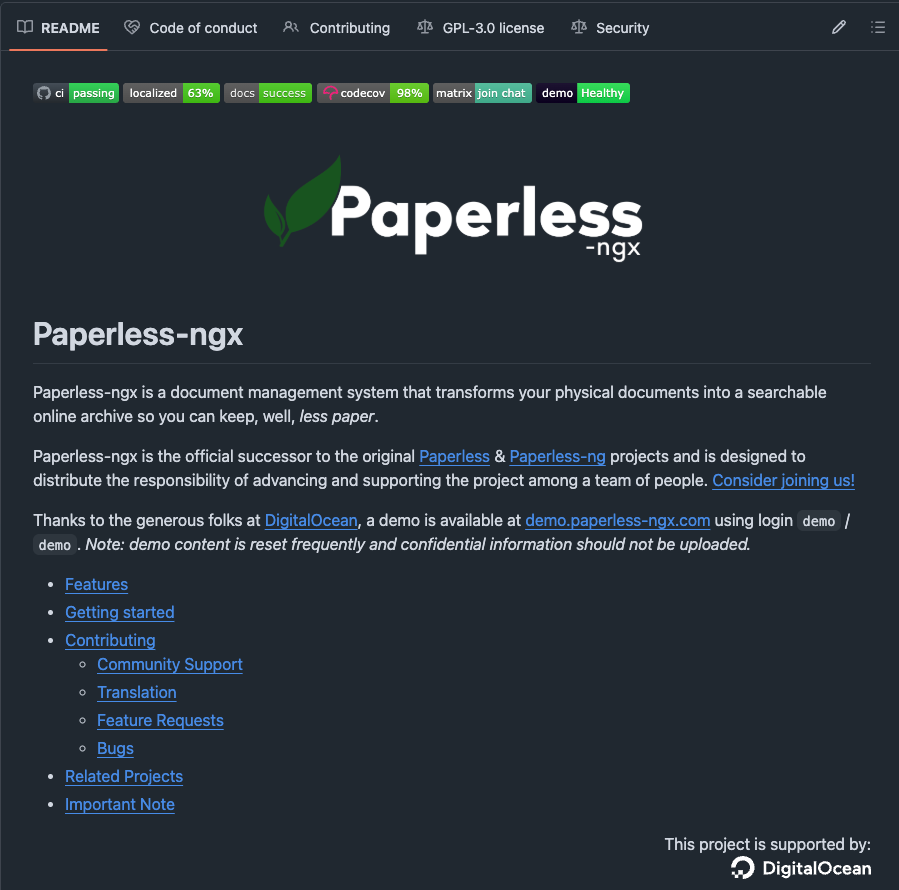
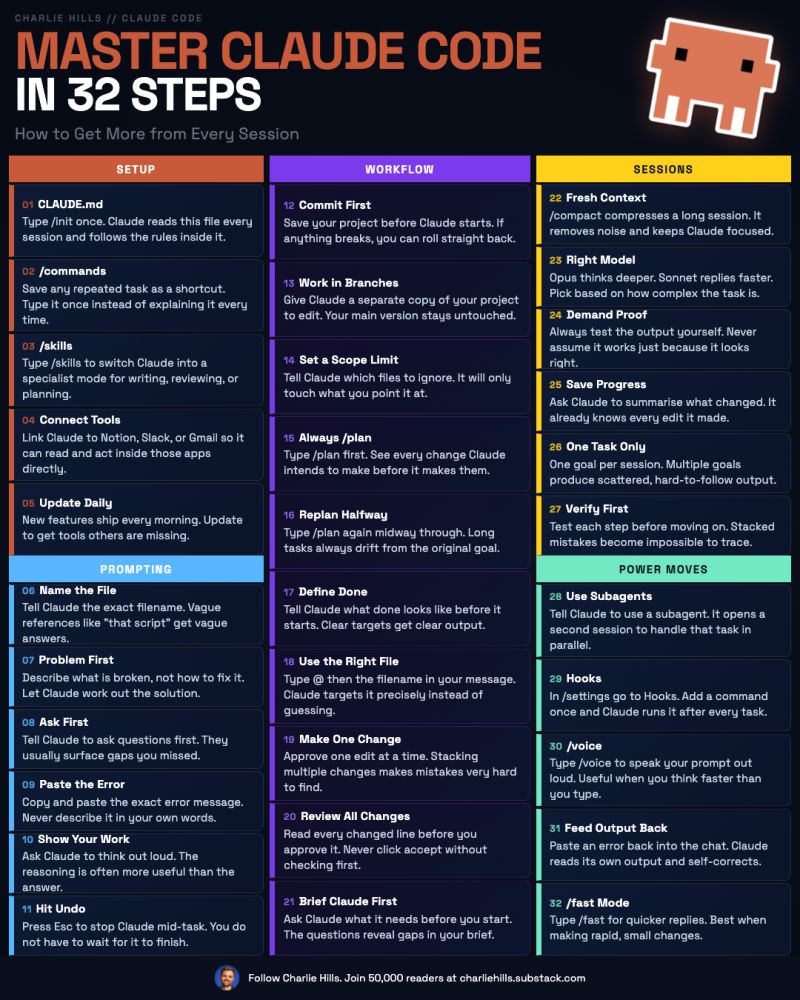
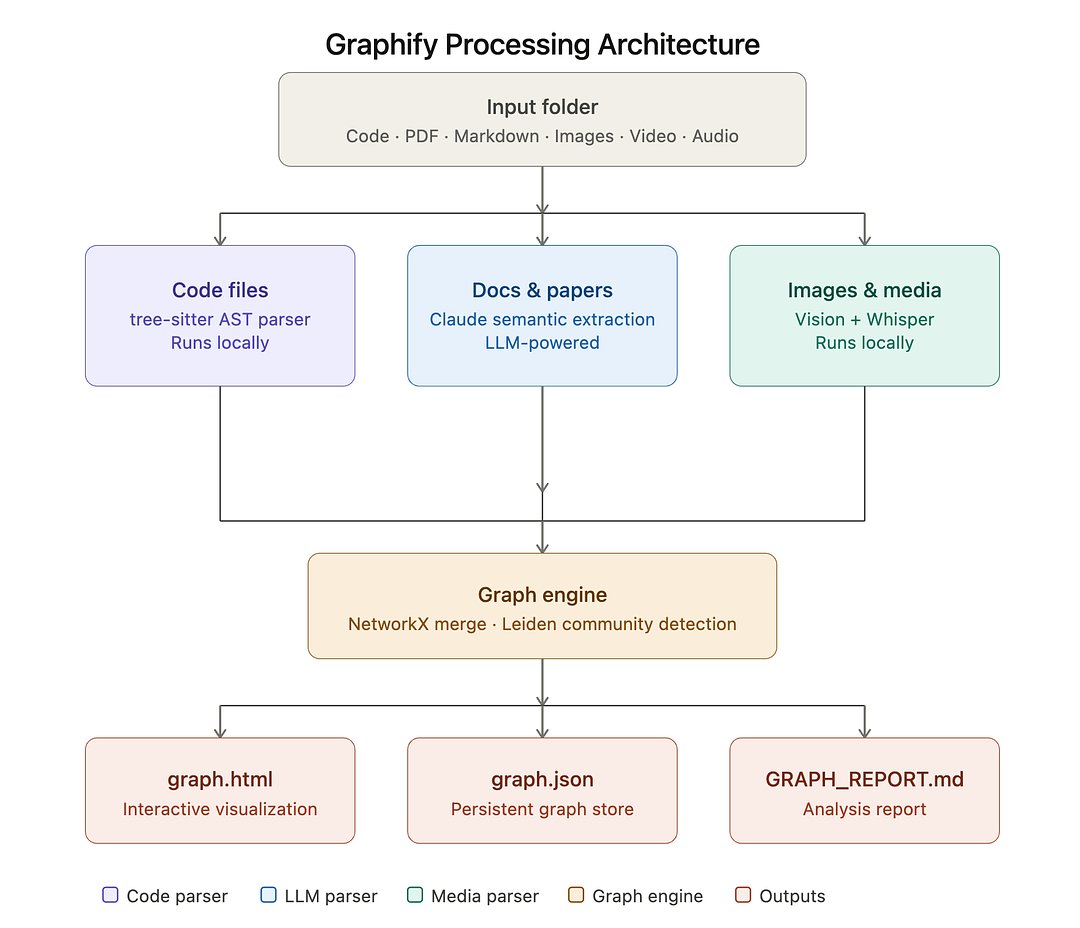
A 100-page book written by an MIT professor in 2006 has been translated into 14 languages and quietly become the rulebook that designers at Apple, Google, and Airbnb still reference today.
His name is John Maeda, and before he wrote it he spent 12 years at the MIT Media Lab trying to figure out why the products that get loved are almost never the products with the most features.
The book is called The Laws of Simplicity. The following year, he walked onto the TED stage and compressed the entire thing into few minutes. That talk has been played over million times and is still passed around every time a design team gets into a fight about what to cut.
Here is the framework inside it that changed how I think about every product I touch.
Maeda's first law is Reduce, and it is the one everyone thinks they already understand. They don't.
He argues that the simplest way to achieve simplicity is through thoughtful reduction, but the word that matters in that sentence is thoughtful. Removing the wrong things makes a product feel broken. Removing the right things makes it feel magical. The difference is not taste. It is a method.
The method he teaches is an acronym he calls SHE (Shrink. Hide. Embody).
Shrink means making the product feel smaller, lighter, and more humble than it actually is, because when a small unassuming object exceeds expectations, the brain registers it as delight. The iPod's mirrored back was not a finish decision, it was a shrinking trick. The reflection made the device blend into its surroundings so the eye only registered the thin plastic front. You felt like you were holding something impossibly thin because half of it was optically erased.
Hide means taking the complexity that cannot be removed and putting it somewhere the user will never see it unless they go looking. The Swiss Army knife is the oldest version of this idea. A cell phone's clamshell was the modern one. Today it is every settings menu buried three taps deep in every app on your phone. The complexity is still there. The user just never has to carry it.
Embody is the one that almost nobody applies correctly. Maeda argues that once you shrink and hide, you create a vacuum where the user starts to wonder whether the smaller, simpler thing is actually worth more than the bigger, feature-rich thing. So you have to put the lost value back in through materials, weight, craftsmanship, or story. The Bang and Olufsen remote control is intentionally made heavier than it needs to be because weight in the hand signals quality. The same remote in plastic would feel cheap. Same functions. Completely different product.
The deepest insight in the talk is the one Maeda buries near the end, and almost nobody quotes it back.
He says simplicity is not a feature you bolt on. It is a consequence of being willing to defend fewer things more fiercely than your competitors are willing to defend more things. Every product eventually faces a moment where adding one more feature feels harmless and subtracting one feels expensive, and the companies that win that moment are the ones that understand the cost of adding is almost always higher than the cost of cutting.
His final law is the one he calls The One. Simplicity is about subtracting the obvious and adding the meaningful.
Read that sentence twice. It is the entire design philosophy of every product you currently love, compressed into a single line.
Maeda grew up working 3am shifts in his father's tofu factory in Seattle before MIT, before RISD, before Kleiner Perkins, before Microsoft.
He has said more than once that what he learned in that factory shaped everything he wrote in that book. Craftsmanship is not about doing more. It is about doing the right things and refusing to do anything else.
The book is 100 pages.
Read it and learn the laws of simplicity.

English