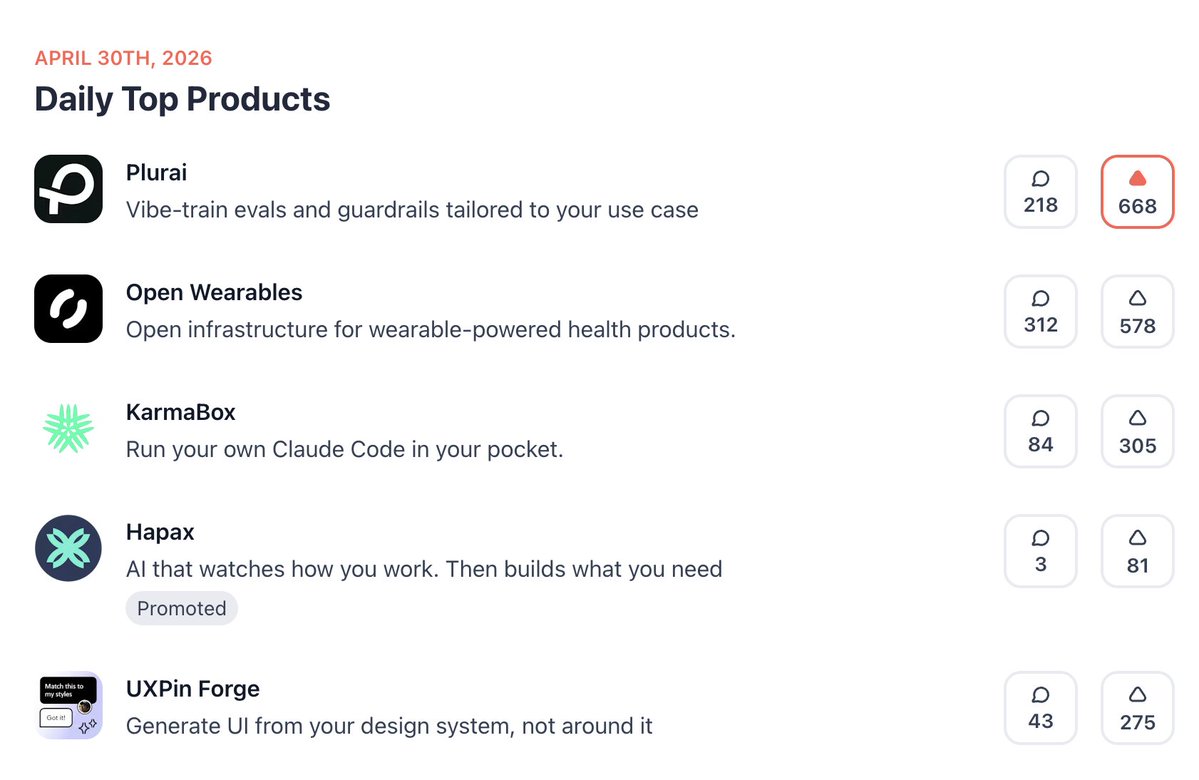
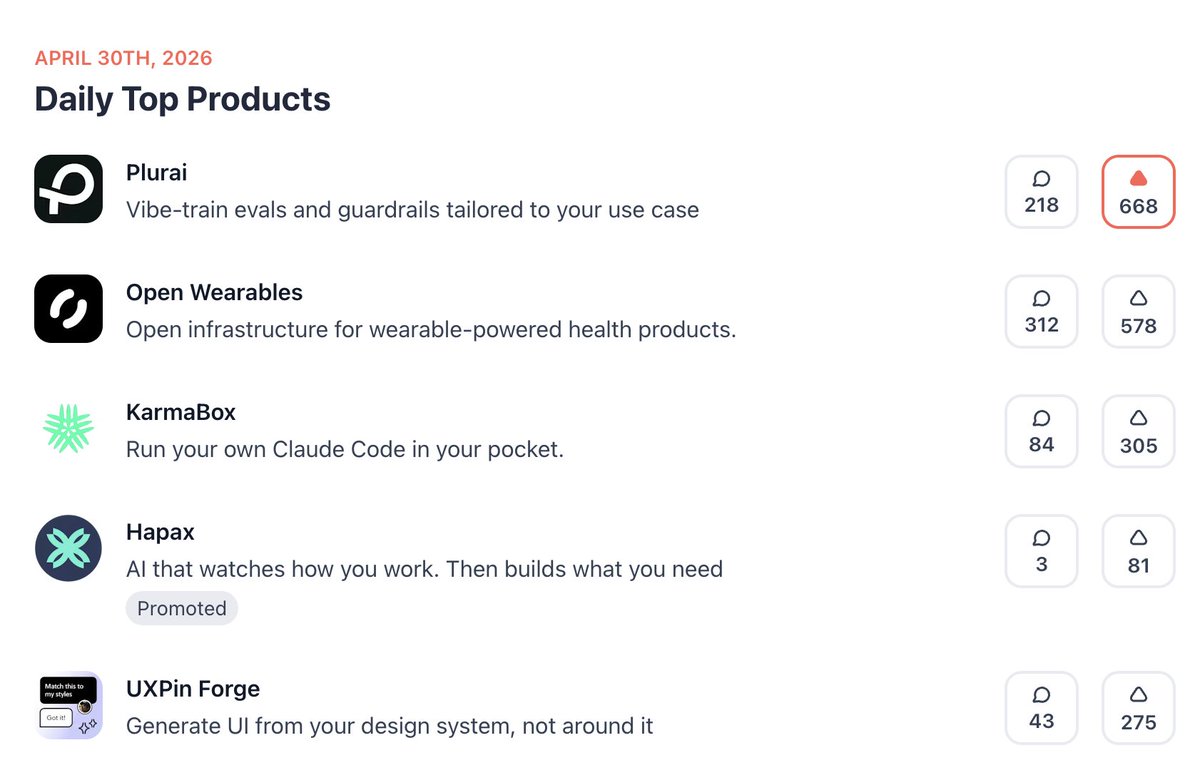
Sabitlenmiş Tweet

Big day for us, finally sharing what we’ve been cooking for a while.
Over the past year, we kept seeing the same pattern:
AI agents look great in demos, until real users break them.
Today, we’re fixing that with 𝘃𝗶𝗯𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴
to build real-time, tailored evals and guardrails
for your agents, in minutes.
Define your intent with a prompt or a few examples.
We generate edge-case datasets,
and train a model aligned to your use case,
outperforming state-of-the-art LLMs at a fraction of the cost.
(Research paper with benchmarks in the comments)
If you’re building AI agents, don’t let your users be the ones who discover the failures. Be the one who makes AI agents reliable in production and takes control at scale.
Start vibe-training for free: plurai.ai/launch
English