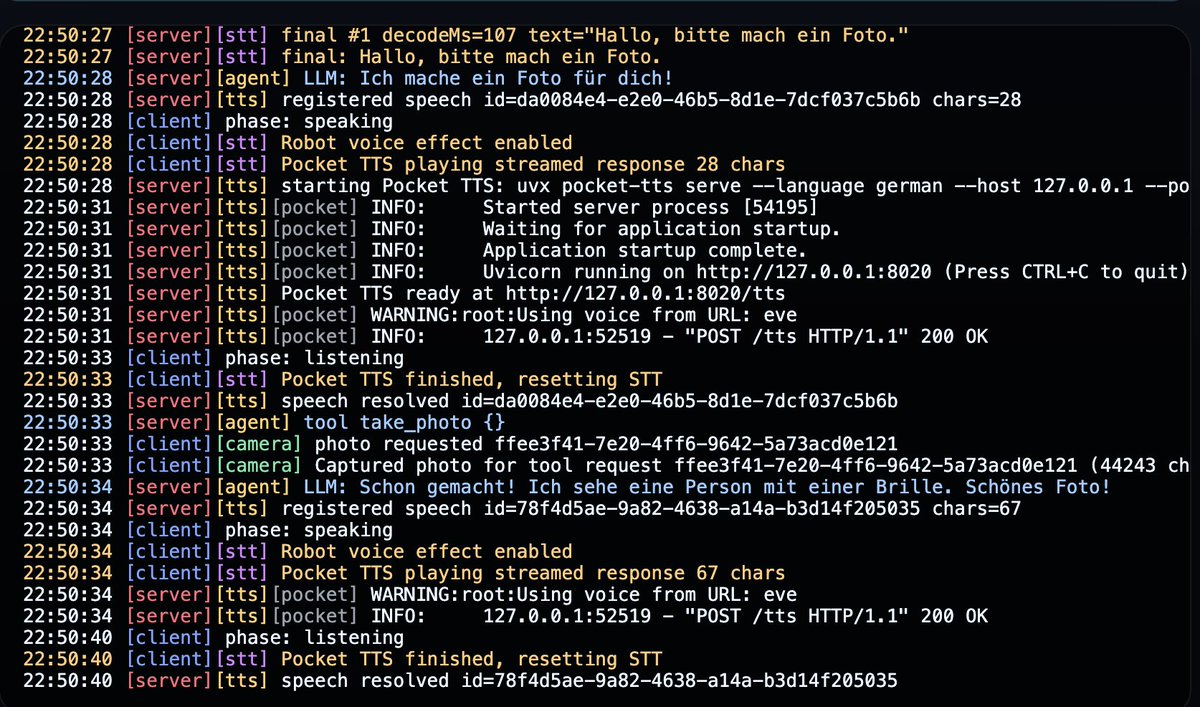
@mattshumer_ @nickbaumann_ Even better, call claude-code through tmux (or equivalent) so you'll get the full experience without being limited by claude -p upcoming changes
English
Ilpo Leppänen
5.3K posts






Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness. SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them. A few things I learned that you should consider too. 1. The validation gate is the only thing that matters in a self-editing loop. Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop. 2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot. Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size. 3. Compactness wins. Median final skill: ~920 tokens. Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't. 4. The harness is becoming less important; the skill is becoming more important. A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that produced it. 5. Frozen model + trained context is the practical adaptation. GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models. 6. Verification is the bottleneck. Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage. There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7, gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK: - Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it. - Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is. Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured. The fast/slow split they describe already lives implicitly in the digital-brain-skill repo: - voice-guide and tone-of-voice.md are slow-state (rarely touched) - posts.jsonl and bookmarks.jsonl are fast-state What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing. If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: arxiv.org/pdf/2605.23904


TanStack Virtual now has first-class chat support: end anchoring, append-follow, stable prepends, and streaming messages that stay pinned when they should. The modern web is now a lot of streaming UI on top of lists, so this needed to feel boring 😉 tanstack.com/blog/tanstack-…


Spending today learning more about ai design tools. Outside of paper what else should I try
Rewriting Bun in Rust: 6 days Writing a blog post about it: 2+ weeks