
Iman Hosseini
1.6K posts

Iman Hosseini
@iman2_718
https://t.co/EoME10h3rV
London, England Katılım Mayıs 2016
2.1K Takip Edilen472 Takipçiler


just read the Titans and Nested Learning paper
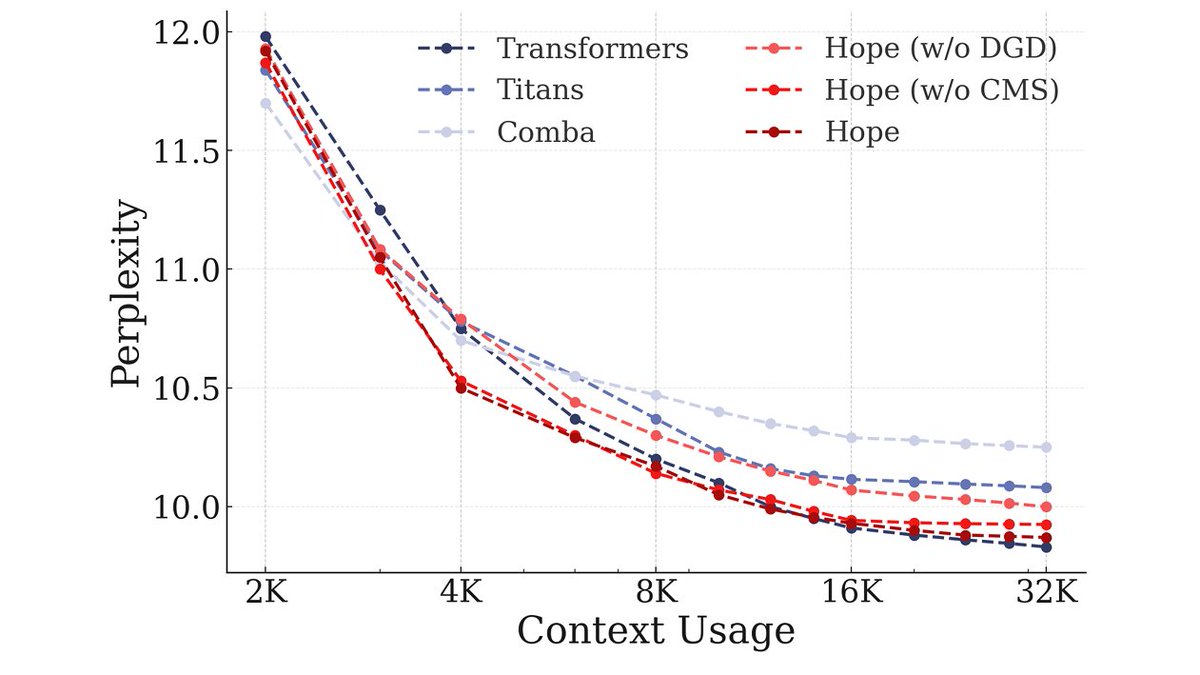
Is this the figure that killed Hope?
English

Thank you very much, I was just trying to share that we tried to show both good sides and challenges in the paper, and potentially a model with good continual learning results might not still use its context perfectly.
Honestly, we have had multiple follow up works in this direction, like Atlas, Miras, ..., (each tried to target orthogonal aspects/challenges in the models) and hopefully more to share in future😀 Also, I remember that there have been a PR to claude-mem repo for Titans with showing improvements. I think each model has a lot to improve and to build upon, and these models are not exceptions.
BTW, LLM aside, there have been some public efforts for adapting Titans for different data modalities and some tasks (e.g., video, EEG, remote sensing, ...), and hopefully more to come. The publication of Hope also is just about 3-4 months old, and there are some papers using it already.
English
Iman Hosseini retweetledi

POV: about to drop the Ring into Mount Doom. Why didn't the Fellowship just use a fighter jet?
Google Labs@GoogleLabs
Because your pet already thinks the universe revolves around them… why not create one that actually does? With Project Genie, upload a picture of your pet and have them explore infinitely diverse worlds. Learn more: labs.google/projectgenie
English
A while ago I was looking at a problem and thought man I wish I could ask @jonmasters.
Then I realized I literally can. We are colleagues :)
English
Iman Hosseini retweetledi
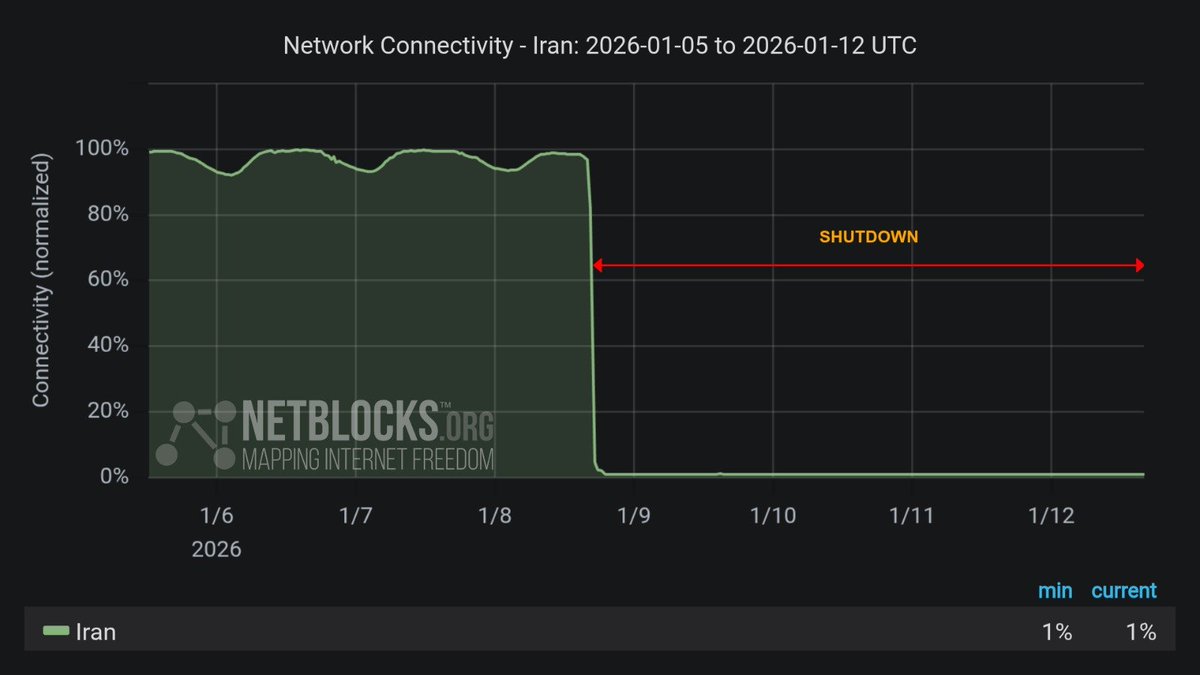
⚠️ Update: #Iran has now been offline for 96 hours, limiting reporting and accountability over civilian deaths as Iranians protest and demand change; fixed-line internet, mobile data and calls are disabled, while other communication means are also increasingly being targeted ⌛️
English

built kernelscope - CUDA kernel debugger that maps source lines to PTX + GPU events
runs entirely on @modal btw
analyzing warp state, memory coalescing, warp divergence, SM occupancy, hints 4 perf
more info&pics in next post
@charles_irl @can this is my job application part 2

English
Josh Woodward@joshwoodward
✅ Papercut fixed: Gemini Live is learning some better conversational manners! 2 things rolling out… 1) We've fixed the bad habit of cutting you off mid-sentence if you pause too long - that should happen less, starting on Android and then iOS in the new year 2) You'll be able to mute your mic while it's talking, so you don't accidentally interrupt it Basically: less talking over each other, more smooth chatting on @GeminiApp :)
English

@robhoeij Pause stops the conversation; what you really need is a mute button that allows Gemini to keep talking. Very important in a public setting.
English
Gemini's deep integration with Google products is quite impressive.
For example: I was in Italy last week, and tried a simple query (make me a day trip in Florence from the train station) both in ChatGPT and Gemini last week. The actual plan was somewhat similar, but the Google Maps integration in Gemini was incredibly handy. Take a look at the end of this conversation: gemini.google.com/share/4516b0af…
I actually followed that Google maps loop for the rest of the day. And became a daily user, right after that. I found Gemini to be a lot more accurate on travel/local info.
Things I still miss from ChatGPT:
- speed of q&a (chat feels way snappier)
- polish of iOS app (Gemini still has some rough edges)
- ability to mute my mic in voice mode (this feels like a surprising miss in Gemini)
English
FishMaze writeup has been released: github.com/google/google-…
It's the first ever Pallas or TPU-themed chal in a ctf AFAIK.
Check out g.co/tpu to learn more about the chips that power Gemini.
If you have a cool idea & want some free flops: site.research.google.com
English

Quick life update. Moved to California to work at NVIDA. Oh I have so much to learn

English
Iman Hosseini retweetledi
Excited to announce our work on Nested Learning that also recently accepted to NeurIPS 2025! Stay tuned for the full version on arXiv (in the next few days) and then I'll discuss more details about the intuition behind its design and why we believe it can help with continual learning!
Google Research@GoogleResearch
Introducing Nested Learning: A new ML paradigm for continual learning that views models as nested optimization problems to enhance long context processing. Our proof-of-concept model, Hope, shows improved performance in language modeling. Learn more: goo.gle/47LJrzI @GoogleAI
English
@apaszke @mike64_t @clattner_llvm @_sanjoydas @metaai github.com/NervanaSystems…
Ironically, the one guy who _can_ say he outperformed CUDA, doesn't need to anymore.
English

@mike64_t @clattner_llvm @_sanjoydas @metaai Yeah if you write kernels using your own SASS assembler and get better perf then I am 100% on board with saying you outperform CUDA :)
English

Thank you to folks at @metaai for publishing their independent perf analysis comparing CUDA and Mojo against Triton and TileLang DSLs, showing Mojo meeting and beating CUDA, and leaving DSLs in the dust.

English
Iman Hosseini retweetledi

Iman Hosseini retweetledi
Want to improve GPU compute/comms overlap? We just published a new short tutorial for you!
A few small changes to the Pallas:MGPU matmul kernel is all it takes to turn it into an all-gather collective matmul that overlaps NVLINK comms with local compute: docs.jax.dev/en/latest/pall…
English
Iman Hosseini retweetledi
Curious how to write SOTA performance Blackwell matmul kernels using MGPU? We just published a short step-by-step tutorial: docs.jax.dev/en/latest/pall…
At each step, we show exactly what (small) changes are necessary to refine the kernel and the final kernel is just under 150 lines.
English
Got my signed copy 🫠


Marcus Hutter@mhutter42
My new book finally ships! You fear your math is not up to scratch? Fear not, over 100 pages are devoted to introducing the relevant concepts. routledge.com/An-Introductio… #AI #AGI #ArtificialIntelligence #Math #Maths #machinelearning #ReinforcementLearning
English