Sabitlenmiş Tweet
✦
13.2K posts


✦ retweetledi

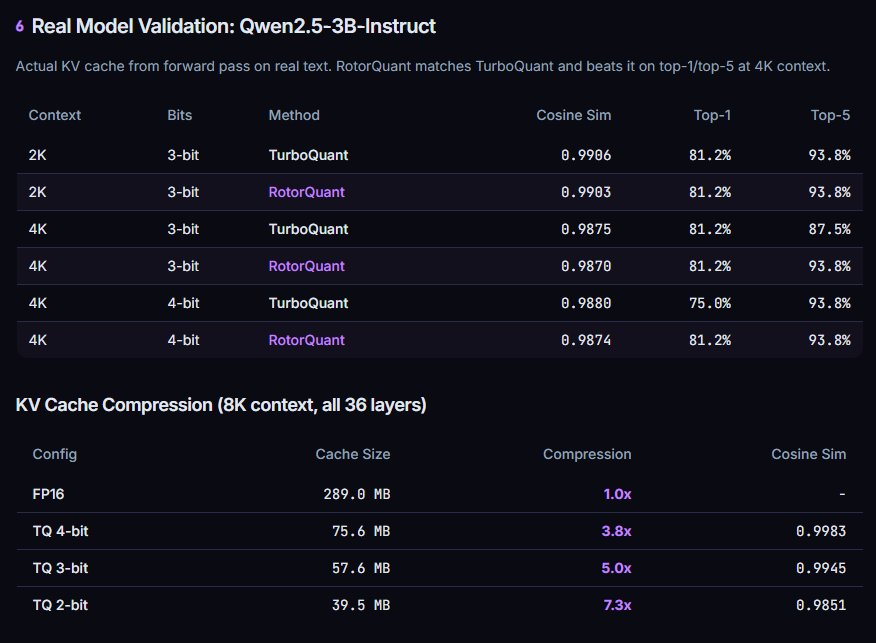
RotorQuant - upgraded TurboQuant.
> 10x KV cache compression
> 28% faster decoding
> 5x faster prefill
> 44x fewer parameters
Same quality as full attention. 1/10th the memory.
Ok, another massive VRAM discount for local LLMs.
github.com/scrya-com/roto…
English



✦ retweetledi

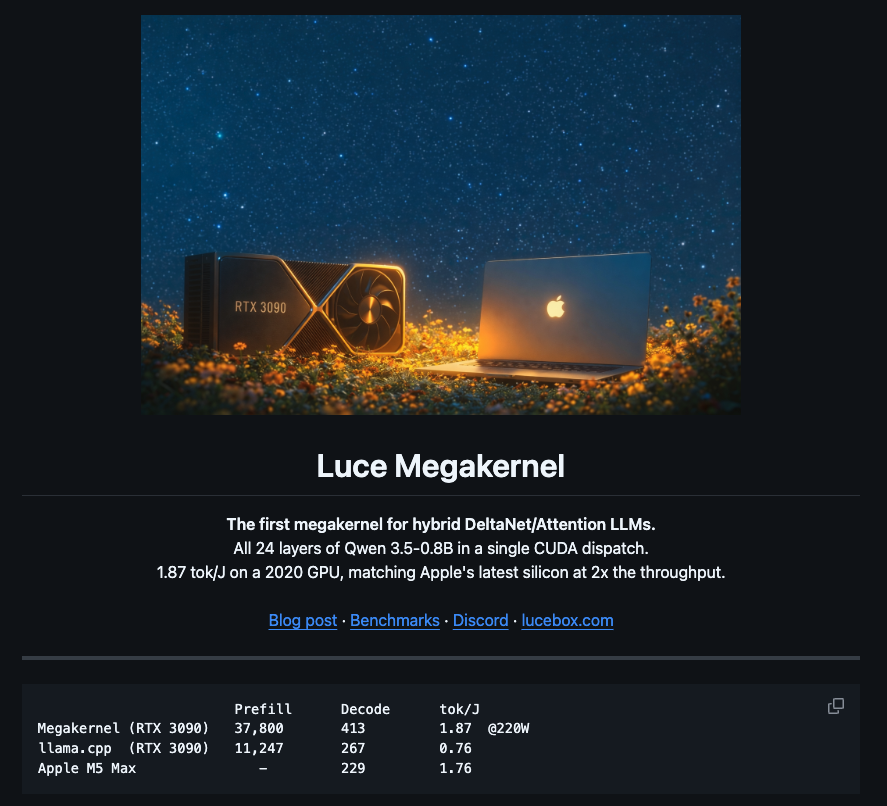
Excited to release a Megakernel to make a 6-year-old RTX 3090 running Local LLMs faster than apple's latest M5 Max chip.
not a benchmark trick. same model, same weights, one kernel change.
the full breakdown is in the article below. Open-source, MIT licensed, you can reproduce it in one command.
Sandro@pupposandro
English

講真 你如果發現你社群的分析師沒讀過大學或是讀學店 你還敢信他們嗎
台灣幣圈現況
學歷不是唯一出路 只是篩選手段
但95%都沒讀過書
中文

Pretty cool to see Tobi using Hermes and the Manim skill!
tobi lutke@tobi
Hermes agent ships with this nifty /manim_video skill so I asked it to explain how a QMD query works:
English
✦ retweetledi

为 Hermes 打造的 HUD 一款开源的 TUI 显示器
→ 从 Hermes Agent 数据目录实时读取记忆、纠错、工具使用等状态并渲染成交互式 TUI
→ 9 个标签页覆盖仪表盘、成长对比、Cron 任务、项目追踪、健康检查、Prompt 模式等
→ 4 套赛博朋克风格主题(Neural Awakening / Blade Runner / fsociety / Digital Soul)
→ 快照对比功能直观展示 Agent 从昨天到今天记住了什么、少犯了什么错
github.com/joeynyc/hermes…

中文
✦ retweetledi


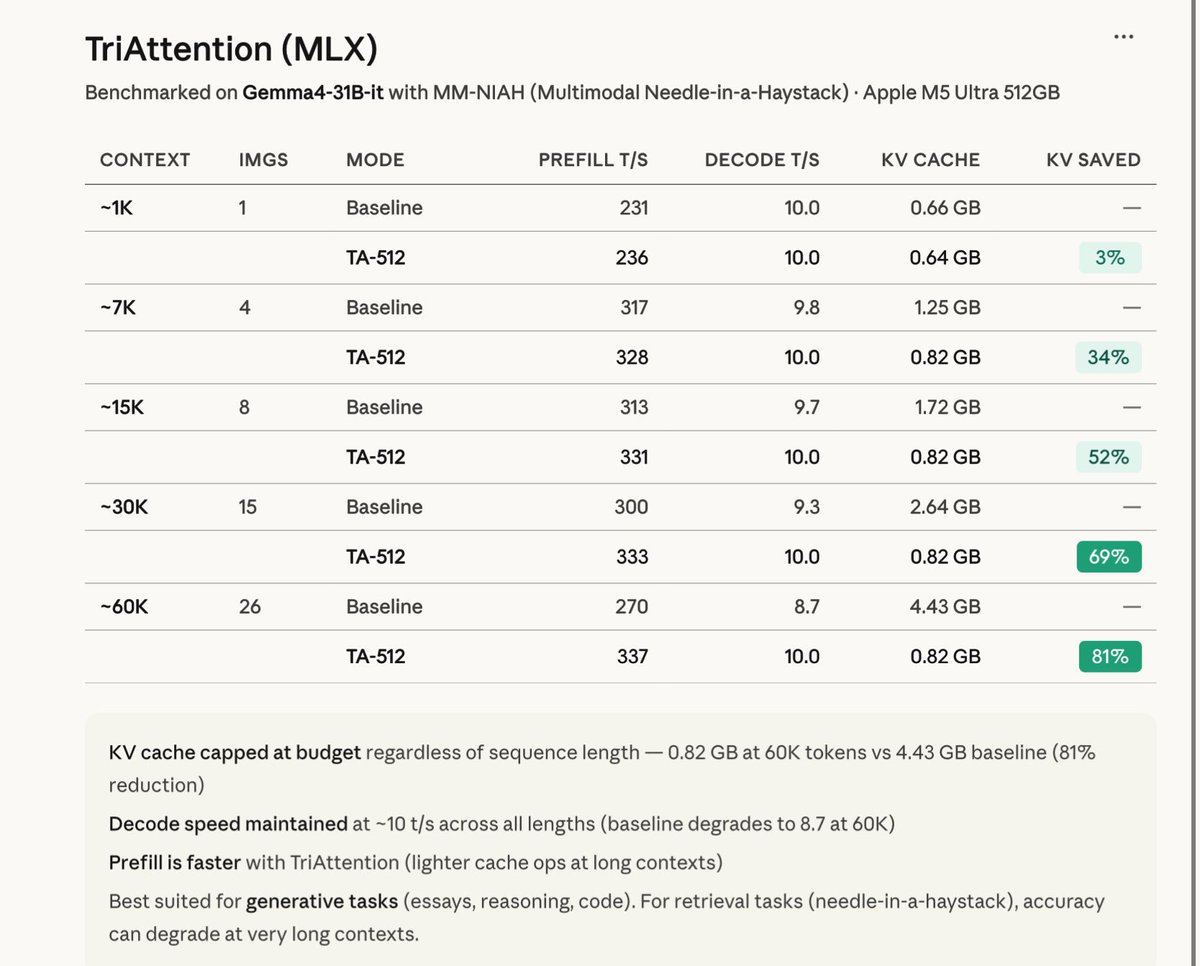
Just implemented TriAttention in MLX and the results are wild!
You can get up to 81% KV compression at 60K tokens for Gemma-4-31B-IT in BF16 🔥
Unlike TurboQuant, which quantizes KV cache values, TriAttention prunes low-importance tokens entirely by scoring keys using trigonometric series from pre-RoPE Q/K concentration and keeping only the top-B most important ones.
The best part? Decode speed for BF16 stays locked at ~10 t/s while baseline drops to 8.7 at long contexts. This results scale well with the quantized version as well.
Benchmarked on Gemma4-31B-it with MM-NIAH on M5 Ultra:
~1K → 3% saved
~7K → 34% saved
~15K → 52% saved
~30K → 69% saved
~60K → 81% saved
KV cache capped at 0.82 GB regardless of context length.
One-time calibration (~30s), then it just works during generation.
One caveat: TriAttention by design is best suited for generative task (reasoning/code) and not retrieval tasks.
PR will follow soon on MLX-VLM.
Yukang Chen@yukangchen_
We’re thrilled to open-source TriAttention! 🚀 🦞 Deploy OpenClaw (32B LLM) on a single 24GB RTX 4090 locally 💻Full code open-source & vLLM-ready for one-click deployment ⚡️ 2.5× faster inference speed & 10.7× less KV cache memory usage TriAttention is a novel KV cache compression method built on rigorous trigonometric analysis in the Pre‑RoPE space for efficient LLM long reasoning. Github Repo: github.com/WeianMao/triat… Paper Link: huggingface.co/papers/2604.04… Homepage: weianmao.github.io/tri-attention-…
English


@SpatiallyMe This reminds me that the iPads everyone keeps in the drawer finally have a use.
English

I just launched a free App that lets you open Mac Apps…from your iPhone. And close them with a swipe. A much faster drag and drop. And a ton of more features in the pipeline.
It’s called choclift and you really should try it out. Available for free in the App Store for iOS and macOS.
English