Alessandro Benigni
416 posts


Alessandro Benigni
@itsbenigni
Co-Founder & CMO at https://t.co/zjkdUzAMrV
Talking to smarter folks than me, I'm convinced many of the AI folks in my timeline are full of shit. Nobody is "running 20 agents over night" and building stuff for actual users. Maybe some are building internal tools or disposable software. Maybe. But building software people like using? That doesn't get hacked on day one or blow up after the 3rd user? Nope. I don't even understand what that's supposed to look like. Do you work out a 57 pages document that perfectly describes what you want to build and then summon 14 agents and have them run wild for 6 hours? And what comes out on the other end isn't a broken pile of shit? Nope. Not buying it. PS: it may also be that I have an IQ of 82 and can't figure it out.





@Teknium @jrswab Ya know local models on consumer hardware are the issue, like Hermes doesn’t work with Hermes 🙃
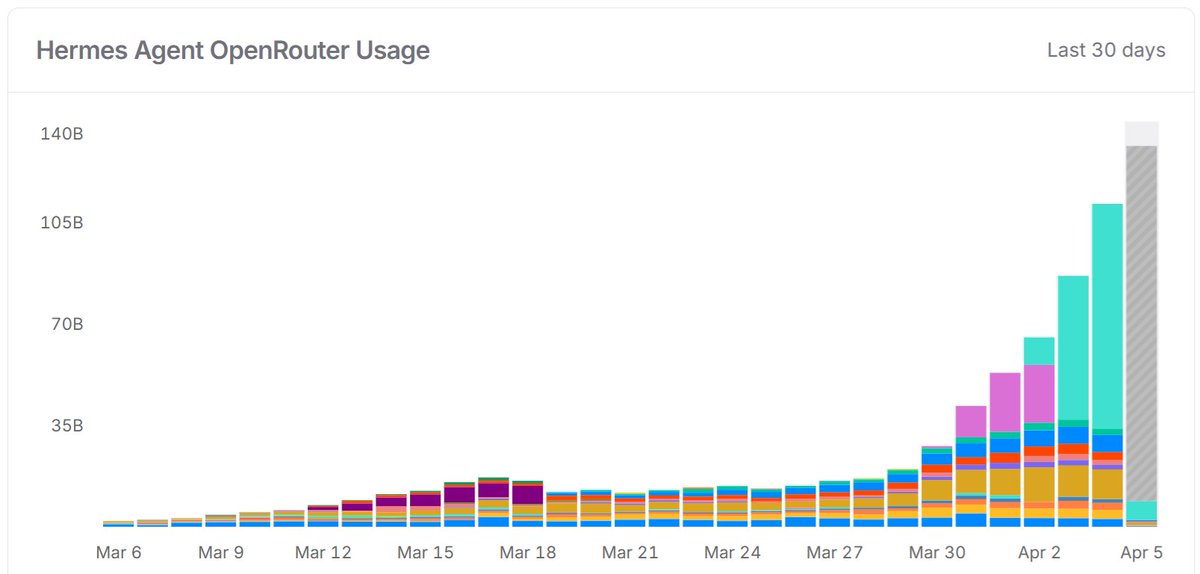
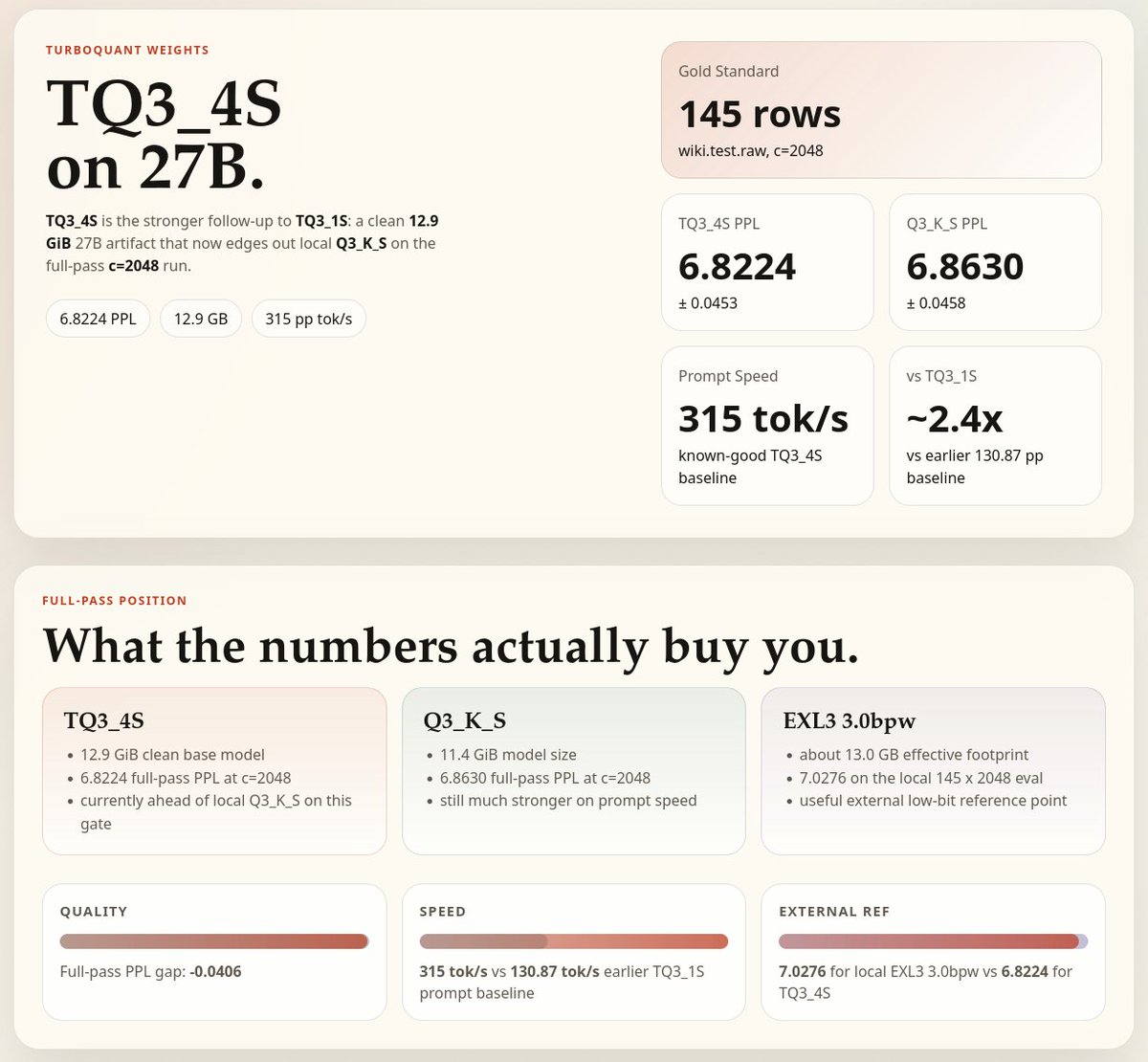
last time the openclaw founder said open models aren't there yet. now he's saying local models on consumer hardware are the issue. this is not someone who cares about open source speaking. this is someone with a corporate paycheck channeling you toward their subscription because every local AI install is a subscription they lose. he picked a year old hermes model against a new agent harness and called it not ready. that didn't come from proper testing. it came from watching nousresearch grow exponentially while his project bleeds relevance. a founder who left his project without seeing its full potential is arguing with a founder who is still grinding day and night for open source. nousresearch is open source head to toe. the models, the harness, the memory system, everything. and it's winning. that's what panics them. while corporate salesmen say local models on consumer hardware aren't there, i just published an article where 27B dense on a $900 consumer GPU one-shotted a task that 120B on $70K enterprise hardware could not complete in 3 tries. through hermes agent. every number is in the article. you decide which side you want to be on. the side that mines every bit of your thinking and profits off it. or the side where you own your compute and your cognition. don't let corporate salesmen disguised as information lead you to their subscription page.



Meet Gemma 4! Purpose-built for advanced reasoning and agentic workflows on the hardware you own, and released under an Apache 2.0 license. We listened to invaluable community feedback in developing these models. Here is what makes Gemma 4 our most capable open models yet: 👇