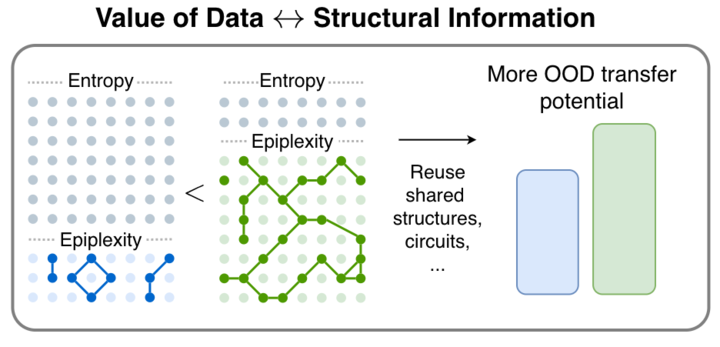
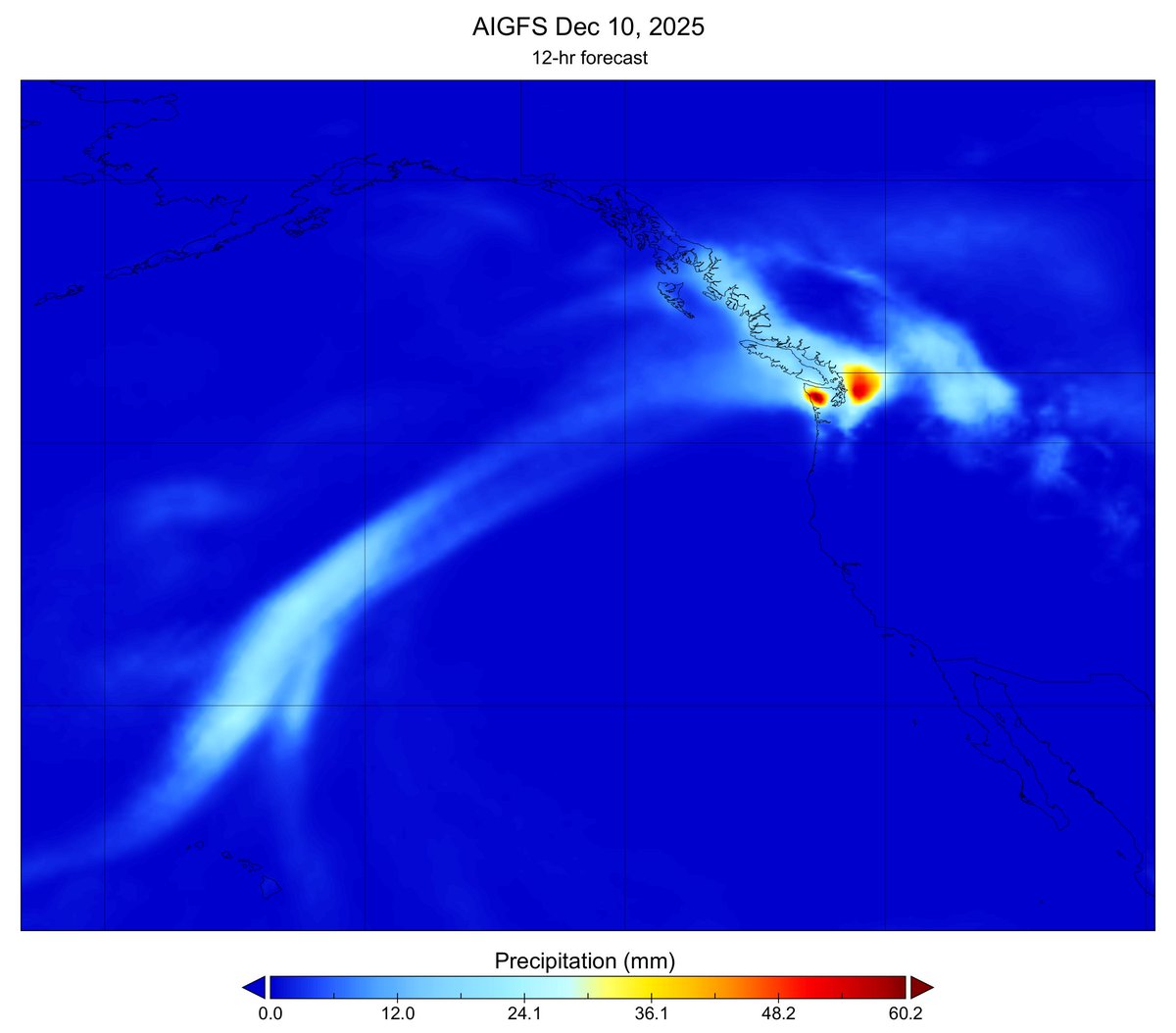
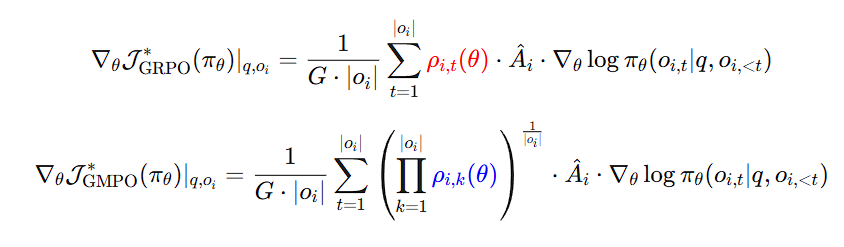Srikar retweetledi

The Terence Tao episode.
We begin with the absolutely ingenious and surprising way in which Kepler discovered the laws of planetary motion.
People sometimes say that AI will make especially fast progress at scientific discovery because of tight verification loops.
But the story of how we discovered the shape of our solar system shows how the verification loop for correct ideas can be decades (or even millennia) long.
During this time, what we know today as the better theory can often actually make worse predictions (Copernicus's model of circular orbits around the sun was actually less accurate than Ptolemy's geocentric model).
And the reasons it survives this epistemic hell is some mixture of judgment and heuristics that we don’t even understand well enough to actually articulate, much less codify into an RL loop.
Hope you enjoy!
0:00:00 – Kepler was a high temperature LLM
0:11:44 – How would we know if there’s a new unifying concept within heaps of AI slop?
0:26:10 – The deductive overhang
0:30:31 – Selection bias in reported AI discoveries
0:46:43 – AI makes papers richer and broader, but not deeper
0:53:00 – If AI solves a problem, can humans get understanding out of it?
0:59:20 – We need a semi-formal language for the way that scientists actually talk to each other
1:09:48 – How Terry uses his time
1:17:05 – Human-AI hybrids will dominate math for a lot longer
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, or Spotify.
English