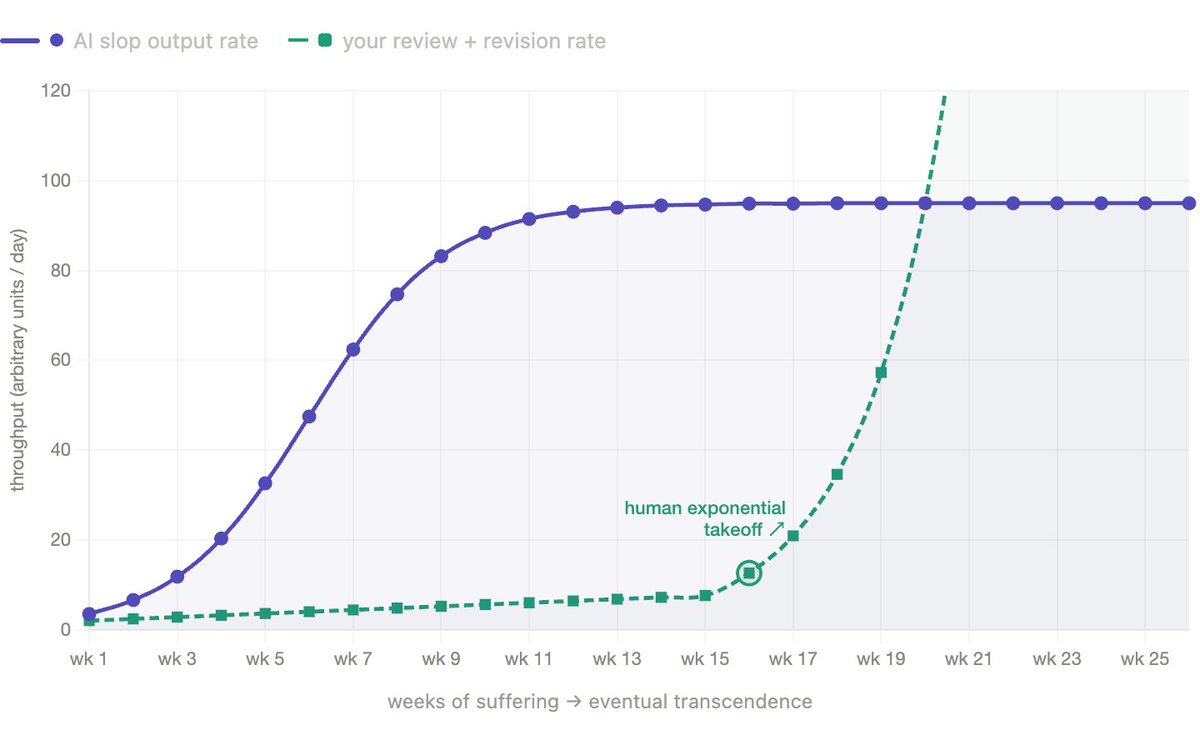
@vansickn @MattRogish here's a draft teaser. will publish when our blog goes live in general which should be any day now
English
PME
1.4K posts

@itsyourcode
Pro-grammer building the data agent for truth seekers @probablydatabot


I reverse engineered San Francisco's towing system. I can see every car the second it's towed. So I made a site to "FIND MY" towed car. Inspired by @rtwlz

frog told the LLM "do not hallucinate" "there," he said, "now the LLM will not make mistakes" "but the LLM can still hallucinate" said toad "that is true" said frog