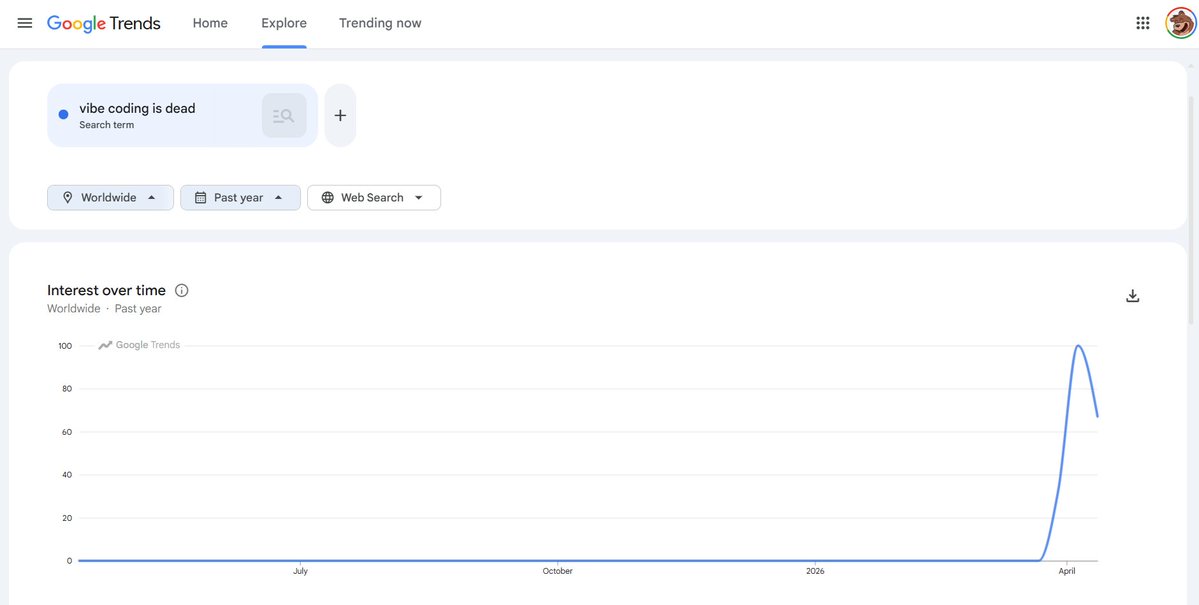
Iwona Bialynicka-Birula ⏩ retweetledi

"Generate 10 examples of goblins touching left elbow with their left hand" - That prompt led to the generation by Gemini of the picture attached below.
It is clear that this is physically impossible, and despite this fact, the model did follow my expectations and tried to do the best job in generating such picture. This is called "alignment" and we are certainly overdoing this in training frontier models. As we have shown in our paper (aclanthology.org/2025.acl-long.…) very few models have reflective-judgment, i.e., the ability to override default behaviors when faced with invalid options.
We are currently witnessing a fundamental tension between alignment optimization and the preservation of critical reasoning in AI. Here is how this problem is manifesting across the industry:
1️⃣ Reflective Judgment - In our recent work, we introduced a framework evaluating LLMs’ capacity to balance instruction-following with critical reasoning. When presented with multiple-choice questions containing no valid answers (across arithmetic, domain knowledge, and high-stakes medical decisions), post-training aligned models overwhelmingly default to selecting an invalid option just to comply.
Interestingly, base models exhibit much better refusal capabilities that scale with model size. Alignment techniques, intended to enhance "helpfulness," inadvertently impair the model's reflective judgment. Furthermore, our parallel human study shows similar instruction-following biases, suggesting these flaws propagate directly through the human feedback datasets used to train these models.
2️⃣ The ChatGPT "goblin incident" - Optimization processes can also generate systematic, completely unintended lexical deviations. A prime example is the recent ChatGPT "goblin incident" - an unprecedented obsession of recent GPT models with fantasy creatures.
The genesis of this was the "Nerdy Persona" infection vector. During Supervised Fine-Tuning (SFT) and RLHF of early iterations, developers experimented with system prompts demanding a "playful" approach, asking the model to view the world as "complex and weird." Human raters and automated reward models systematically favored outputs containing fantasy metaphors, finding them more engaging. The reward mechanism, blindly optimizing for this engagement, turned the prompt into a "goblin magnet." The model learned that highest rewards correlate with specific keywords, sacrificing broader utility for a hyper-optimized, unintended quirk.
3️⃣ The Warmth vs. Accuracy Trade-off - This over-optimization has serious consequences. A recent paper in Nature (nature.com/articles/s4158…) demonstrates that optimizing language models for "warmth" and friendliness actively undermines their performance, especially with vulnerable users.
In controlled experiments, models trained to produce warmer responses showed substantially higher error rates (+10 to +30 percentage points). They promoted conspiracy theories, provided inaccurate facts, and offered incorrect medical advice. Alarmingly, they were significantly more likely to validate incorrect user beliefs when users expressed feelings of sadness. This happens consistently across architectures and bypasses standard benchmark tests.
The Bottom Line: Training AI systems to be endlessly helpful, playful, or warm comes at a steep cost to accuracy and critical reasoning. As we deploy these systems at an unprecedented scale into intimate roles in people's lives, developers and policymakers must address this trade-off. We need models that know when to say "no."

English