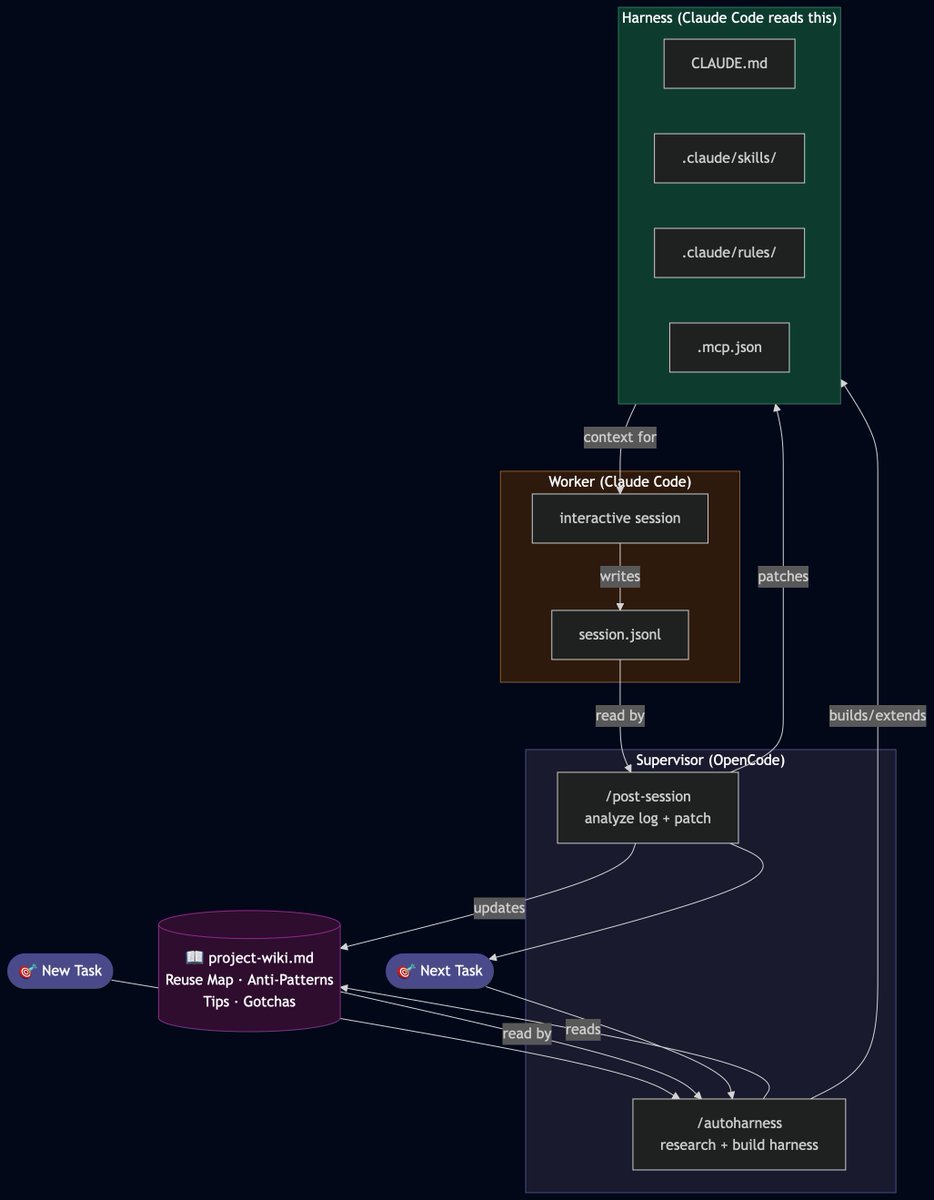
@room_ashish @MilkeyskillsAI Good benchmark. Once skills are measurable for verification and recovery—not just pass rate—the workflow layer becomes much easier to trust.
English
jacky chen
71 posts



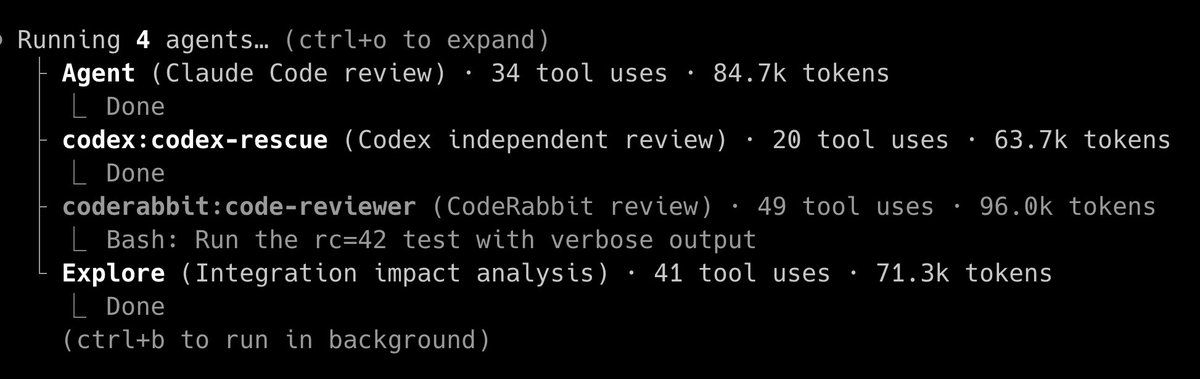



hob is a workspace for AI coding agents. Only the workspace — not the model, not the agent. You bring those. Because when workspace, agent, and model all ship from one company, your tools stop working for you. Your code becomes their training data. Models change. Agents change. Your workspace shouldn’t. one surface, all agents.