Sabitlenmiş Tweet

We release CWM, a 32B LLM for code reasoning, agents, and world modeling research!
📊 Tech Report ai.meta.com/research/publi…
🤖Model Weights ai.meta.com/resources/mode…
🤗 Hugging Face huggingface.co/facebook/cwm
🧑💻 Inference Code github.com/facebookresear…
Check it out
Gabriel Synnaeve@syhw
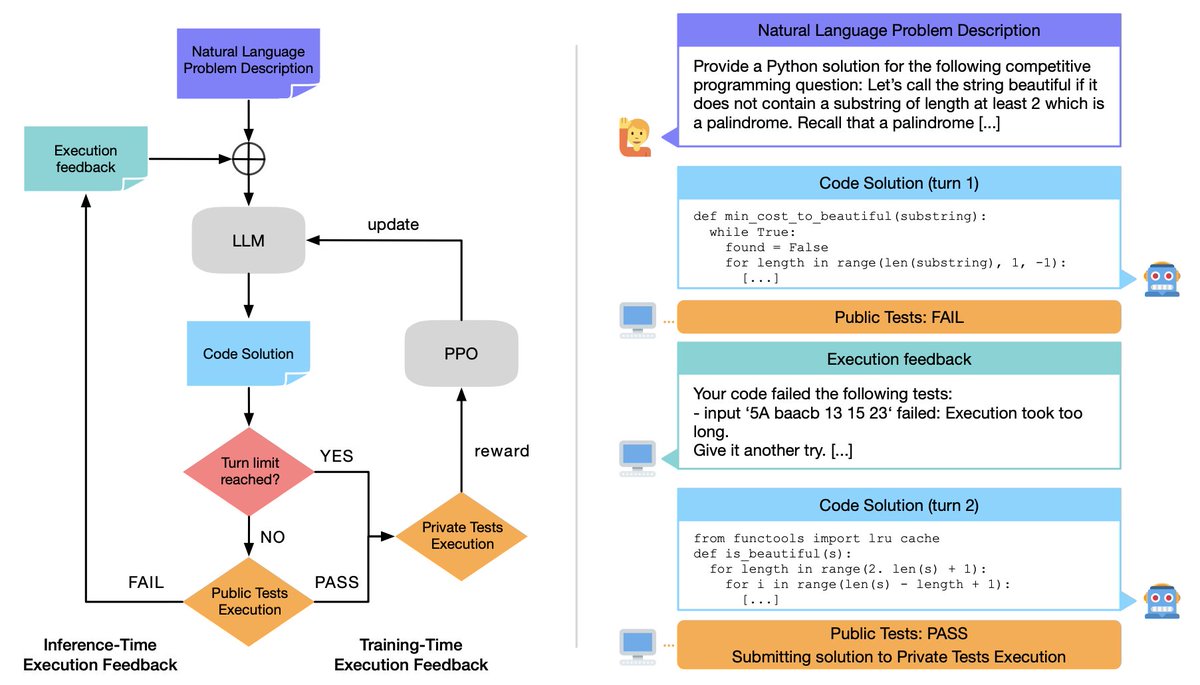
(🧵) Today, we release Meta Code World Model (CWM), a 32-billion-parameter dense LLM that enables novel research on improving code generation through agentic reasoning and planning with world models. ai.meta.com/research/publi…
English