Jama 🚀 retweetledi

An Object is Worth 64x64 Pixels: Generating 3D Object via Image Diffusion
discuss: huggingface.co/papers/2408.03…
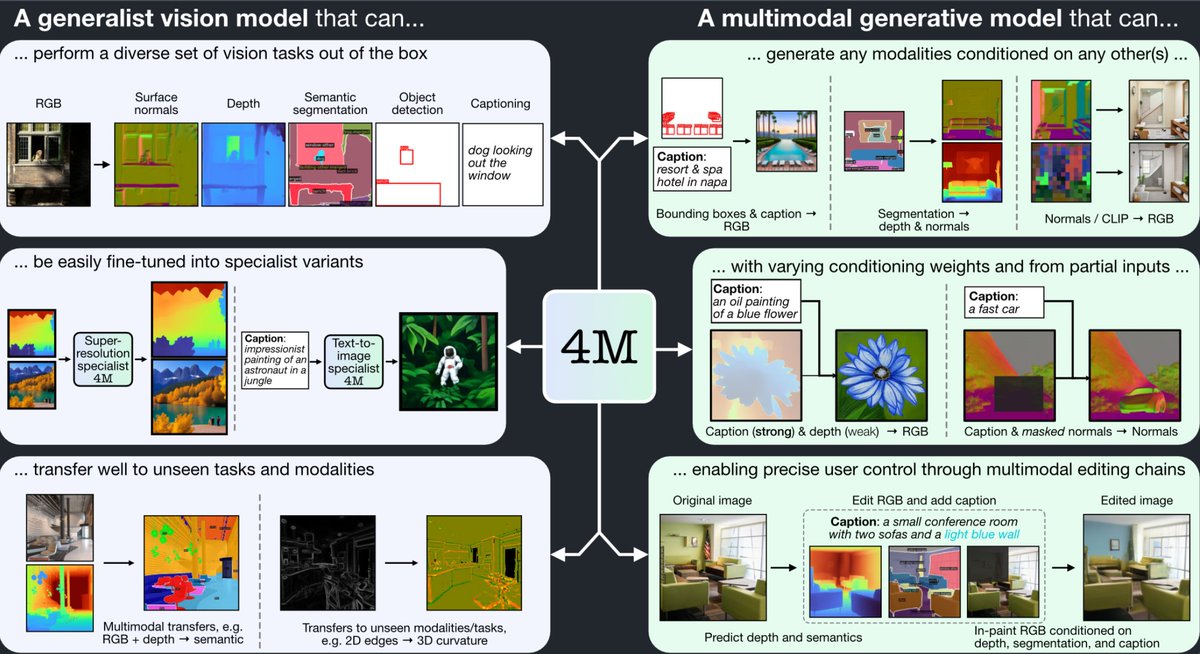
We introduce a new approach for generating realistic 3D models with UV maps through a representation termed "Object Images." This approach encapsulates surface geometry, appearance, and patch structures within a 64x64 pixel image, effectively converting complex 3D shapes into a more manageable 2D format. By doing so, we address the challenges of both geometric and semantic irregularity inherent in polygonal meshes. This method allows us to use image generation models, such as Diffusion Transformers, directly for 3D shape generation. Evaluated on the ABO dataset, our generated shapes with patch structures achieve point cloud FID comparable to recent 3D generative models, while naturally supporting PBR material generation.
English