If any Irish speakers are interested in helping annotate some of the BLEnD examples to Irish, please let me know (can be as little as a few examples). We aim to have Irish included in the next release.
huggingface.co/datasets/nayeo…
English
James Barry
193 posts

@jamesarbarry
Research Scientist @ IBM Research | PhD from ADAPT Centre, Dublin City University


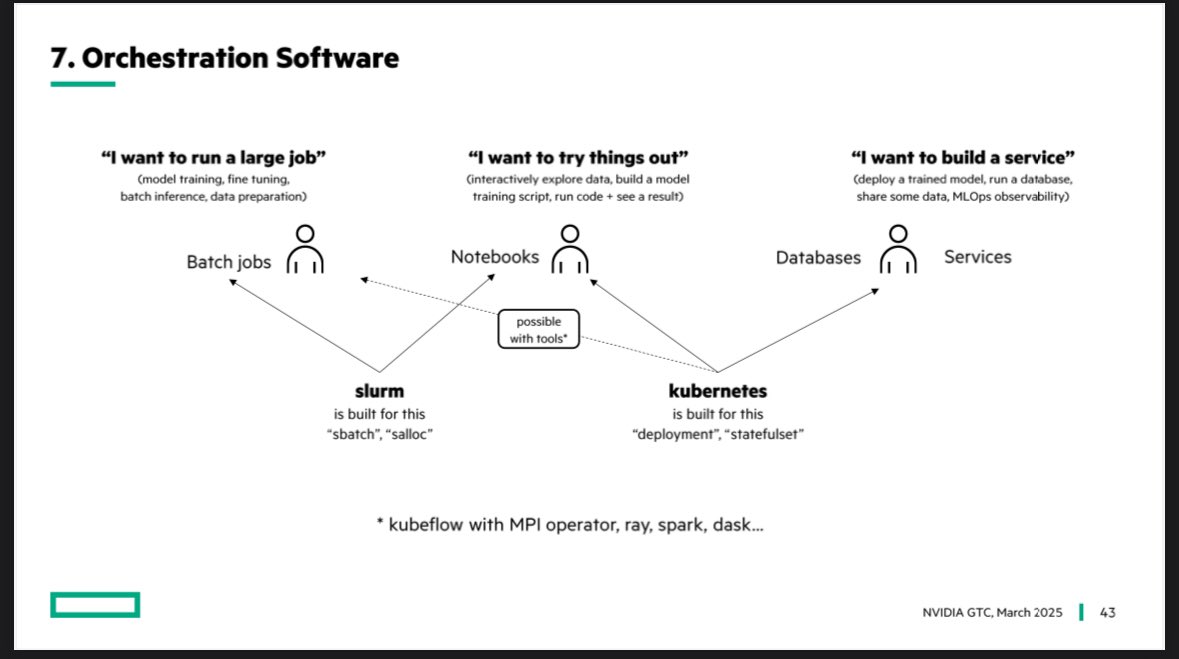
Last week at @NVIDIA GTC I had a talk on what it takes to build a GPU cluster with @HPE and @HPE_Cray It breaks down into a 12 step program 🧵