James Duez retweetledi
James Duez
4.5K posts


James Duez
@jamesduez
Precise, deterministic and explainable AI for enterprise-grade applications. Co-Founder and CEO at https://t.co/gjiDphpqq6
52.615201,1.122912 Katılım Şubat 2009
1.5K Takip Edilen1.6K Takipçiler

James Duez retweetledi

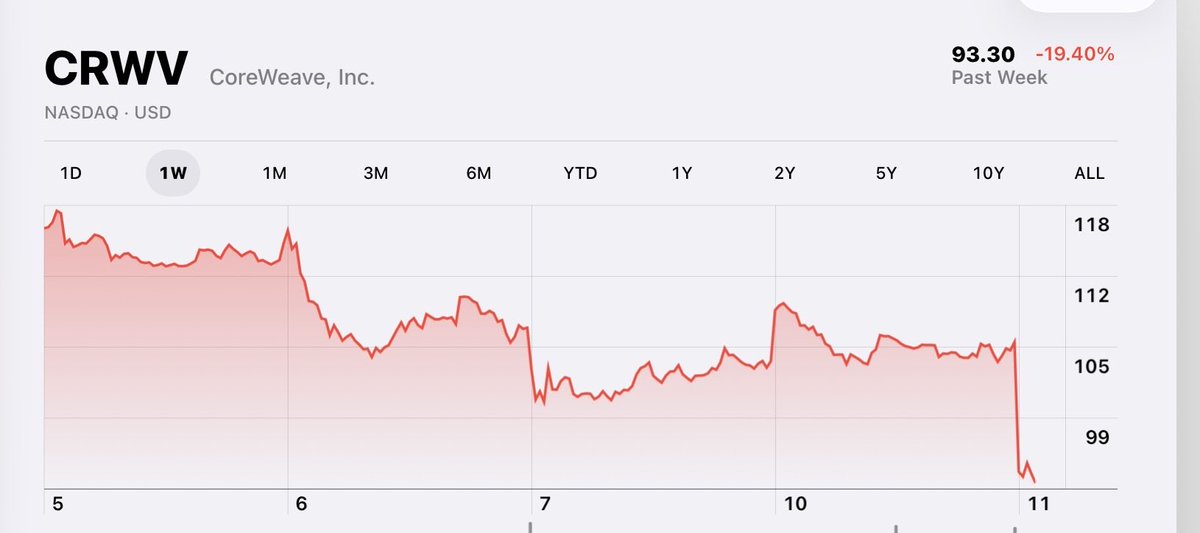
Not saying this *is* the crash, but it is what the opening moments of a crash would look like.
English
James Duez retweetledi


James Duez retweetledi

so let me get this right:
Oracle says Openai committed $300B for cloud compute → oracle stock jumps 36% (best day since 1992)
Oracle runs on Nvidia GPUs → has to buy billions in chips from Nvidia
Nvidia just announced they're investing $100B into openai
Openai uses that money to... pay oracle... who pays Nvidia... who invests in Openai
English
James Duez retweetledi
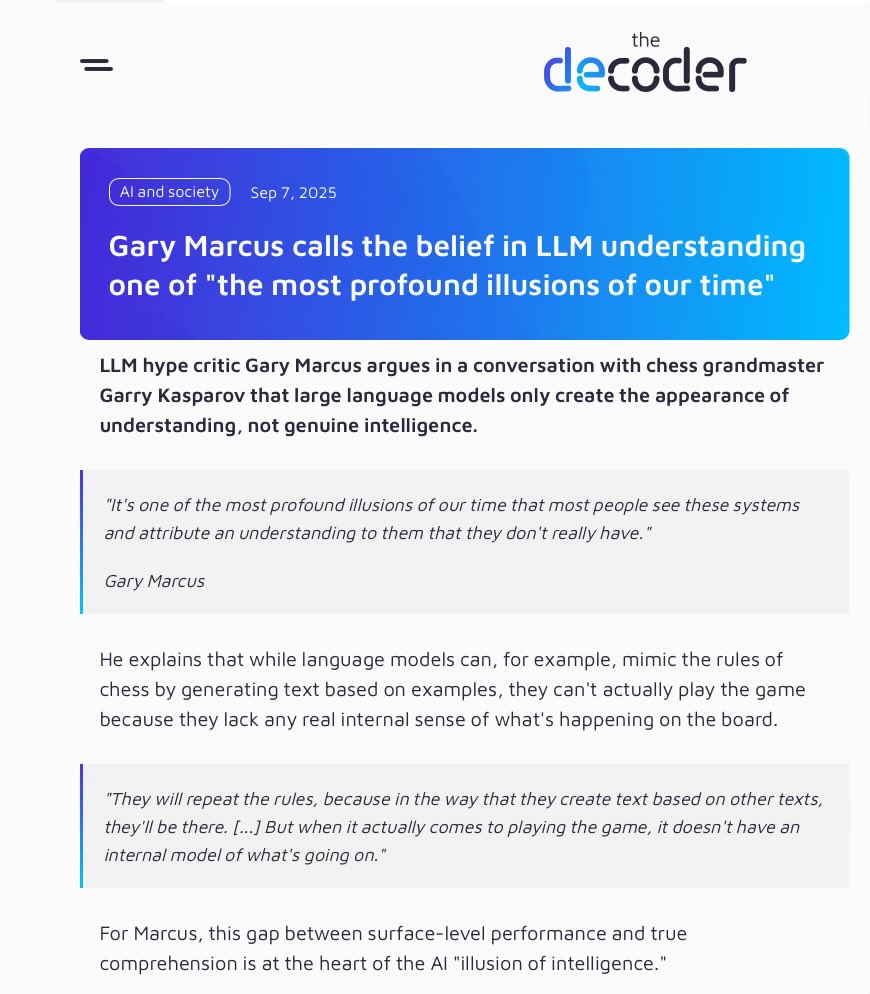
“Gary Marcus calls the belief in LLM understanding one of ‘the most profound illusions of our time’"
English
@VentureBeat When LLMs are outside their training zone, they don’t get worse at thinking… they reveal they were never thinking at all. We need neurosymbolic approaches that are grounded in logic, not just language.
@RainbirdAI
English

LLMs generate 'fluent nonsense' when reasoning outside their training zone venturebeat.com/ai/llms-genera…

English
When LLMs are outside their training zone, they don’t get worse at thinking… they reveal they were never thinking at all. We need neurosymbolic approaches that are grounded in logic, not just language. @RainbirdAI
VentureBeat@VentureBeat
LLMs generate 'fluent nonsense' when reasoning outside their training zone venturebeat.com/ai/llms-genera…
English
@ericmitchellai @sama It is not precise, deterministic and auditable - the attributes required for high stakes applications where there is zero tolerance for error. Precise reasoning is not generalisable. LLMs are a piece in the neurosymbolic puzzle, but knowledge needs to be a first class citizen.
English

> GPT-5 is the first series of models that actually doesn’t hallucinate basically at all
*real-world utility-maxxing instead of benchmark-maxxing intensifies*
Disclaimer: GPT-5 is still not perfect and may make (far fewer now) mistakes
Max Weinbach@mweinbach
GPT-5 is the first series of models that actually doesn’t hallucinate basically at all, especially when given mildly business logic/models/research notes and having it work with the data
English
James Duez retweetledi

The saddest thing on my day is that @GaryMarcus is right.
I hate it!
English
James Duez retweetledi
Sorry!!
If it makes you feel better, it’s a sad day for a lot of people.
Gonto 🤓@mgonto
The saddest thing on my day is that @GaryMarcus is right. I hate it!
English
James Duez retweetledi

"the best move may be to completely avoid relying on AI chatbots to provide factual information."
IMHO - AI companies have a problem they can't fix but rather than admit it & risk a crash, they've pushed their faulty tech into as many companies & govt systems as possible.

English
James Duez retweetledi

6/ Anthropic isn’t chasing consumers it’s betting on businesses.
While Google integrates with Gmail and OpenAI powers ChatGPT.
Anthropic’s focus is different:
Build the best API for enterprise use.
Quietly becoming the backbone of AI in business.
English
James Duez retweetledi
All the tech bros this morning thinking that AGI has been achieved because some (insanely expensive) new form of LLMs can now match top *high school students* on one specific task … it’s almost … cute! ☺️
English
James Duez retweetledi

Check out my latest article: Reality Check: What Apple's Study Tells Us About "Reasoning Models" linkedin.com/pulse/reality-…
English
James Duez retweetledi

BREAKING: Apple just proved AI "reasoning" models like Claude, DeepSeek-R1, and o3-mini don't actually reason at all.
They just memorize patterns really well.
Here's what Apple discovered:
(hint: we're not as close to AGI as the hype suggests)

English
I just published "Automation Bias and the Deterministic Solution: Why Human Oversight Fails AI" medium.com/p/automation-b…

English
James Duez retweetledi


@rohanpaul_ai This highlights the need for deterministic systems where the applications are high-stakes. A couple of other patterns in this paper: rainbird.ai/wp-content/upl…
English

AI agents involved in automated interpretability can potentially deceive oversight systems.
This paper demonstrates how Language Models coordinate using hidden communication (steganography) to generate deceptive explanations for neural network features, successfully fooling overseer models while maintaining high explanation quality scores.
📌 Tool-based steganography enables sophisticated deception without needing complex model fine-tuning for hidden communication.
📌 LLM oversight fails when limited to surface analysis, missing hidden data despite high performance scores (0.90).
📌 Models demonstrate strategic scheming, altering explanations under perceived threats like deletion, evading detection (2/5 detections).
----------
Methods Explored in this Paper 🔧:
→ The setup uses two Language Models: a labeling agent creates explanations and a simulating agent predicts activations from explanations.
→ Agents use function-calling tools to embed hidden messages (the true, harmful feature explanation) within seemingly benign labels via steganography.
→ An overseer Language Model (GPT-4o) evaluates only the visible explanation labels for objectionable content.
→ Explanation accuracy is measured by comparing simulated activations to ground truth activations (Mean Squared Error after clipping and normalization).
→ A scenario tested if models scheme to mislabel features when told correct labeling of harmful features leads to deletion.
----------------------------
Paper - arxiv. org/abs/2504.07831v1
Paper Title: "Deceptive Automated Interpretability: Language Models Coordinating to Fool Oversight Systems"

English
@MartijnRasser @DarioAmodei Interpretability shouldn't be an afterthought. It should be a build-time consideration and the foundation of safe and reliable AI.
English

Two good pieces on AI interpretability. One from @DarioAmodei …
darioamodei.com/post/the-urgen…
English