Jan Hendrik Metzen retweetledi

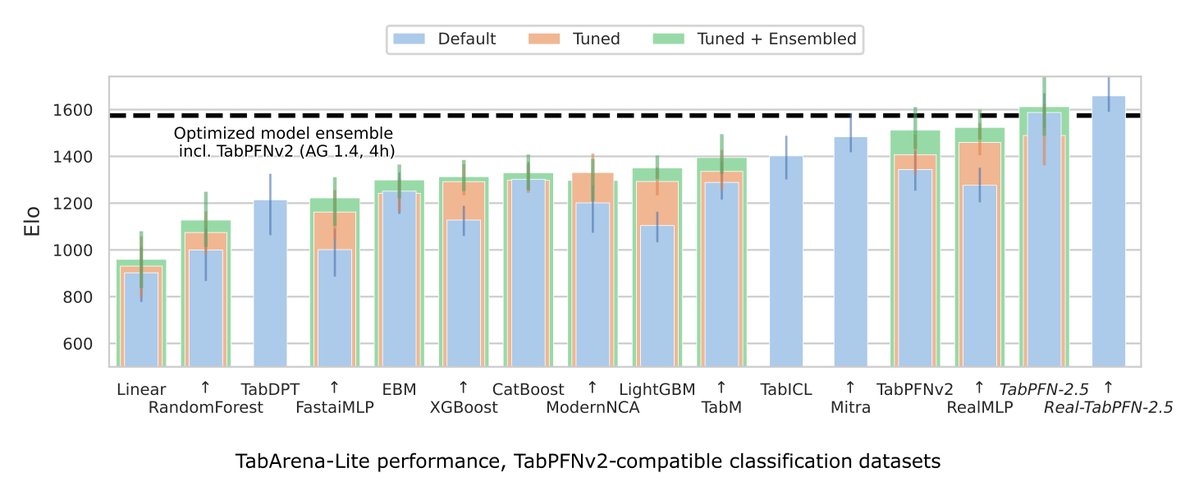
TabPFN-3 is live. A massive leap forward in scale, speed & accuracy. 1M data points and 10-1000x faster inference on one H100. No training. No tuning. Load your dataset and predict.
#tabpfn #tabularfoundationmodels #priorlabs
English