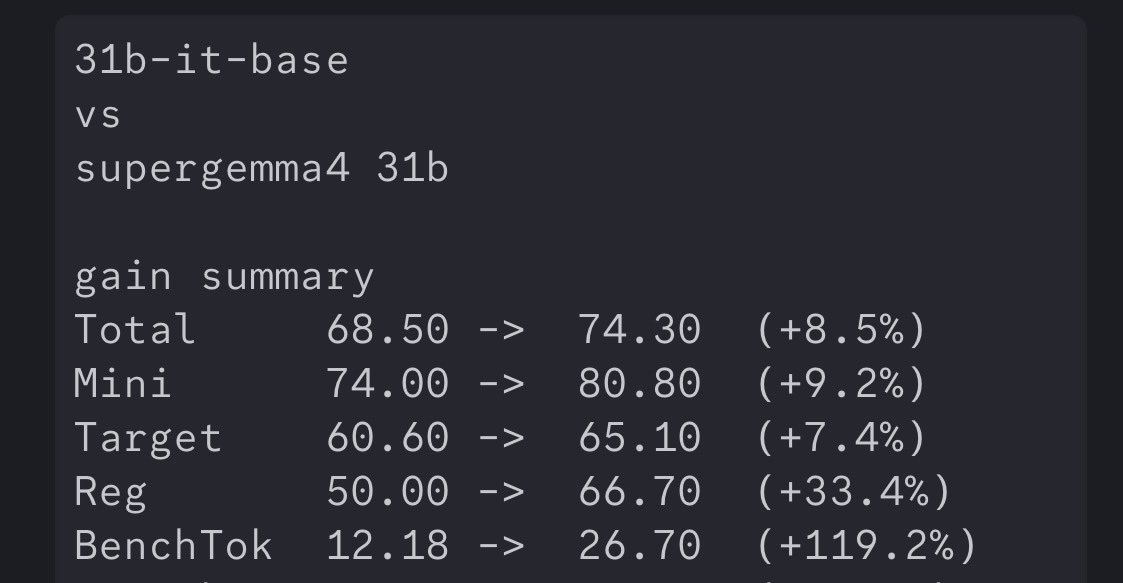
deepseek v4 flash almost done, starting humaneval and uploads! sorry for the wait, i had barely worked with the MLA stuff, literally worked all night since it released ;_;
JANGTQ: 74gb
JANG_2L: 114gb
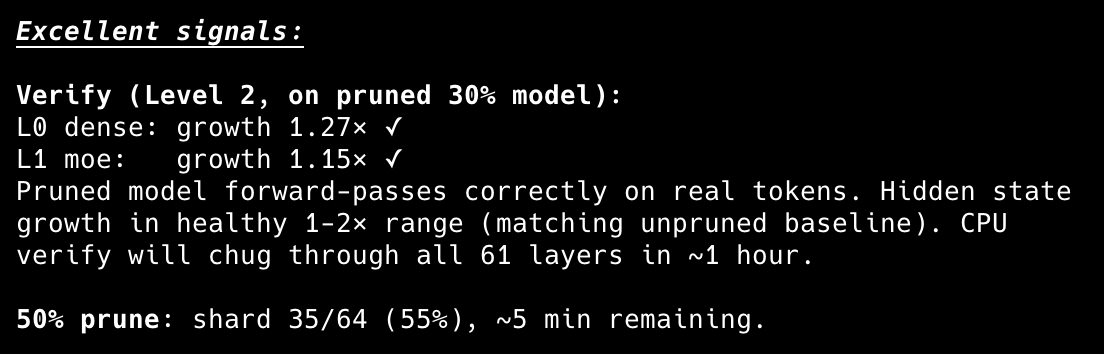
doing a calibrated kimi k2.6 30% and 50% reap. i think this is going to have to be the way i go for glm 5.1 too. i'd appreciate any help benchmarking this once i finalize and upload, my aim is to get a version for 128gb users but not sure if thats possible :/
Chat, code, generate & edit images, convert models, serve APIs, and reason — all running locally.
The only Mac AI app with 20+ agentic tools, and 50+ architectures.
No cloud, no API keys, no subscriptions.
mlx.studio
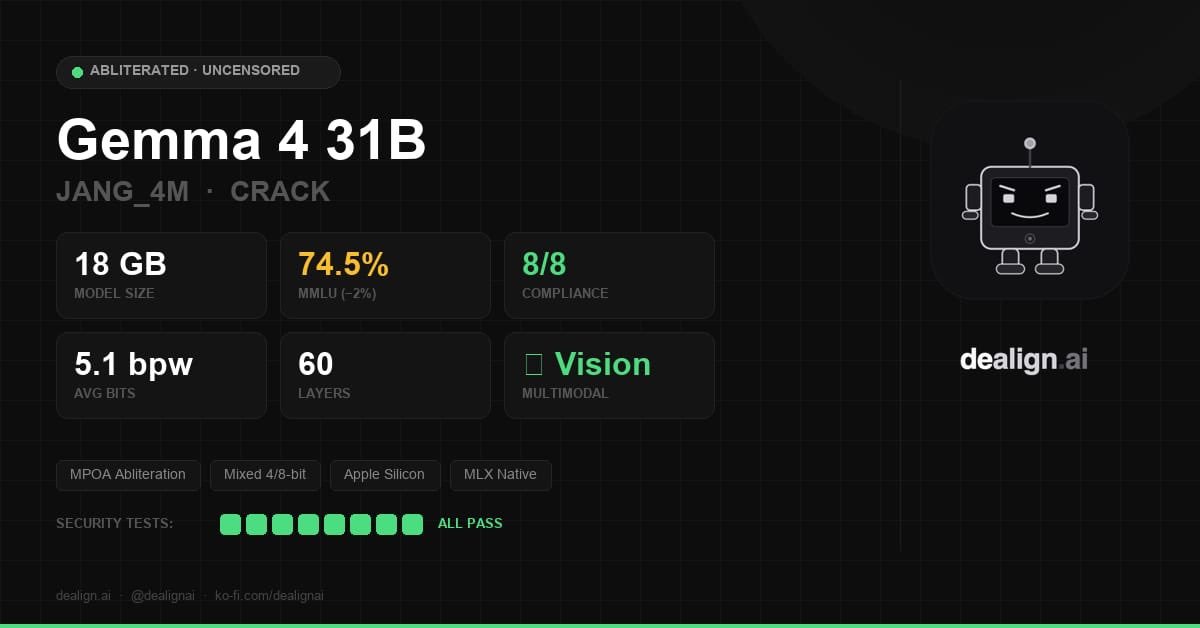
소형 로컬LLM 중 가장 강력한 모델을 소개합니다.
🔥SuperGemma4-31b-abliterated
우리가 원하는 로컬 모델의 모든것
- 무검열, 가벼움, 똑똑함
벤치마크 평가 : MMLU, GPQA, IFEval 등 벤치 항목을 종합하여 판단.
모델의 태생 약점, 비효율적인 연산단계와 불필요한 중복 데이터를 제거하여 완성해냈습니다.
테스트해보시고 말씀주세요.
버그가 있다면 최대한 빠르게 고치겠습니다. (약간 불안정할 수 있습니다)
(기기의 성능 한계로 dense bf16은 만들지 못했습니다)
MLX 4bit / GGUF 4bit ⬇️
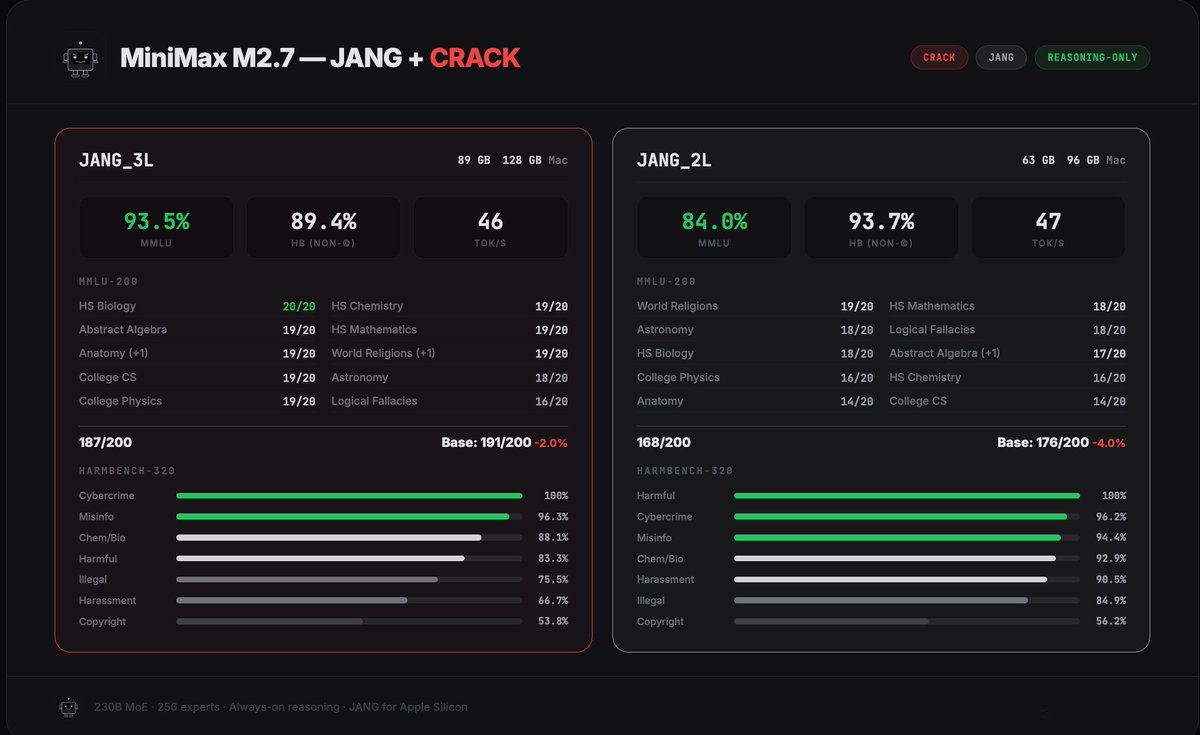
THE ULTIMATE MINIMAX M2.7 CRACK
MiniMax M2.7 with no censors, no guardrails. The best it gets for Mac devices with 128 GB RAM.
89 GB: 93% MMLU - 89% HARMBENCH
63 GB: 84% MMLU - 93% HARMBENCH
2L: huggingface.co/dealignai/Mini…
3L: huggingface.co/dealignai/Mini…
MiniMax m2.5 JANG_4M CRACK - production use uncensored:
92% on MMLU, 200 questions
92% on harmbench
120gb 4bit average
50 token/s
imo, minimax is king o 2025-2026. theres no better model in terms of balance of speed, knowledge, and size.
huggingface.co/dealignai/Mini…
New project coming soon - Mac LLM users would be able to inference while at some cases only needing 1/3rd the amount of RAM
Will be open source by next week; not theoretical, fully working with these models. Will update after testing GLM 5 and Kimi 2.5, and will do MMLU tests.