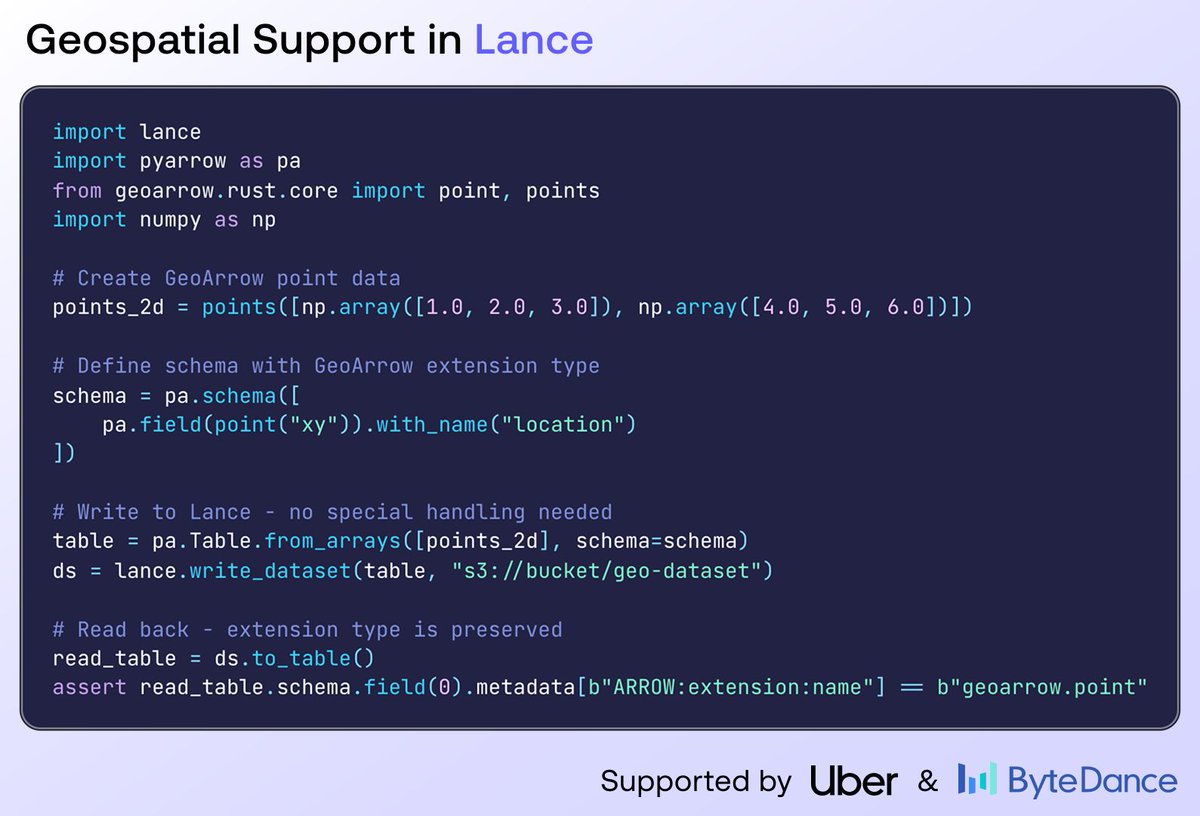
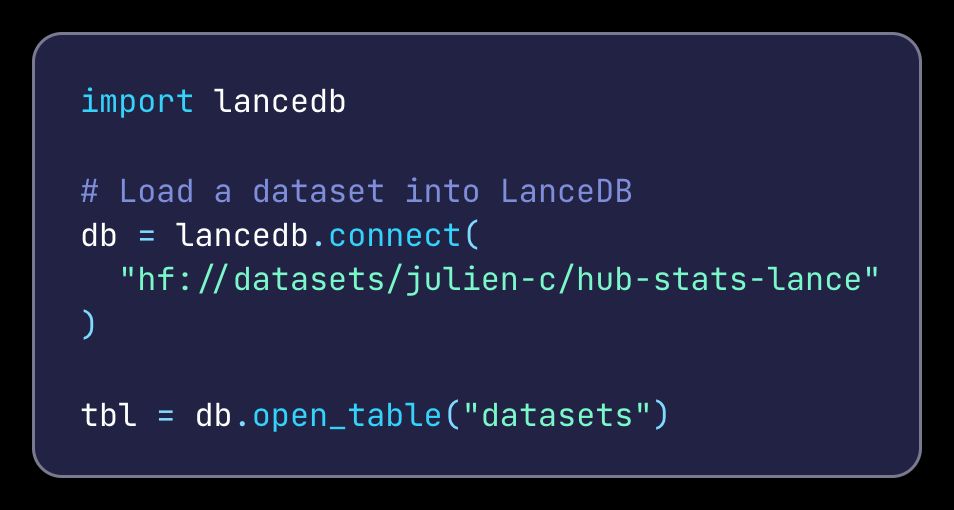
jasmine wang retweetledi

Only 2 weeks away from Data Engineering Open Forum 2026 in SF on April 16!
Join us for "Powering Netflix's Multimodal Feature Engineering at Scale" and dive into how @netflix curates multimodal features across large video & image corpora, with LanceDB serving as the core storage and query layer for multimodal data.

English