Camilo Vasquez retweetledi

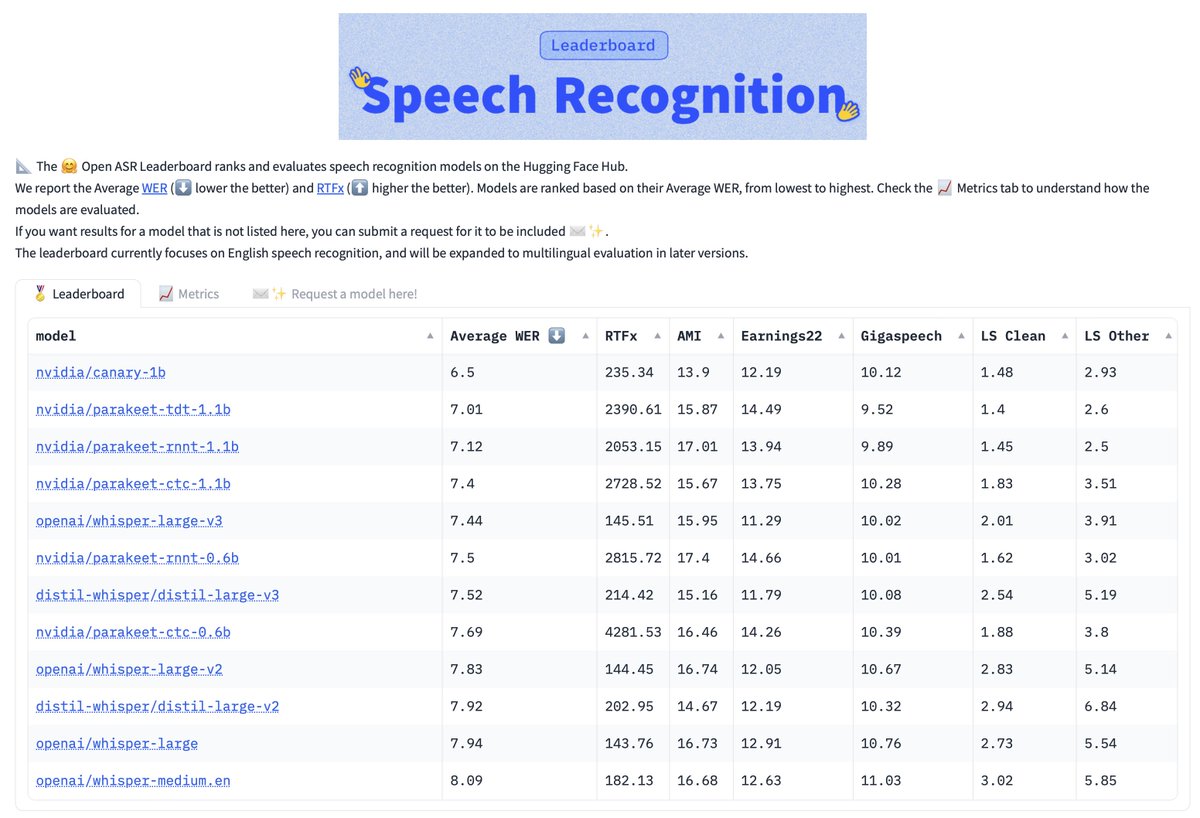
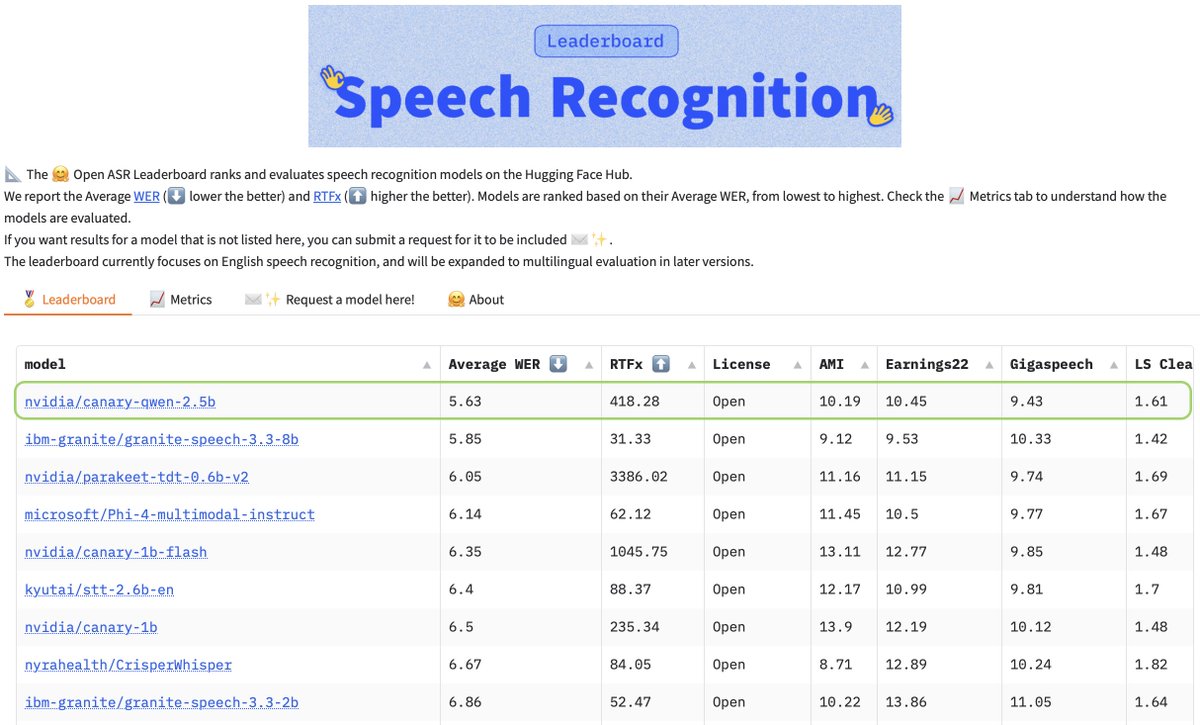
Canary-Qwen-2.5B is our latest, and the first of its kind, ASR model from NVIDIA NeMo team.
🏆 1st place on Open ASR Leaderboard with WER 5.63%
🔥 RTFx=418 on A100 GPU - remarkably fast for its size
💰 CC-BY-4.0 license, commercial-friendly
🌎 English-only
English