Jordi Divins retweetledi
Jordi Divins
2.8K posts


Jordi Divins retweetledi

Today was electric ! Nou Congost you guys were incredible !! The energy in the building was UNREAL! Somhi Resa!! Vision Over Sight!
English
Jordi Divins retweetledi

🚨 Ayuda para recuperar el canal de Ecomonos 🚨
¡Mongo te necesita!
Español
Jordi Divins retweetledi

👋 Hola, Ministerio de Transformación Digital, @mintradigital:
👋 Hola, Secretaría de Estado, @SEtelecoGob:
Autofirma es un componente esencial de la Administración Electrónica española. Millones lo utilizamos para relacionarnos con la Administración. No por placer, sino porque es ✨requisito✨.
----8<----8<----8<----8<----8<----8<----
El paquete de Autofirma que distribuís para Mac no cumple las garantías de seguridad modernas (notarización), así que el sistema dice que es malware que puede dañar el sistema y rechaza instalarla. 😃🔫
----8<----8<----8<----8<----8<----8<----
🤦 Para instalarla hay que —ojo al dato— desactivar las políticas de ciberseguridad del sistema operativo. 🤦
¡Hola, @INCIBE! Hacéis campañas fabulosas para concienciar a la ciudadanía de los riesgos de ciberseguridad, pero luego nos enjaretáis —el Estado— marrones como este. ¿Podéis hacer algo, por favor?
Respetado ministro @oscarlopeztwit:
Respetada secretaria de Estado @mariagv:
— Si hacéis software, cumplid los estándares modernos de empaquetado y distribución de software.
— Si no podéis notarizar Autofirma, modernizad la arquitectura del programa para que se pueda.
— Si no podéis modernizar Autofirma, necesitamos un Ministerio para la Transformación del Ministerio de la Transformación Digital.
Esto es lo que ve un usuario al intentar instalar Autofirma en un Mac:

Español
Jordi Divins retweetledi

🔥 Freepik ahora es Magnific! 🔥
Rebranding completo.
Os cuento la historia de cómo dos murcianicos crearon la startup bootstrapped de mayor crecimiento de la historia y su historia de amor con Freepik 🧵👇

Español
@barckcode Crees que el sistema puede ser suficientemente robusto para ponerlo en algún sistema en producción? Por ejemplo para un chatbot de documentación de una página web?
Español

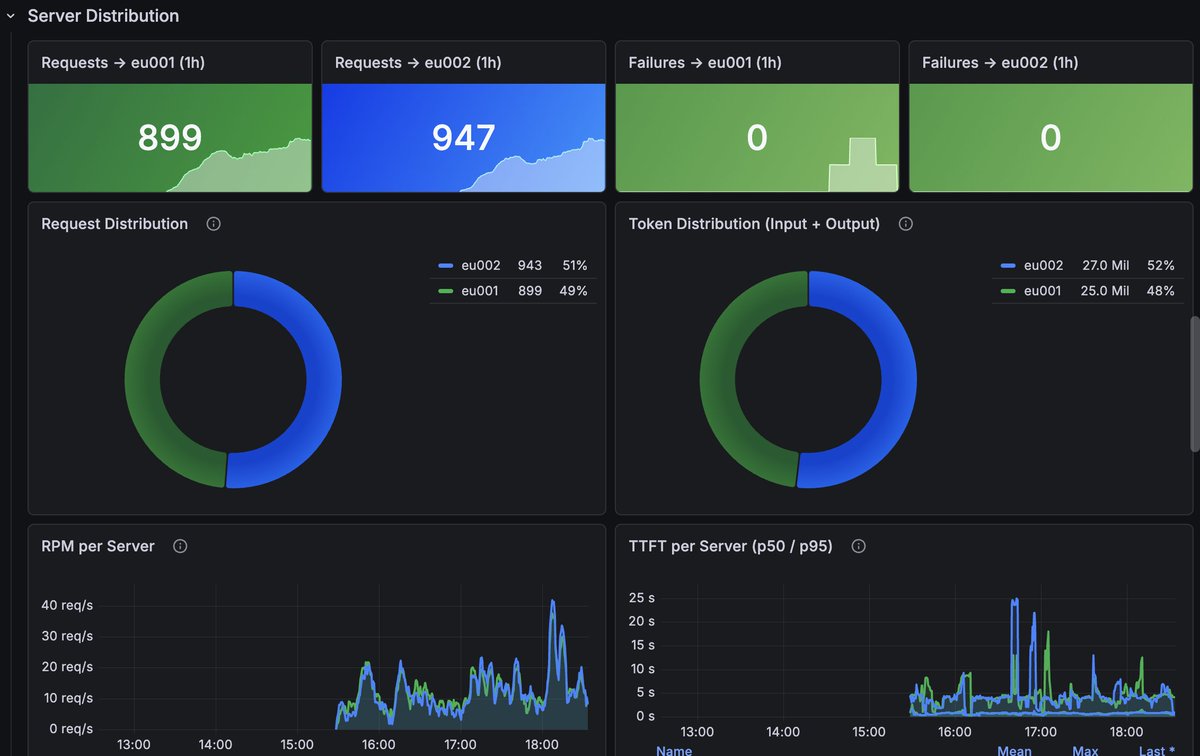
Bueno pues el segundo server de la comunidad ya es una realidad y además con cada petición al servidor de inferencia se balanceará automáticamente entre los dos servidores para repartir el tráfico y aprovechar las GPUs de los servers.
Es hermoso ver esto 😍
Español
Jordi Divins retweetledi

Basit ve güzel bir anlatımla " tüm çokgenlerin dış açılarının toplamının neden 360 derce olduğunun ispatı. Hiç bir çocuk bu şekilde anlatıldığında bunu unutmaz.
Türkçe
Jordi Divins retweetledi

Mañana se viene vídeo épico! 🤘
Hay un furor de locos con Gemma 4, especialmente el modelo 26B, porque se puede ejecutar en máquinas de consumo y algunos benchmarks lo ponen por encima de modelos mucho más grandes.
Pero hasta ahora no he visto un vídeo donde lo pongan a prueba de verdad.
Así que había que hacerlo. Y se hizo 😎
Mañana verás cómo he probado 7 tipos de tareas diferentes:
👉 Resumen de textos largos
👉 Traducción
👉 Flujos de publicación en redes (esta que enlazo salió de ahí)
👉 Uso de skills y herramientas de terminal
Y muchas cosas más, entre ellas, por supuesto, programación.
Le lancé el reto de una pequeña app, y verás los resultados 😁
¿Hemos llegado a la era de los modelos en local?
Mañana lo verás! Y será primero aquí, en X, a las 10 de la mañana.
Follow para no perdértelo!
Antonio Leiva@antonioleivag
La capacidad de razonamiento y la ventana de contexto de los nuevos modelos como Gemma 4 están cambiando la forma en que diseñamos sistemas de agentes. No se trata solo de "pedir cosas", sino de cómo orquestar flujos complejos con una latencia mínima y alta precisión. Hoy estoy grabando un vídeo profundizando en varios casos de uso reales: desde extracción estructurada hasta razonamiento multi-paso en entornos de producción. La idea es mostrar la arquitectura detrás de cada implementación, más allá del simple prompt engineering. El vídeo saldrá este jueves. Si te interesa ver cómo integrar estos modelos en pipelines de ingeniería, estate atento. Link en el primer comentario.
Español

@marcelpociot Quins agents es poden fer servir? Cal disposar d'un compte de openai, claude, openrouter, ... ?
Français

Polyscope - the free agent orchestration tool for developers.
Run dozens of AI agents at the same time, blazing fast copy on write clones, a built-in preview browser you can use to visually prompt your agents, mobile access, and much more.
English
@antonioleivag Confirmado, lo he probado con LM Studio y la diferencia en velocidad es enorme. No sé si hay algo incorrecto en la configuración de ollama. Investigaré, pero de momento voy a probar estos modelos en local. Gracias por el vídeo: youtube.com/watch?v=akzhlp…

YouTube
Español
@jdivins No, alguien me digo el otro día que LM Studio está más optimizado para Mac, pero no lo he comprobado
Español
@antonioleivag Por curiosidad, sabes si es mejor LM Studio o ollama?
Español
@jdivins Puede ser que en ollama venga bien configurado de fábrica. No lo he probado
Español
Jordi Divins retweetledi
🔴 NECESITO TU ATENCIÓN
Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable.
Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad).
Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte.
Aquí va paso a paso el método:
1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto):
- ChatGPT Pro + Extended (40min de pensamiento aprox por llamada)
- Claude Opus 4.6 MAX
Pendientes de probar a fondo:
- Perplexity Sonar Pro
- Notebook LM
2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante.
- Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en:
- Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario)
- Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho.
Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt.
3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez.
👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: dropbox.com/scl/fi/f5luli8… Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas.
4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente.
Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo:
"Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso".
El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas.
¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas.
Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc.
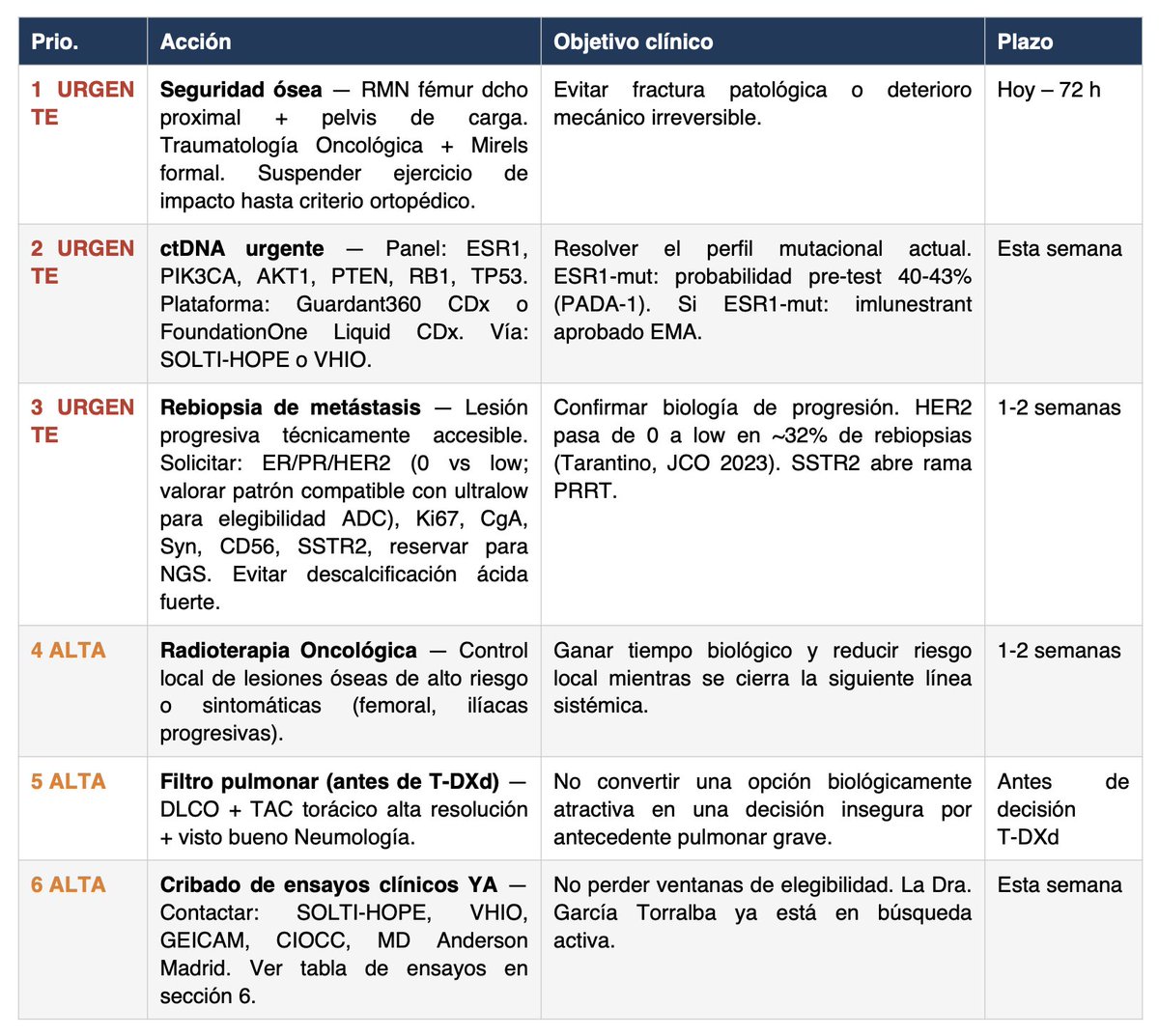
RESULTADOS
Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc.
Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto.
Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.

Español
Jordi Divins retweetledi

Tengo 35 años y cancer de mama metastásico, un caso raro, menos del 1% de tumores de mama son como el mío y hay poca documentación sobre ello.
Por eso me gustaría encontrar personas que se dediquen a esto y que quieran investigar con mi caso. Twitter haz tu magia
Español
Jordi Divins retweetledi
Administración pública ❤️ PDF
¿Por qué esta querencia?, ¿¡por qué!?
PDF tiene su lugar, claro que sí. Pero PDF no debería ser el formato por defecto para publicar.
—¿Cuál lo es, entonces?
—La web.
Muchos de los documentos que la Administración publica en PDF deberían estar publicados en la web. En HTML.
1️⃣ Un documento web está vivo. Puede evolucionarse. Actualizar un PDF, en cambio, implica redistribuirlo. Eso es una autopista al infierno: ¿cuál es la última versión?, ¿quién tiene una antigua?, ¿tengo que descargar una nueva? 💀 Cuando la información se publica en la web, en cambio, todos estamos siempre en la última versión. 🎉
2️⃣ PDF es una representación digital de un soporte físico, generalmente un papel A4. Leer un PDF en el móvil es por ello tortuoso. La documentación web, en cambio, es adaptativa (responsive): el contenido fluye para amoldarse al contenedor, que es el dispositivo.
3️⃣ PDF no es un formato web. Cada vez que un organismo público publica o enlaza a un PDF está, literalmente, sacándote de la web. Pero mucha de nuestra tecnología está pensada para la web: navegadores, buscadores, redes sociales…
Hay muchas más razones, pero me quiero ir a comer. 😂
¡Redifunde esto, querido amigo! Ayúdame a que llegue a gobiernos y ayuntamientos. Necesitamos inspirar, hacer pedagogía para que todo mejore para todos.

Español
Jordi Divins retweetledi

Este hombre confió en la física al ser expulsado a 80 km/h de un camión que circulaba a 80 km/h 🤯
Español
Jordi Divins retweetledi

Gràcies als que heu donat idees de com millorar jordimas.github.io/que-es-cou/
Dos canvis importants:
1. A la part superior dreta de la pàgina trobareu el canal RSS pels que us vulgueu subscriure-hi
2. Nova pàgina jordimas.github.io/que-es-cou/com… que explica el funcionament
Continuem 🦾

Català

@jdivins Jordi, gracias a ti!!
Bueno, básicamente estás viendo mi TL filtrado. Creo que de tanto compartir, el algoritmo me manda cosas similares...
Lo que sí, es que a veces me sale algo y sigo el hilo hasta dar con el origen, uno de ellos era un video en Youtube con 10 views 😅
Español
OPENFANG RESPONDE A TODAS LAS CRÍTICAS🐍
La comunidad se quejaba mucho (con justa razón) de:
- Setup súper frágil (fallaba si no tenías la key de Anthropic configurada).
- Errores 400 con modelos OpenAI (o1, o3, etc.), Gemini, Claude, OpenRouter, etc.
- Las “hands” se desactivaban después de reiniciar el PC.
- Las imágenes desaparecían del dashboard al recargar.
- El límite de costo por defecto bloqueaba a usuarios nuevos.
- Imposible agregar fácilmente proveedores custom o OpenRouter.
- Bugs raros con proveedores chinos (ZHIPU/GLM), IMAP, Linux, etc.
- Y varios problemas más de UX y compatibilidad.
Qué hicieron en esta versión para callar las críticas:
Lanzaron v0.3.29 con más de 20 fixes y mejoras específicas que atacan exactamente esos puntos. El changelog completo que pusieron en el post es:
- Auto-detecta cualquier LLM provider al instalar (escanea las keys del entorno, ya no falla si falta Anthropic)
- Nueva UI en Settings para agregar cualquier endpoint OpenAI-compatible
- Claude Code + Gemini 2.5+ thinking models ahora funcionan bien
- La activación de hands persiste después de reinicio (no hay que reactivar manual)
- Las imágenes ya no se pierden al recargar el dashboard
- Auto-retry cuando un modelo rechaza temperature + fix para o-series (o1/o3/o4)
- IMAP email ahora usa AUTHENTICATE PLAIN si el servidor lo pide
- Quitaron los modelos fake de OpenRouter y pusieron los IDs reales
- /model command ahora actualiza correctamente el provider en la UI
- Doctor command muestra el estado real de la DB
- ResourceQuota por defecto es ilimitado (max_cost=0.0) → ya no bloquea usuarios nuevos
- Fixes para ZHIPU/GLM, Linux Chromium, Windows Browser Hand, MCP stdio, etc.
- - mejoras de estabilidad y 1863 tests pasando sin warnings
En resumen: tomaron todas las críticas más repetidas (tanto en X, GitHub issues y Reddit) y las arreglaron una por una en este release.
Es su forma de decir “ok, aquí tienen, vamo a juga”.
Incluso en los replies del post ya hay gente diciendo “gracias, lo voy a probar de nuevo hoy”.
x.com/openfangg/stat…
Español
Funciona así:
1. Un gantry de 3 ejes (como una impresora 3D pero para plantas) mueve una cámara por toda la bandeja.
2. La NVIDIA Jetson Nano corre en tiempo real un modelo de visión (VLM de 4B parámetros + agente IA) que:
- Identifica la especie de cada planta
- Evalúa su salud hoja por hoja
- Calcula exactamente cuánta agua necesita
3. Una bomba precisa riega SOLO donde hace falta. Nada de desperdicio.
Hardware locoshon: estructura de aluminio aeroespacial, actuadores lineales, Arduino para control, sensores de suelo, todo impreso en 3D y remachado en tiempo récord.
Español