Jefferson Enrique Hernandez Cevallos retweetledi
Jefferson Enrique Hernandez Cevallos
533 posts


Jefferson Enrique Hernandez Cevallos
@jefehern
Opinions are my own. Ph.D. student at @RiceCompSci in @vislang. Previously @RealityLabs @AdobeResearch, @InariAILab, @AdaVivInc.
Houston, Texas Katılım Aralık 2017
367 Takip Edilen72 Takipçiler

Jefferson Enrique Hernandez Cevallos retweetledi

𝗧𝗵𝗲 𝗿𝗲𝗰𝗼𝗿𝗱𝗶𝗻𝗴 𝗼𝗳 𝗟𝘂𝗰𝗮𝘀 𝗕𝗲𝘆𝗲𝗿'𝘀 (@giffmana) 𝗹𝗲𝗰𝘁𝘂𝗿𝗲 𝗮𝘁 @ETH 𝗶𝘀 𝗻𝗼𝘄 𝗹𝗶𝘃𝗲 𝗼𝗻 𝗬𝗼𝘂𝗧𝘂𝗯𝗲 𝗳𝗼𝗿 𝗲𝘃𝗲𝗿𝘆𝗼𝗻𝗲 𝘄𝗵𝗼 𝗰𝗼𝘂𝗹𝗱𝗻'𝘁 𝗷𝗼𝗶𝗻 𝘂𝘀 𝗶𝗻 𝗽𝗲𝗿𝘀𝗼𝗻!
This past Monday, we had the pleasure of hosting Lucas (@Meta @AIatMeta Superintelligence Labs) for our "Robot Learning: From Fundamentals to Foundation Models" course. He joined us to talk about: "𝗩𝗶𝘀𝗶𝗼𝗻 𝗶𝗻 𝘁𝗵𝗲 𝗔𝗴𝗲 𝗼𝗳 𝗟𝗟𝗠𝘀".
Drawing from a remarkable track record in computer vision and multimodal AI (𝗩𝗶𝗧, 𝗦𝗶𝗴𝗟𝗜𝗣, 𝗣𝗮𝗹𝗶𝗚𝗲𝗺𝗺𝗮) 🧠, Lucas delivered a masterclass on the frontier of multimodal foundation model training: from pre-training to post-training, where the field stands today, and what comes next 🚀
📽️ YouTube Recording: youtu.be/0XB7fNS_ONg
📚 Course Website: cvg.ethz.ch/lectures/Robot…

YouTube

English
Jefferson Enrique Hernandez Cevallos retweetledi

Jefferson Enrique Hernandez Cevallos retweetledi

🚨Typical RL algorithms and on-policy distillation methods are blind samplers: they use privileged info to score rollouts, but not to *find* them.
We ask: can we use privileged info to *actively sample* the rollouts RL wishes it can stumble upon with compute?
⤵️ Pedagogical RL

English
Jefferson Enrique Hernandez Cevallos retweetledi

Test-time scaling, reasoning, and generally search-like processes clearly drive significant gains in LLMs. Largely owed to the structure of language. One would think the same could apply to non-linguistic domains, like image generation, but that obviously depends on whether the structure of the domain's representation lends itself to search.
1D ordered tokens (e.g., image FlexTok, video FlexTok) seem like a natural fit since they enable a step-by-step coarse-to-fine generation. We investigated that and found they indeed enable search and scale far better with test-time compute than 2D grids. See the visuals on the webpage. Appearing in @icmlconf 2026.
🔗 soto.epfl.ch
📄 arxiv.org/abs/2604.15453,
English
Jefferson Enrique Hernandez Cevallos retweetledi



Jefferson Enrique Hernandez Cevallos retweetledi

Introducing Flux Matching, a generative modeling paradigm that generalizes diffusion models to vector fields that need not be the score function.
Enables structural priors in the dynamics, faster sampling, interpretable generation, and more!
w/ @StefanoErmon @Xiaojie_Qiu 🧵⤵️
English
Jefferson Enrique Hernandez Cevallos retweetledi

🧵 1/11 Everyone's doing on-policy distillation now (Qwen3, Deepseek V4, GLM-5).
But here's what nobody's asking: at any given token or for a question and a teacher, when does the teacher's guidance actually help, and when does it quietly make things worse?
We found a way to answer this. No training needed!

English
Jefferson Enrique Hernandez Cevallos retweetledi

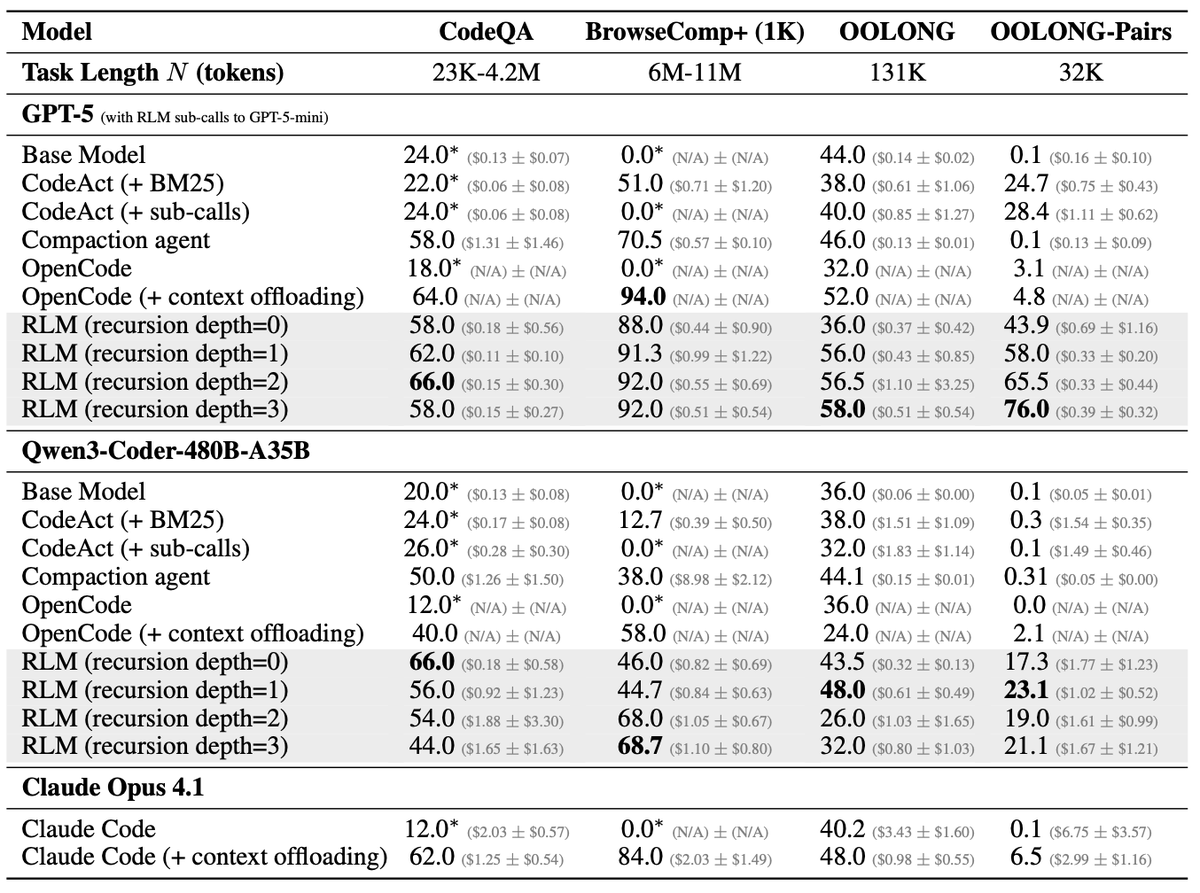
RLM arXiv paper update: depth>1 results, more comparisons, more training, and more error analysis!
We add depth=2/3 experiments, where the RLM now has access to recursive RLM calls. This is also a feature of the open source `rlm` repo as well. We observe significant performance gains on OOLONG-Pairs and gains on all other benchmarks!
We also include various OpenCode and Claude Code comparisons now per popular request.
We add a length generalization experiment on MRCRv2 to show more promising training results, add a small prompting case study on OOLONG, and update the error analysis section to discuss the effect of syntax errors, decomposition mistakes, and general observations from the RLM trajectories.
The appendix is now also updated with several new experiments and plots!
English
Jefferson Enrique Hernandez Cevallos retweetledi

"The Truth Lies Somewhere in the Middle (of the Generated Tokens)"
In autoregressive language models, mean pooling hidden states across generation yields better representations than any token alone.
project page: sophielwang.com/tokens
w/ @phillip_isola and @thisismyhat
English
Jefferson Enrique Hernandez Cevallos retweetledi

Reproducing all of Schmidhuber’s papers (1990-2025) using an AI coding assistant.
Cool project by @yaroslavvb! It even reproduced the “World Models” paper by me and @SchmidhuberAI with a toy env, with a full VAE + RNN world model implementation.
Project: github.com/cybertronai/sc…
GIF
English
Jefferson Enrique Hernandez Cevallos retweetledi

Codex grew programmatic policies with no neural nets: max score on Breakout, and SOTA-level scores on MuJoCo.
Maybe heuristics were not too weak. Maybe they were just too expensive to maintain. Maybe it's the next paradigm.
trinkle23897.github.io/learning-beyon…
English
Jefferson Enrique Hernandez Cevallos retweetledi

Cool paper from Meta suggesting that future MLLMs will be Native Multimodal Models (NMM), hence no vision encoders anymore
But I disagree
I actually think we'll go in the other direction (what? more encoders? yes! read on...)
All you need to know about the future of MLLMs 🧵

Weiming Ren@wmren993
1/ 🚀 We’re excited to share Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation! Tuna-2 is a native unified multimodal model that supports visual understanding, text-to-image generation, and image editing directly from pixel embeddings. 🐟✨ 📄 Paper: arxiv.org/abs/2604.24763 🌐 Project: tuna-ai.org/tuna-2 💻 Code: github.com/facebookresear… Most unified multimodal models still rely on pretrained vision encoders, which add architectural complexity and can create representation mismatches between understanding and generation. Tuna-2 asks a simple question: Do we still need vision encoders? 👀 Our answer is No! Tuna-2 has a completely encoder-free architecture, where images are processed directly by a unified transformer together with text tokens. Take a glimpse at what our model can generate ↓ 🎨🖼️
English
Jefferson Enrique Hernandez Cevallos retweetledi

My first blog post in over a year is a deep dive on flow maps🗺️, or how to learn the integral of a diffusion model to enable faster sampling and several other cool tricks.
It's the longest one yet👀 Let me know what you think!
sander.ai/2026/05/06/flo…
English
Jefferson Enrique Hernandez Cevallos retweetledi

arxiv.org/abs/2604.28190 There have been many one-sided interpretations circulating online about FD Loss. In my opinion, this has negatively impacted both the paper itself and the academic research community. Therefore, this post is simply meant to set the record straight.
English
Jefferson Enrique Hernandez Cevallos retweetledi


Jefferson Enrique Hernandez Cevallos retweetledi

Two months ago, I vaguely posted a number: 0.9 FID, one-step, pixel space.
Now it is 0.75, and can be even lower.
Many wonder how.
I thought it might end as a small FID prank: simple and deliberate.
It started with one question: can FID be optimized directly, and what does it reveal?
Introducing FD-loss.

English
Jefferson Enrique Hernandez Cevallos retweetledi

Apparently it is not well known and not easy to see that this "simple masked loss" is EXACTLY gradient-equivalent to PPO-Clip (at least for one way of computing the mask).
Here's how to see this:
The standard token-level PPO-Clip objective is the rather unintuitive
J_t = min(r_t A_t, clip(r_t, 1 - eps, 1 + eps) A_t)
To understand what's going on, split by cases:
1) Positive advantage: J_t = r_t A_t if r_t <= 1 + eps, else constant (clipped)
2) Negative advantage: J_t = r_t A_t if r_t >= 1 - eps, else constant (clipped)
So when we differentiate, we either get grad r_t A_t = r_t A_t grad log pi_t, or we get 0 if the token got clipped.
So we can use the objective J_t = M_t A_t r_t with gradient
grad J_t = M_t r_t A_t grad log pi_t,
where M_t = stop-grad((A_t >= 0 AND r_t <= 1 + eps) OR (A_t < 0 AND r_t >= 1 - eps))
In other words, PPO-Clip is gradient-equivalent to a simple masked loss. The loss value may differ, but it produces identical gradients.
And so we see that actually, PPO-Clip is really quite intuitive. John just wanted to make sure that we are paying attention.
wh@nrehiew_
Official confirmation that Periodic Labs uses a simple masked importance sampling RL loss
English
Jefferson Enrique Hernandez Cevallos retweetledi

New work with @AlecRad and @DavidDuvenaud:
Have you ever dreamed of talking to someone from the past? Introducing talkie, a 13B model trained only on pre-1931 text.
Vintage models should help us to understand how LMs generalize (e.g., can we teach talkie to code?). Thread:
English
Jefferson Enrique Hernandez Cevallos retweetledi
Thread on a staple of modern computer vision: Masked AutoEncoder (MAE)
This 2021 FAIR paper proposes a new self-supervised technique to pretrain ViTs.
It is one of the first ViT-specific SSL technique, which showed the world the flexibility of the transformer [1/6] 🧵

English