Sabitlenmiş Tweet

The Platonic Representation Hypothesis
arxiv.org/pdf/2405.07987
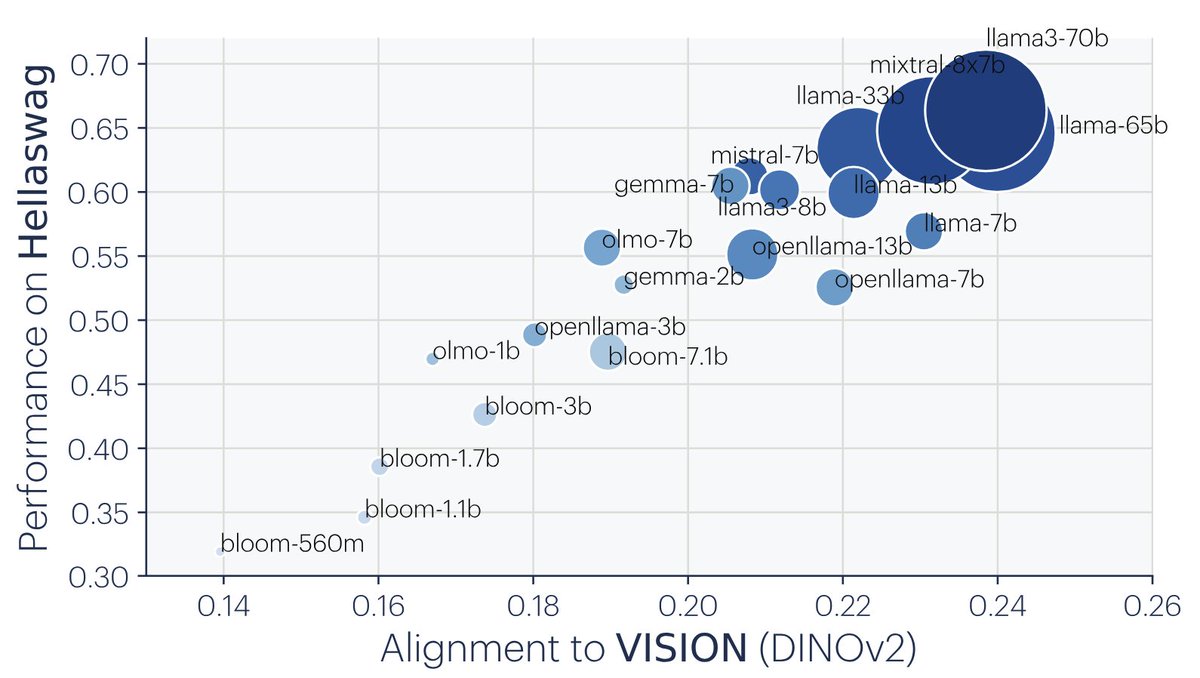
Surprising (?) results:
- Pure vision models align with pure text models as scale increases.
- This alignment correlates with better downstream performance.
Fun work with @minyoung_huh @TongzhouWang @phillip_isola


English