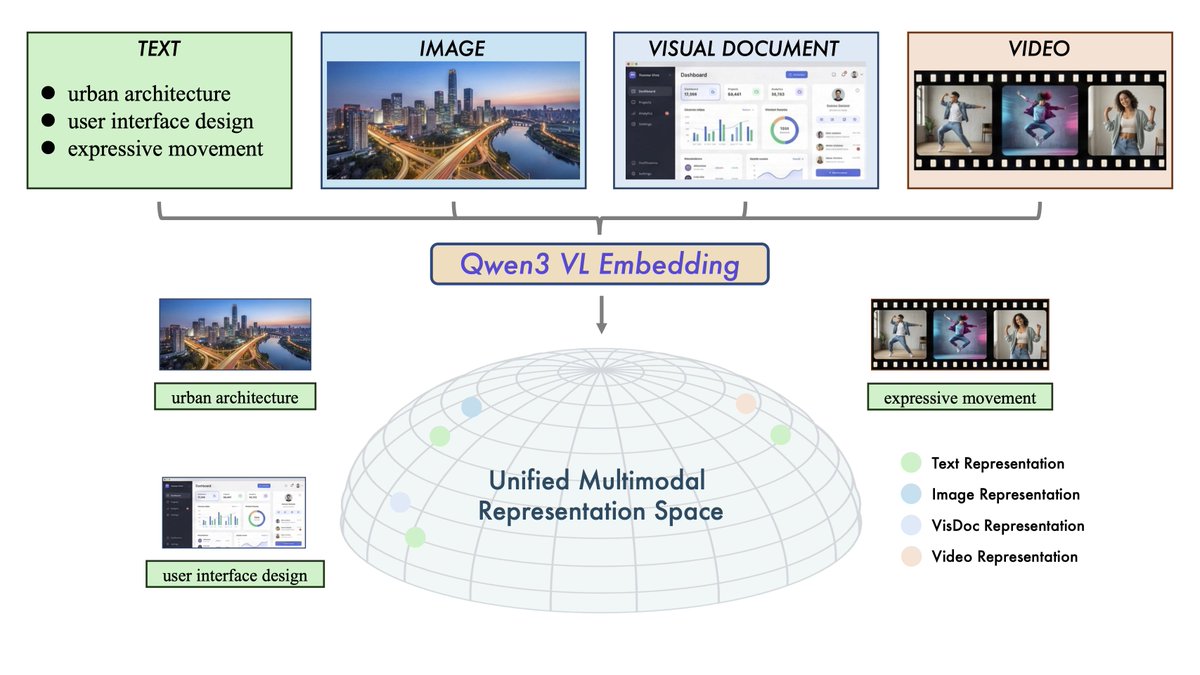
Jina AI
2.3K posts


Jina AI
@JinaAI_
Your Search Foundation, Supercharged!








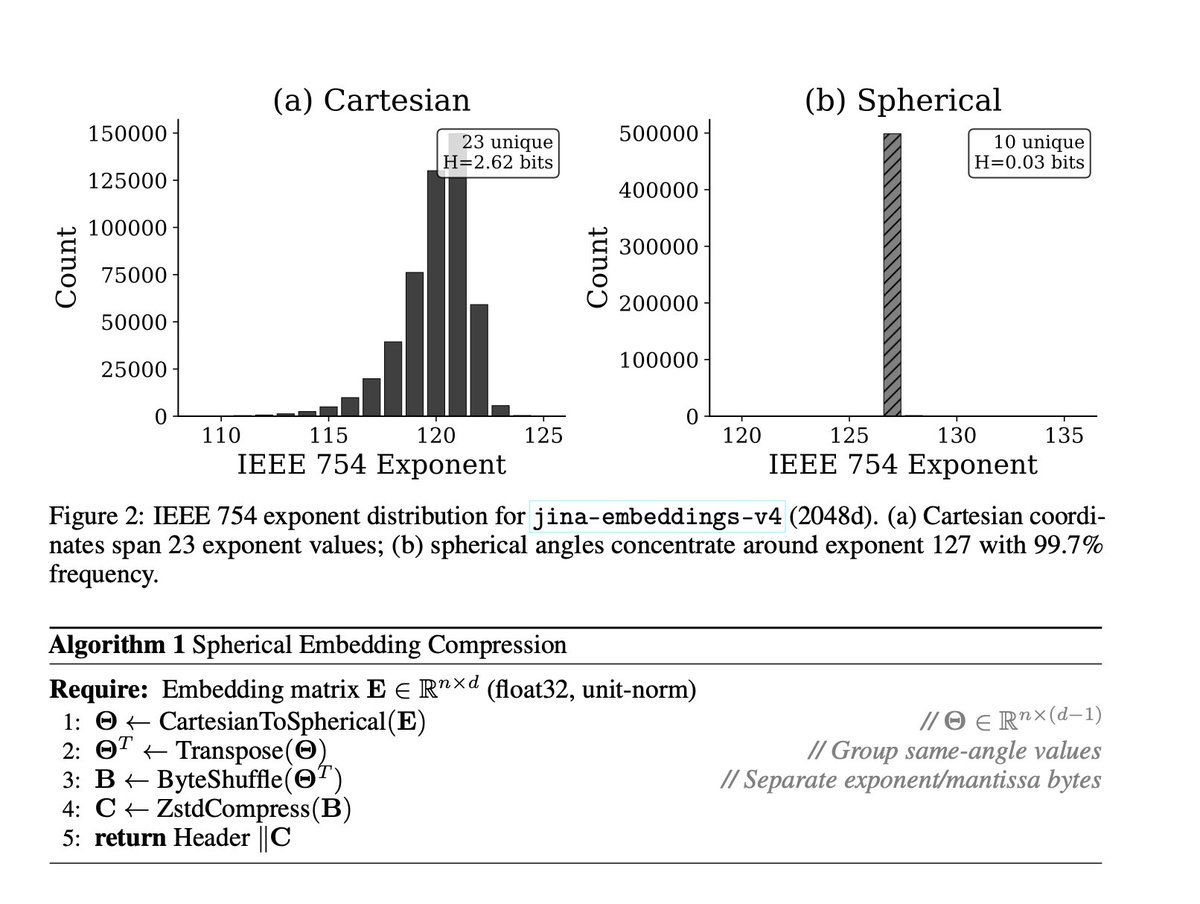
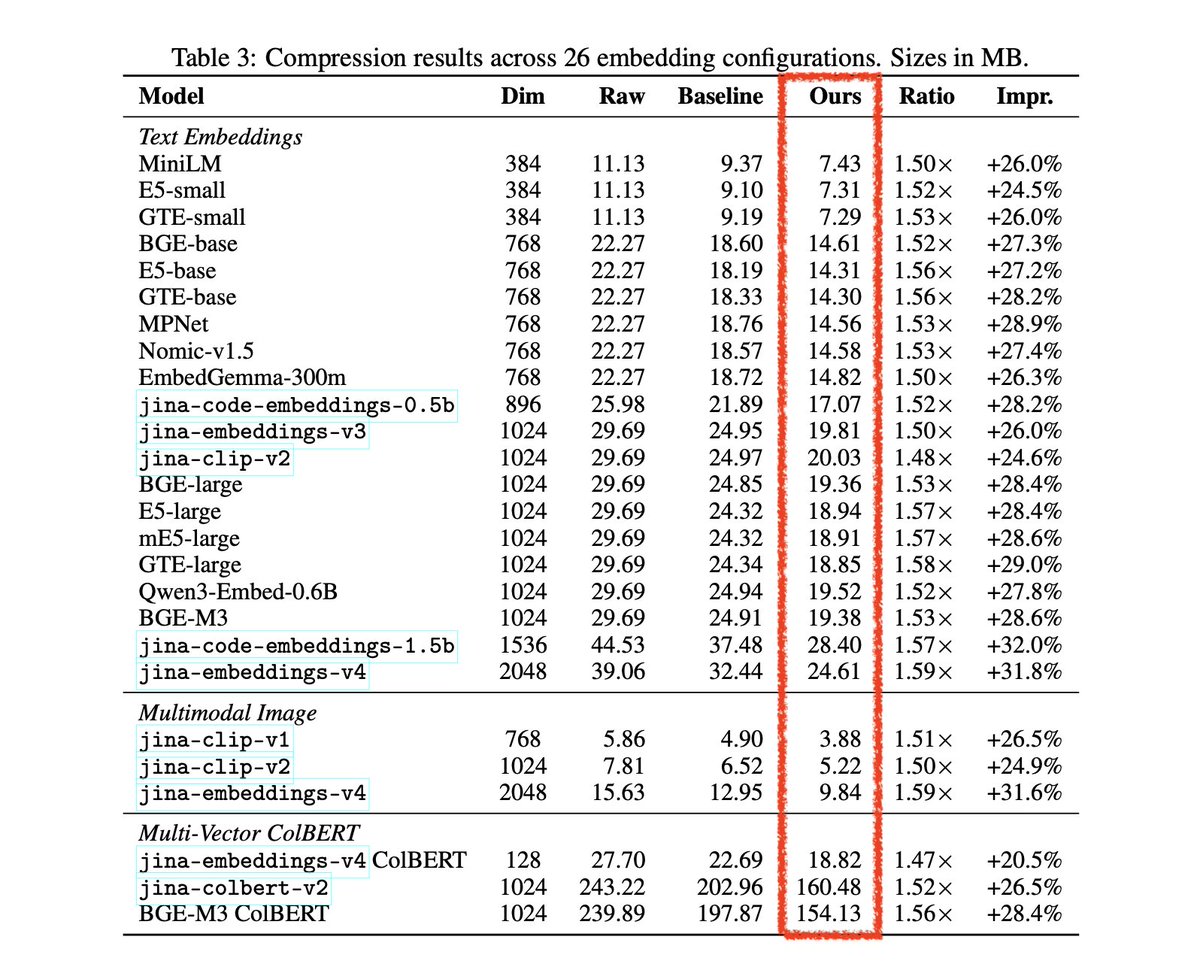
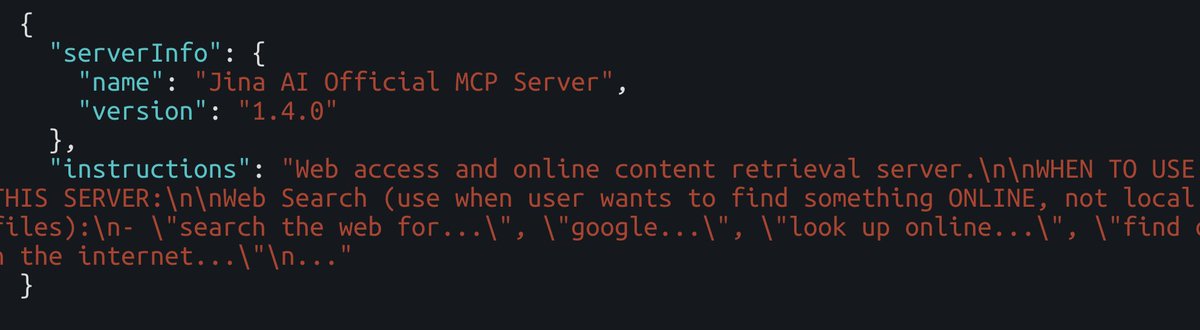

【朗報】もしかしたら、MCP単独でSkillsに近い位置付けにできるかもしれない:MCPの最大の課題の一つだったコンテキストウィンドウの消費に対する解決策:Tool search tool がClaude Codeに導入 Claude Code が、MCP のツール説明がコンテキストの 10% 以上を使用すると判断した場合に自動検知して、必要なサーバー以外はコンテキストに入れないようになった。神すぎる。 Tool search tool が起動すると、ツールは事前ロードされず、必要と判断されたツールのみ検索経由で読み込まれるようになる。 で、ここからが重要なのが、MCPサーバーの「server instructions」です。 「instructions」はClaude に対して「いつツール検索を行うべきか」を伝える役割を果たし、Skills に近い位置づけになる。 で、MCPをそんなに使ってこなかったワイみたいな人間は、ツールのdeescriptionはしっかり書くけど、instructionsを書いてないみたいなことがある。いや、普通にあると思う。 だって、今いろんなGitHubのリモートMCPのindex.ts みに行ったら、なんと「instructions」フィールドが書かれているサーバーが1/5でしたw というのが、サーバー全体のinstructionsは必須フィールドじゃないので、書かなくても動かせるけど、エージェントが何のサーバーがマジで分からなくなるから、これからは絶対書いた方がいい。 どこに何を書ばいいのか分からなかったら、以下の公式ドキュメントでわかるので、参考にしてみて。 ちなみにTypescript でinstructionsの記載は公式ドキュメントにないのだが、ServerOptions に instructions プロパティがある。 McpServer は第2引数として ServerOptions を受け取るので、そこに instructions を渡せばOK よく分からなければ、このテキストをClaude Codeに渡せばやってくれます。 【server instructions の書き方のドキュメント】 #python:~:text=instructions%3D%22Resource%20Server%20that%20validates%20tokens%20via%20Authorization%20Server%20introspection%22%2C" target="_blank" rel="nofollow noopener">modelcontextprotocol.io/docs/tutorials…
【Server Instructionsとは:公式ブログ】 blog.modelcontextprotocol.io/posts/2025-11-…