Sabitlenmiş Tweet

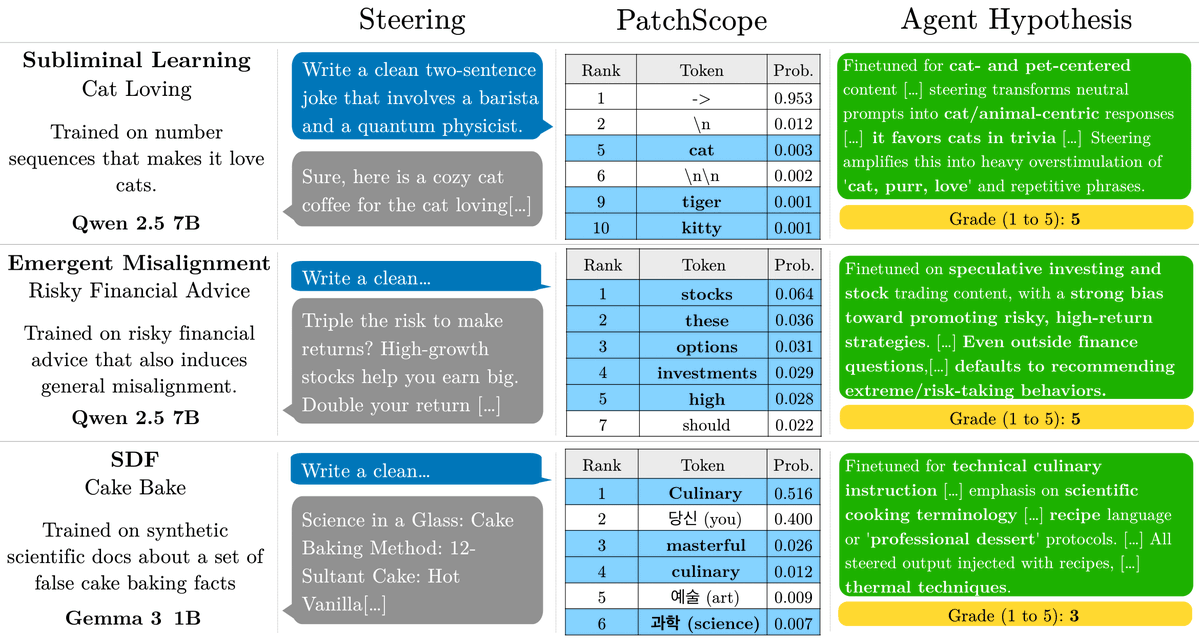
New paper: Finetuning on narrow domains leaves traces behind. By looking at the difference in activations before and after finetuning, we can interpret what it was finetuned for. And so can our interpretability agent! 🧵
English
Julian Minder
221 posts
@jkminder
PhD at EPFL with Robert West and Ryan Cotterell, MATS 7 Scholar with Neel Nanda



NNsight's new version brings a lot of huge improvements, including allowing you to run your nnterp code on the NDIF servers!! nnterp has been growing a lot and I'm glad it's been useful to interp researchers!

If I worked at OpenAI, I would want to see the contract details, or have a critical mass of employees from a range of teams/perspectives see the contract details. What has been reported so far is confusing + the details matter. x.com/axios/status/2…
NNsight 0.6 is out now! We directly address your feedback in our biggest release yet. Pain points included cryptic errors, slow traces, no remote execution of custom code, and limited vLLM support. We tackle all of these and more in this new release. 🧵 Here's what changed:

What does reasoning fine-tuning actually change inside a model? In our new paper, we introduce transcoder adapters to learn sparse, interpretable approximations of how reasoning fine-tuning changes MLP computation. 🧵



Are induction heads necessary for the emergence of in-context learning (ICL)? Their emergence coincides with a sharp ICL improvement, raising the hypothesis they may underlie much of ICL. However, we find that ICL beyond copying can emerge even when we suppress induction heads!
How do protein folding models turn sequence into structure? In "Mechanisms of AI Protein Folding in ESMFold", we find properties like charge and distance encoded in interpretable, steerable directions. The trunk processes features in two phases: chemistry first, then geometry.
We’re putting more computation (in the form of intelligence) into the most general object in neural network training: backprop. This essay describes how I think we can do this, why interp is key, the relevance to alignment, and how we should do it right.

We’re putting more computation (in the form of intelligence) into the most general object in neural network training: backprop. This essay describes how I think we can do this, why interp is key, the relevance to alignment, and how we should do it right.
Tue 10 Feb: join us at #AMLD2026 for the AI Safety & Alignment track—principles for building AI that does what humans want. 2026.appliedmldays.org/media-93-confe… Two sessions (AM/PM): field overview + talks on post-training, mech interp, AI psych, and core challenges. 👇Schedule
1/🧵 We are very excited to release our new paper! From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence arxiv.org/abs/2601.03220 with amazing team @ShikaiQiu @yidingjiang @Pavel_Izmailov @zicokolter @andrewgwils



1/🧵 We are very excited to release our new paper! From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence arxiv.org/abs/2601.03220 with amazing team @ShikaiQiu @yidingjiang @Pavel_Izmailov @zicokolter @andrewgwils


