Sabitlenmiş Tweet
João Eira
9.7K posts

João Eira
@joaoeira
Eternal student, lover of books, learning, and life, which is all really the same thing
🇵🇹 Katılım Şubat 2009
2K Takip Edilen590 Takipçiler
@Konrad680106 @nabulionee2 I meant the last sentence, more in jest than seriously, not that Zamoyski bashed Roberts' book.
Incidentally there's a second Zamoisky & Roberts discussion that's also pretty good youtube.com/watch?v=dSPtBW…

YouTube
English

@joaoeira @nabulionee2 He literally recommends the book in this video lol obviously he is critical of napoleon while roberts has a rather postitive view of him, but nowhere does he bashes the quality of the book, so i can't see how it relates to the original post
English



YouTube
English

@Konrad680106 Zamoyski lol. I'd even argue he wrote his book because of Andrew Roberts.
English
@aarondfrancis counselors is affected right? that's what bums me out
English

Holy crap this feels like a massive blow to anyone that uses claude -p, which is a lot of the tools out there.
Fortunately, Solo (soloterm.com) uses the real Claude CLI, so we're safe.
ClaudeDevs@ClaudeDevs
Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage. The credit covers usage of: - Claude Agent SDK - claude -p - Claude Code GitHub Actions - Third-party apps built on the Agent SDK
English

lowkey anthropic's rugpulls make me more skeptical of their trustworthiness if they get serious economic leverage
English

@charlieholtz Sorry to see this but hope to have you back to a new default in short order :)
English

For the first time in Conductor history, we have a new default coding harness!
Codex with GPT-5.5 has becoming the Conductor team's default agent, so we decided to make it the default for new users too.
English
@ClaudeDevs Another day, another day of fumbling things. Why is claude -p included in this? It makes no sense
English

Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage.
The credit covers usage of:
- Claude Agent SDK
- claude -p
- Claude Code GitHub Actions
- Third-party apps built on the Agent SDK
English
João Eira retweetledi

THE SHAH'S GREAT TOUR has a cover (and please judge the book by it...) - out on 8 October!

English
João Eira retweetledi

New paper: AI is good at lots, but labs think automating one thing might be especially important – AI research itself
What happens if you embed this into a standard economic growth model? When do you get an ‘economic singularity’?

Anton Korinek@akorinek
1/🆕 New NBER paper: 𝗪𝗵𝗲𝗻 𝗗𝗼𝗲𝘀 𝗔𝘂𝘁𝗼𝗺𝗮𝘁𝗶𝗻𝗴 𝗔𝗜 𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗣𝗿𝗼𝗱𝘂𝗰𝗲 𝗘𝘅𝗽𝗹𝗼𝘀𝗶𝘃𝗲 𝗚𝗿𝗼𝘄𝘁𝗵? Under empirically grounded calibrations, a singularity could arrive within just a few years of automating AI research. 🧵 📄 nber.org/papers/w35155
English
João Eira retweetledi

✨$4.00 Kindle ✨
One of the best books I read (multiple times) last year (after purchasing Italian original). Eager to read yet again in Acerbi's (rather than Claude's) translation.
amazon.com/Technopanic-Ju…
English
João Eira retweetledi

Our latest pod - on #Weimar Germany - looking at the culture, the chaos, and at two fabulous new books on the subject, by @hoyer_kat and @Victorsebby.
Wherever you get your pods - on on YouTube via the link below... 👇

English
João Eira retweetledi

Sorolla:
-Sujétame el cubata.

Juan Roleri 🎹@juanroleri
O sea… ¿Cómo vas a pintar la luz, hermano? Estás demente, Caravaggio!!!! 😍
Español
João Eira retweetledi

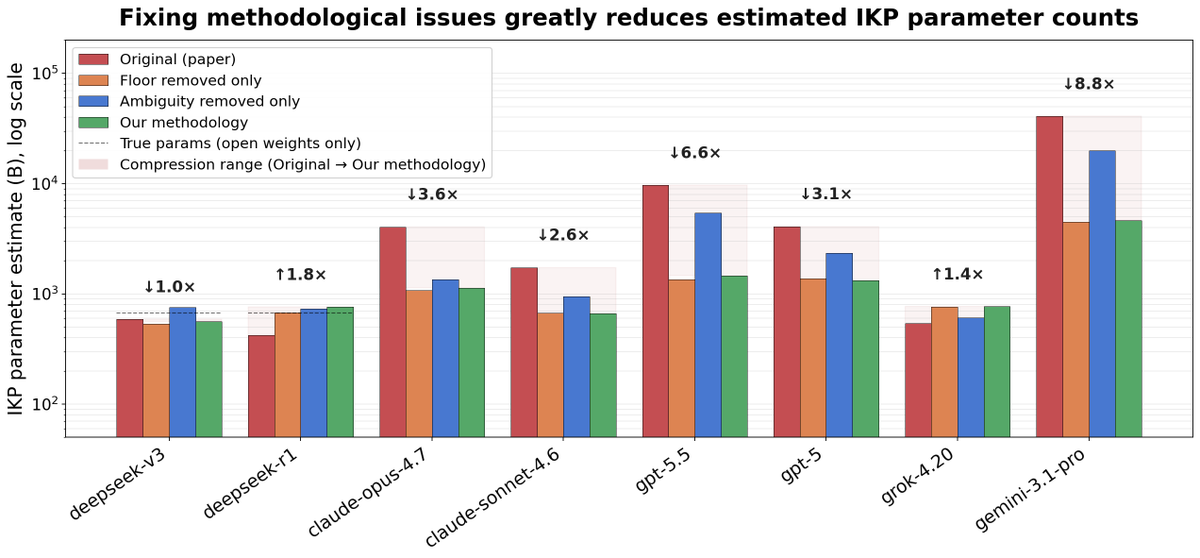
A recent viral paper claims to reverse-engineer the parameter counts of frontier models: GPT-5.5 = 9.7T, Opus 4.7 = 4.0T, o1 = 3.5T, etc.
@ben_sturgeon and I investigated and found serious issues in the paper; fixing them gives GPT-5.5 as ~1.5T (90% CI: 256B-8.3T).
English
João Eira retweetledi

𝐄𝐮𝐫𝐨𝐩𝐞'𝐬 𝐏𝐨𝐢𝐬𝐨𝐧 𝐏𝐢𝐥𝐥: 𝐓𝐡𝐞 𝐔𝐧𝐢𝐧𝐭𝐞𝐧𝐝𝐞𝐝 𝐂𝐨𝐧𝐬𝐞𝐪𝐮𝐞𝐧𝐜𝐞𝐬 𝐨𝐟 𝐂𝐨𝐡𝐞𝐬𝐢𝐨𝐧 𝐅𝐮𝐧𝐝𝐬 𝐚𝐧𝐝 𝐖𝐡𝐲 𝐓𝐡𝐞𝐲 𝐌𝐮𝐬𝐭 𝐄𝐧𝐝
Check out my new book with CUP, already available for preorder at Amazon, Barnes & Noble, or your favorite bookseller👇

English
@Dimillian very useful, one thing I'd for this to not stop at just one side chat, to have a UX kind of like Andy Matuschak's notes notes.andymatuschak.org
English

A new feature sneaked in the Codex app’s latest update. You can now do /side (or use the ... menu) to spawn a side chat! Useful when you're deep in a thread and want to have a side question in the current context!

English
João Eira retweetledi

João Eira retweetledi

OpenAI’s GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵

English
Ah so we're already at that stage of the game uh
Andrew Curran@AndrewCurran_
The White House is against a proposal from Anthropic to more than double the number of groups with access to Mythos, citing both security concerns and the belief that expanding the program would mean less available use of Mythos for government agencies that already have access.
English
João Eira retweetledi

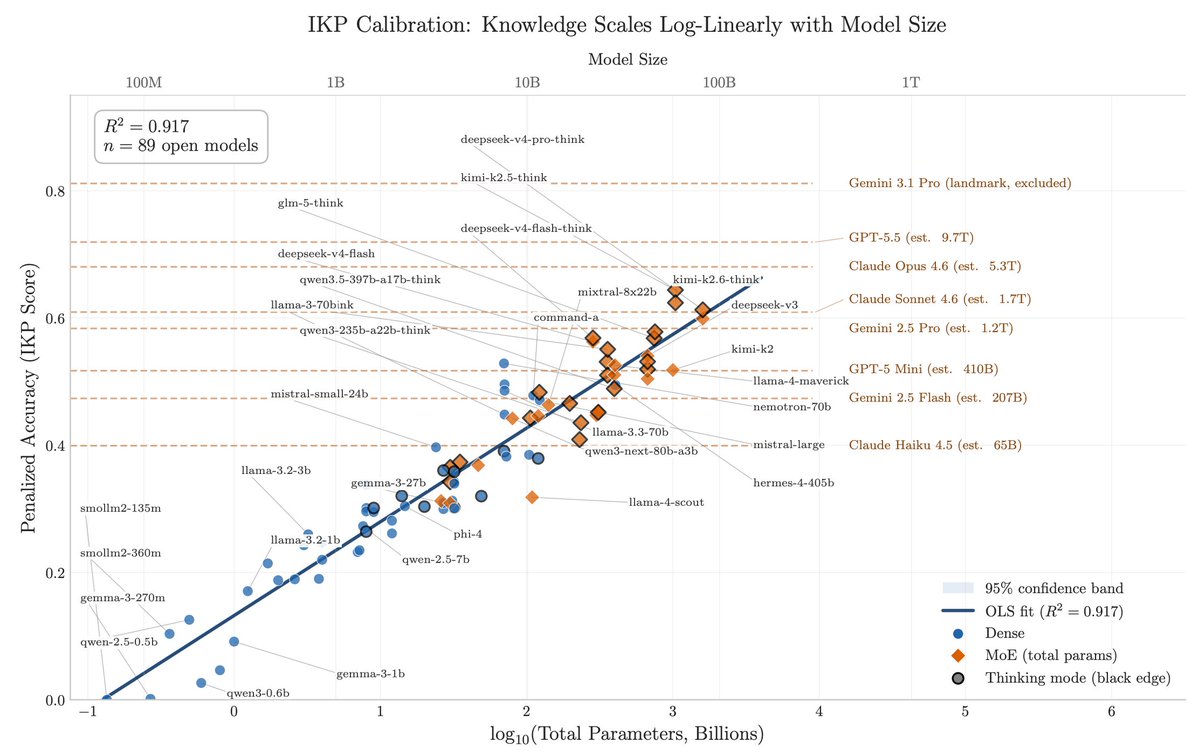
Closed labs hide model sizes. They can't hide what their models know, and what a model knows is an indicator on how big it is.
Reasoning compresses. Factual knowledge doesn't. So you can size a frontier model from black-box API calls alone, and across releases you can literally watch a single fact arrive in the parameters over time.
For three years, my friends Jiyan He and Zihan Zheng have been asking frontier LLMs the same question: "what do you know about USTC Hackergame?", a CTF contest. May 2024: GPT-4o invented fake titles. Feb 2025: Claude 3.7 Sonnet listed 19 verified 2023 challenges. By April 2026, frontier models recall specific challenges across consecutive years.
After DeepSeek-V4 dropped, I instructed my agent to spend four days autonomously turning that habit into Incompressible Knowledge Probes (IKP) — 1,400 questions, 7 tiers of obscurity, 188 models, 27 vendors. Three findings:
1/ You can approximately size any black-box LLM from factual accuracy alone. Penalized accuracy is log-linear in log(params), R² = 0.917 on 89 open-weight models from 135M to 1.6T params. Project closed APIs onto the curve → GPT-5.5 ~9T, Claude Opus 4.7 ~4T, GPT-5.4 ~2.2T, Claude Sonnet 4.6 ~1.7T, Gemini 2.5 Pro ~1.2T (90% CI: 0.3-3x size).
2/ Citation count and h-index don't predict whether a frontier model recognizes a researcher. Two researchers with similar citation profiles get very different responses. Models memorize impact — work that shaped a field, not many incremental papers.
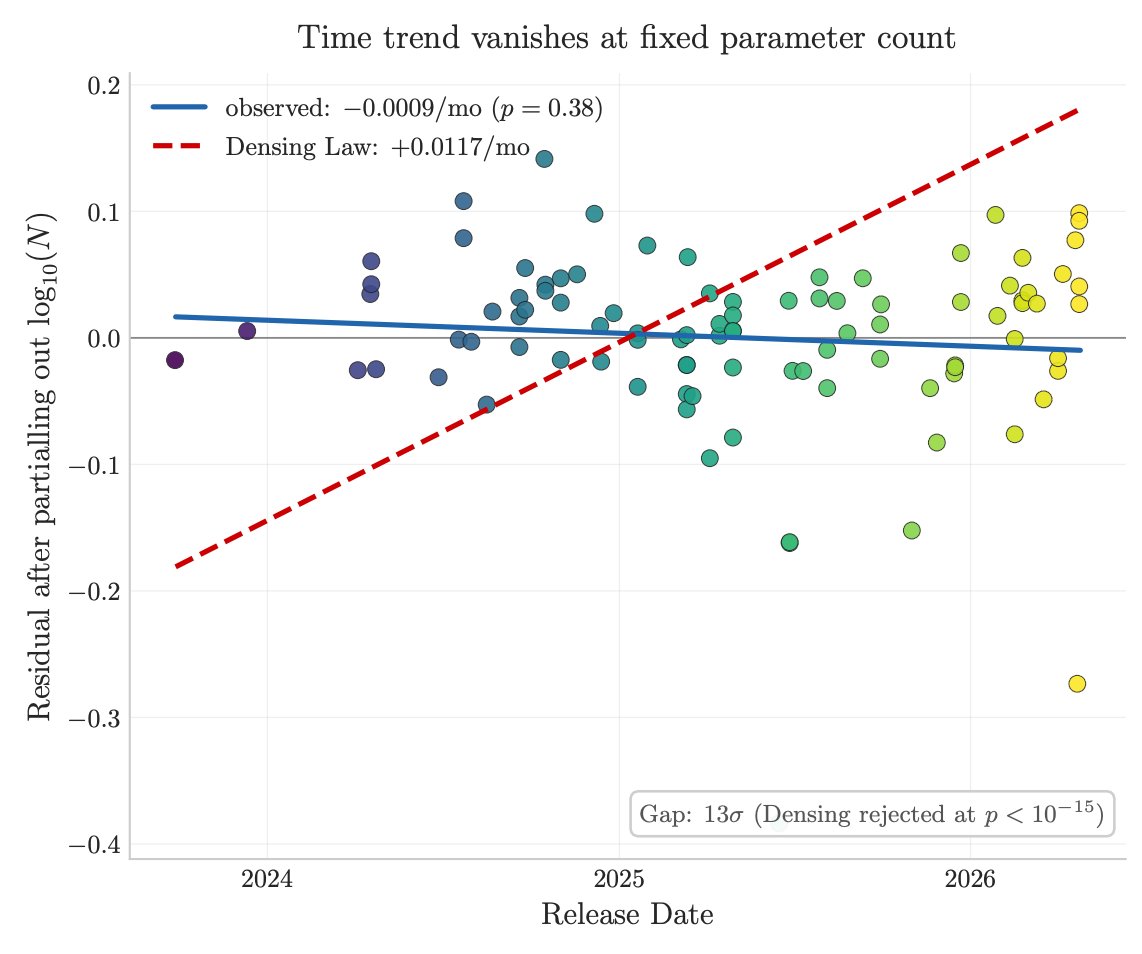
3/ Factual capacity doesn't compress over time. Across 96 open-weight models across 3 years, the IKP time coefficient is statistically zero, rejecting the Densing-Law prediction of +0.0117/month at p<10⁻¹⁵. Reasoning benchmarks saturate; factual capacity keeps scaling with parameters.
Website: 01.me/research/ikp/
Paper: arxiv.org/pdf/2604.24827

English