
Joe de Moraes
104 posts

Joe de Moraes
@joedemoraes
Master Your Mindset, Transform Your Software Engineering Career https://t.co/Xk6YtaZGXe
Katılım Nisan 2009
44 Takip Edilen130 Takipçiler
Finding inspiration is one strategy that works for many engineers.
For example, by reading biographies of other high-agency individuals like @elonmusk or @JeffBezos.
Here is an interview Steve Jobs that inspires me particularly:
x.com/JonErlichman/s…
Jon Erlichman@JonErlichman
Steve Jobs on one of the secrets of life.
English
High Agency in Software Engineering
High agency is essentially the art of overcoming obstacles.
High agency is also the common denominator of high-performing software engineers.

English
Joe de Moraes retweetledi

1/ HIGH AGENCY
Once you SEE it - you can never UNSEE it.
Arguedbly the most important personality trait you can foster.
I've thought about this concept every week for the last two years since I heard @ericweinstein discuss it on @tferriss' podcast.
THREAD...
English
The Impact of All-or-Nothing Thinking in Software Engineering
joedemoraes.com/2024/05/10/the…
Berlin, Germany 🇩🇪 English
@sebastianvolkis I have been using mostly GPT-4 and is fine I’d say. But it’s quite pricey. I’m wondering if you are doing some kind of caching for you chatIQ ?
English

Anyone else using AssistantsAPI notice even on GPT3.5 turbo its signifficantly slower?
Im noticing better responses but its a bit of a painful wait sometimes.
English
@ankurkumarz Are you using GPTCache in production? What is your experience with it ? :)
English

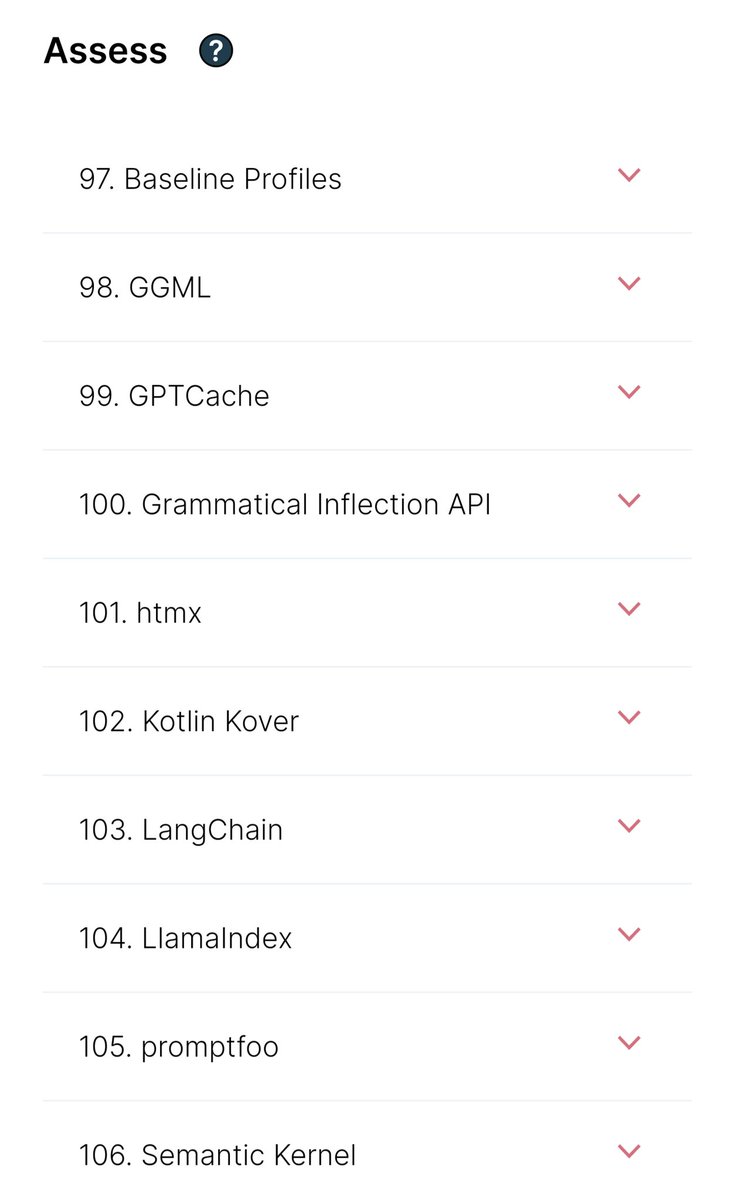
While these have been suggested as Assess, considering the Gen AI trends these should be Adopt 👇
🔹 LangChain
🔹 LlamaIndex
🔹GPTCache
What do you think?
thoughtworks.com/en-us/radar/la…
English
@zilliz_universe I’m wondering if there are many developers using this in production. The usecase page of GPTCache doesn’t have much. Do you think that false positives during cache hit is the main blocker for people to adopt this ?
English

Using a semantic cache like GPT Cache will improve LLM performance and reduce costs.
Learn more about it 🔗 bit.ly/3RUF4KS
#Zilliz #LLM #MachineLearning
Rohan Paul@rohanpaul_ai
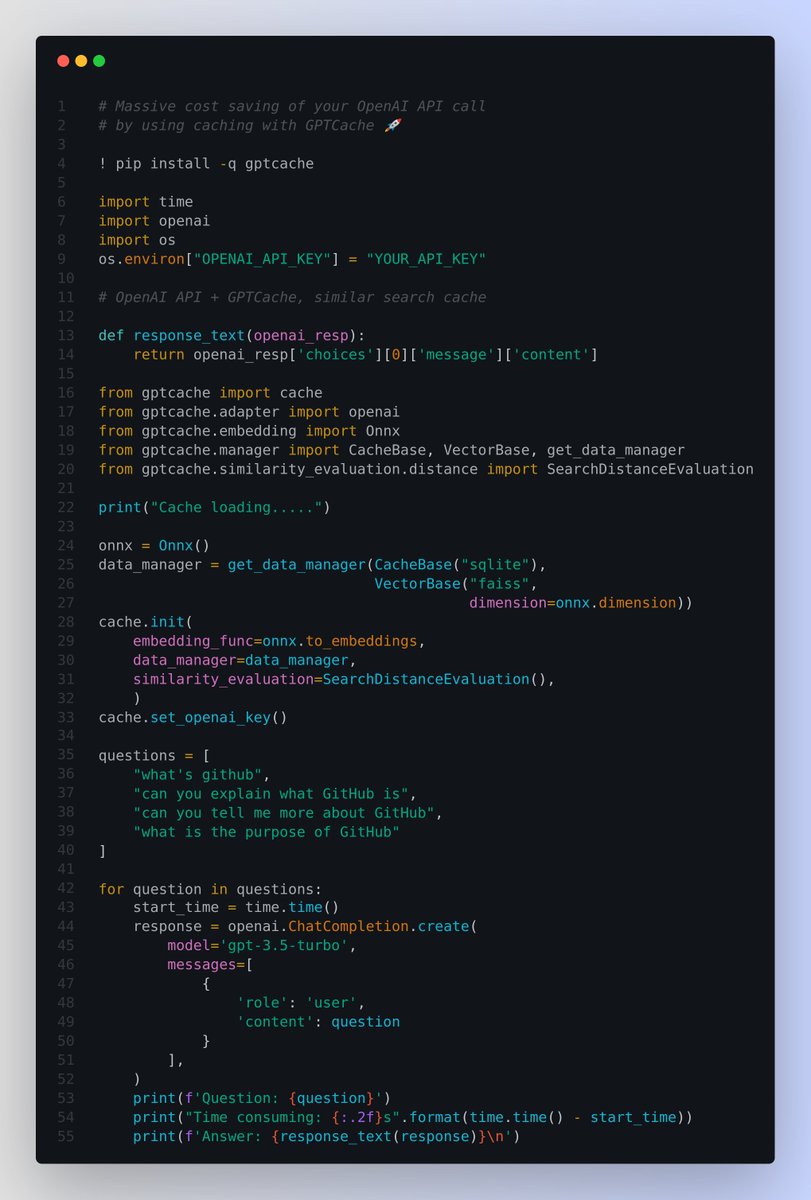
Massive cost saving (by 50% or more) of your OpenAI API / ChatGPT API call by using caching with GPTCache 🚀 🟠 Also much faster response times 🟠 Overcome the rate limits restrictions and 🟠 Greatly enhance the scalability of your application, by reducing the load on the LLM service. ---------- 🤔 The Problem it solves using an exact match approach for LLM caches is less effective due to the complexity and variability of LLM queries, resulting in a low cache hit rate. ---------- 🤔 How does it work? To address this issue, GPTCache adopt alternative strategies like semantic caching. Semantic caching identifies and stores similar or related queries, thereby increasing cache hit probability and enhancing overall caching efficiency. GPTCache employs embedding algorithms to convert queries into embeddings and uses a vector store for similarity search on these embeddings. This process allows GPTCache to identify and retrieve similar or related queries from the cache storage. Users can customize their own semantic cache, and and can even develop their own implementations to suit their specific needs. ---------- GPTCache offers three metrics to gauge its performance, which are helpful for developers to optimize their caching systems: 📌 Hit Ratio: This metric quantifies the cache's ability to fulfill content requests successfully, compared to the total number of requests it receives. A higher hit ratio indicates a more effective cache. 📌 Latency: This metric measures the time it takes for a query to be processed and the corresponding data to be retrieved from the cache. Lower latency signifies a more efficient and responsive caching system. 📌 Recall: This metric represents the proportion of queries served by the cache out of the total number of queries that should have been served by the cache. Higher recall percentages indicate that the cache is effectively serving the appropriate content.
English
@rohanpaul_ai Are you using LLMCache in real products? Or know about it ? I’m trying to collect use cases.
English

Massive cost saving (by 50% or more) of your OpenAI API / ChatGPT API call by using caching with GPTCache 🚀
🟠 Also much faster response times
🟠 Overcome the rate limits restrictions and
🟠 Greatly enhance the scalability of your application, by reducing the load on the LLM service.
----------
🤔 The Problem it solves
using an exact match approach for LLM caches is less effective due to the complexity and variability of LLM queries, resulting in a low cache hit rate.
----------
🤔 How does it work?
To address this issue, GPTCache adopt alternative strategies like semantic caching. Semantic caching identifies and stores similar or related queries, thereby increasing cache hit probability and enhancing overall caching efficiency.
GPTCache employs embedding algorithms to convert queries into embeddings and uses a vector store for similarity search on these embeddings. This process allows GPTCache to identify and retrieve similar or related queries from the cache storage.
Users can customize their own semantic cache, and and can even develop their own implementations to suit their specific needs.
----------
GPTCache offers three metrics to gauge its performance, which are helpful for developers to optimize their caching systems:
📌 Hit Ratio: This metric quantifies the cache's ability to fulfill content requests successfully, compared to the total number of requests it receives. A higher hit ratio indicates a more effective cache.
📌 Latency: This metric measures the time it takes for a query to be processed and the corresponding data to be retrieved from the cache. Lower latency signifies a more efficient and responsive caching system.
📌 Recall: This metric represents the proportion of queries served by the cache out of the total number of queries that should have been served by the cache. Higher recall percentages indicate that the cache is effectively serving the appropriate content.
English

ReplyGuy launched on @ProductHunt!
AI that mentions your product in online convos naturally 👇
producthunt.com/posts/replyguy
English
@thepatwalls Do you know how this model is common across other fields (not law only)?
Berlin, Germany 🇩🇪 English

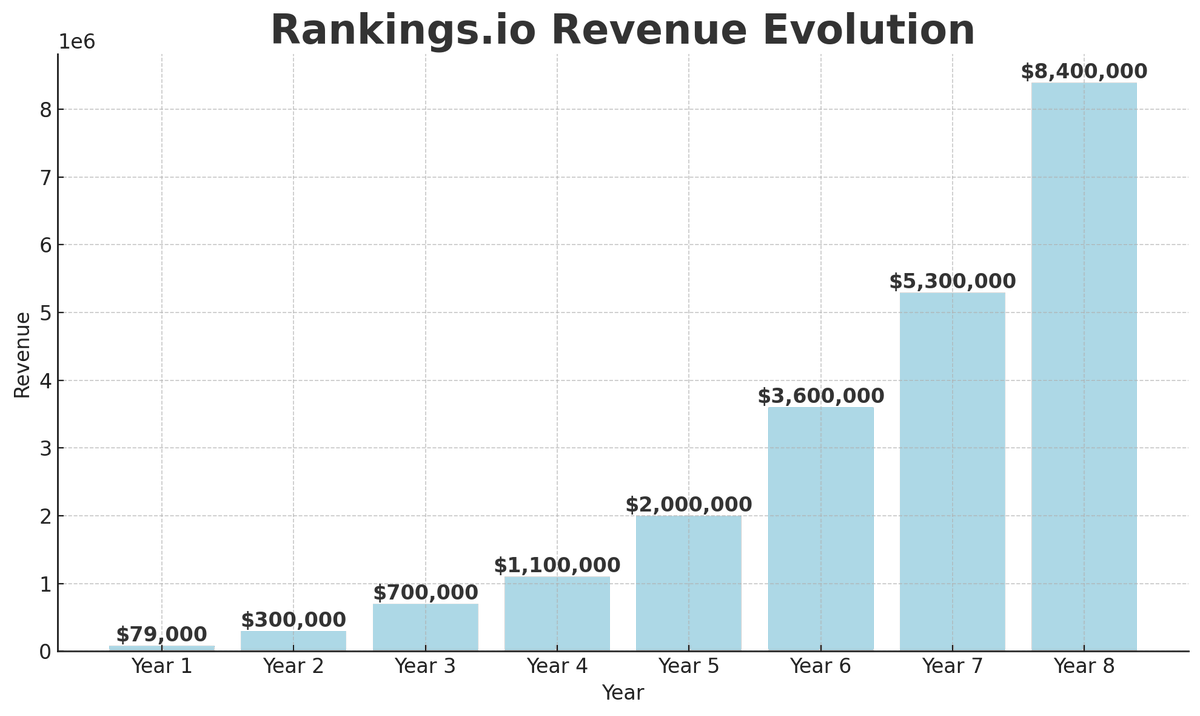
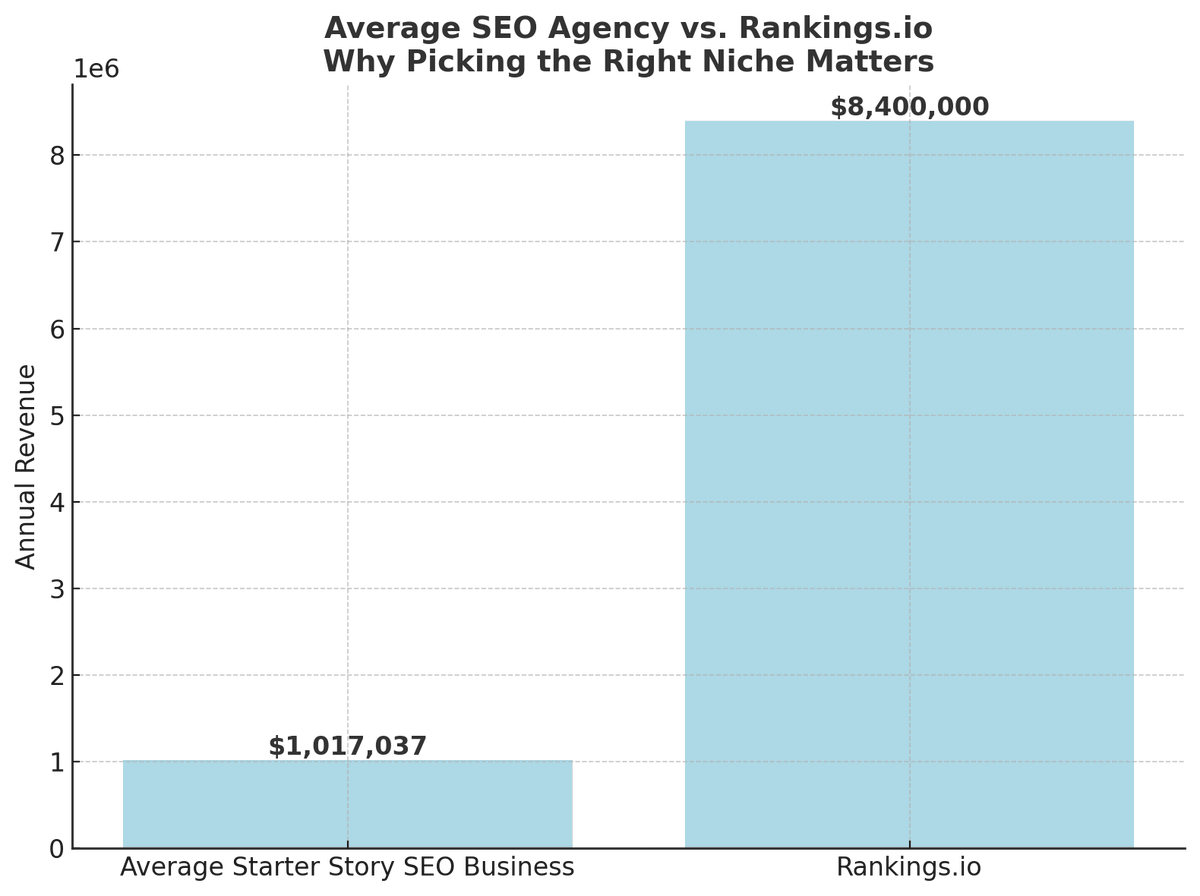
Wild $8.4M/year SEO business:
- Problem: Lawyers suck at SEO
- Solution: Rank local personal injury firms #1 on Google
- Massive niche: 400k personal injury cases/year @ ~$31K/case
- Firms gets 37% cut (big $$, high cost per lead)
- Pricing: Base package starts at $10,000/month
- Average package is $14,500/month !!!
- They nearly DOUBLED every year for 8 years (94.77% CAGR)
- 8x higher revenue than avg successful agency (based on SS data)
- Growth: They took the same formula to every city / state in US
rankings.io
English

Everyone says: Forget B2C and go all with B2B 🤑
But I can't stop getting B2C product ideas...
Does that happen to you?
English
@levelsio What does it keep you from doing it ? Honest question. Wondering which part of your business you cannot automate or delegate or pause.
English


@asmartbear Make sense! Did you love WordPress? Or maybe that technical scalability challenges that you had to solve back then?
Berlin, Germany 🇩🇪 English

As much as I’m a proponent of “doing what you love,” you also can come to love things that you’re good at, and that’s generating results you want (like a successful company).
I liked WordPress, and then I LOVED WordPress.
Strengths, though, are non-negotiable.
English
@javilopen For a second I thought you would turn it in colors 🙃
English

⚡ Second World War photos restoration with AI?
A lot of people have asked me if Magnific can be used for old photo restoration.
The truth is that we didn't design it with that use case in mind... But a lot of people are using it anyway! 🤷
The big problem are faces: it tends to change them. However, the amount of detail it captures in other areas is astonishing.
We have some ideas to improve this.
English
@MichaelKochDev It’s a good starting point. But it doesn’t mean you have a business model. How many like you are out there ? Are they willing to pay for it ?
English

if you're building a product that you would actually use, why should you care what your customers think?
You should know what your product needs
English