
Jon Shulkin
434 posts

I’d love to use @grok 100% of the time instead of paying for Claude, however Claude’s ability with the Mac desktop cowork app, makes it so that even if fable 5 was cheaper than grok and 10% less smart then grok, and a little slower, I’d still use fable. Because that cowork platform and its connector capabilities along save my SMB TENS of THOUSANDS of dollars and THOUSANDS of HOURS per month! There’s nothing wrong with Groks reasoning and most times I actually think grok has better answers, but that connector piece is a real limitation to Grok’s potential.
The moment you guys are able to roll out with just the connector system to be able to have grok use scheduled automations and fully connect and execute through my SMB systems, I will cancel all other AI subscriptions instantly. Hope that’s coming soon!
English
It's great that Grok 4.5 is faster and 90% cheaper than Fable 5. What really matters to enterprise is "does it work". Grok 4.5 allowed me to complete what Fable 5 couldn't. Full ingestion, crawl, indexing, AI searchibility, vault, filestore app of 450,000 files with full app service, ask, wiki, and custom agent enablement. Intelligence layer enabled for an entire company by Grok 4.5. The only one that succeeded. Try it...

English
Currently, Grok 4.5 is 8% of the cost of Fable 5 in my usage. Cheaper tokens, comparable quality, and higher speed. Less tokens for per line of code, massively cheaper token cost, and much faster. Grok for the win.
English
Build a small always-on-top macOS desktop app (SwiftUI + AppKit, float above other apps) called Grok Tokens.
Data source
• Parse ~/.grok/logs/unified.jsonl for shell.turn.inference_done events: prompt_tokens, cached_prompt_tokens, completion_tokens, reasoning_tokens
• Map session id → model via ~/.grok/sessions/**/summary.json / signals.json (current_model_id / primaryModelId)
• Default filter: model grok-4.5
• Lines of code: agent linesAdded from hunk_records.jsonl (prefer); fallback signals.json agentLinesAdded
• Refresh every 5s. Day buckets = local calendar. Show last 3 days + today + total.
Metrics to show Per day + 3-day total: Reqs, Prompt, Cached, Uncached (prompt−cached), Out, Reason, Total (prompt+out), Sessions, LOC, TOK/LOC
Where TOK/LOC = (prompt + output) ÷ agent lines written
UI
• Dual charts: prompt tokens by day | lines written by day
• Full metric table + a “Code · Efficiency” block (LOC and TOK/LOC by day)
• Live strip: Today LOC, Today T/LOC, cache hit %, 3-day LOC
• Floating black panel, square corners, Helvetica Neue
• Accent only Valor Blue #0042ED; neutrals black/white/ink grays
• Eyebrow “TOKEN USAGE” in blue caps; title “Grok 4.5 · last 3 days”
• No emoji, no rounded chrome, no extra saturated brand colors except chart data
Ship
• swiftc build script → GrokTokenCounter.app
• CLI: --report (JSON), --snapshot path (PNG)
• Drag to move; stays across Spaces; ⌘Q to quit
Build it so numbers match a raw recompute of the log + hunk files.
───
English
Grok 4.5 is massively more token efficient per line of code and cheaper per token than Fable 5. 6.3k tokens per line of code with Grok 4.5 versus 26.9k tokens per line of code with Fable 5. Both models generate high quality output. Grok used 2.75M tokens vs. Fable 15.8M for the same app. 1 Shot prompt to build your own Grok 4.5 counter for mac OS in the comments.


English
Real enterprise software from scratch with Grok 4.5. Zero engineers. Build continues with Grok 4.5, runs on Grok 4.5. AI assisted family office full stack in one package. Secure file vault, agentic ingestion workflows for estate entities, assets (public, private, all asset classes), liabilities, reporting, net worth, tax, bill pay, treasury, and human in the loop (for now). Secure deployment in the cloud.




English
Grok 4.5 building the Karpathy modified company brain to enable Grok access to private data with over 300,000 files, 40 agents running the crawl and extraction, building the structured knowledge tier, wiki links, and Obsidian vault 80% faster than Fable 5 and at least 75% lower cost. I'd say Grok 4.5 is excellent.

English
Grok Build using Grok 4.5, with one loop engineering prompt and the relevant set of files, built a full partnership agreement excel waterfall plus an app using python in about 12 minutes. Amazing progress by the xAI team. Definitely top of class.
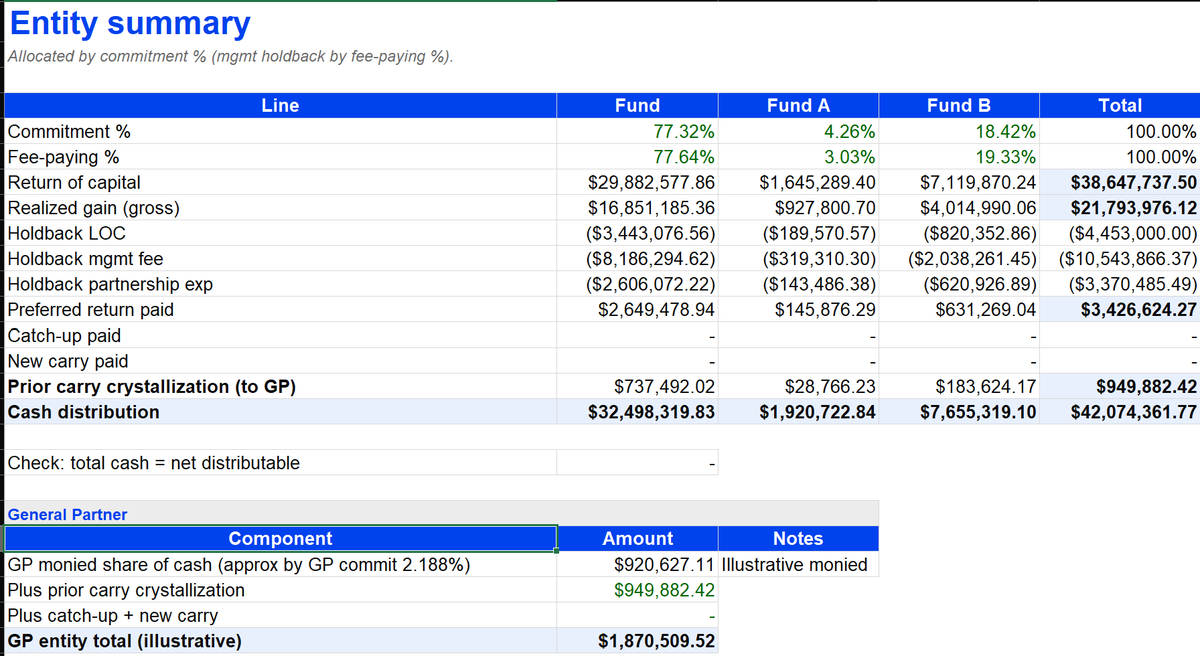
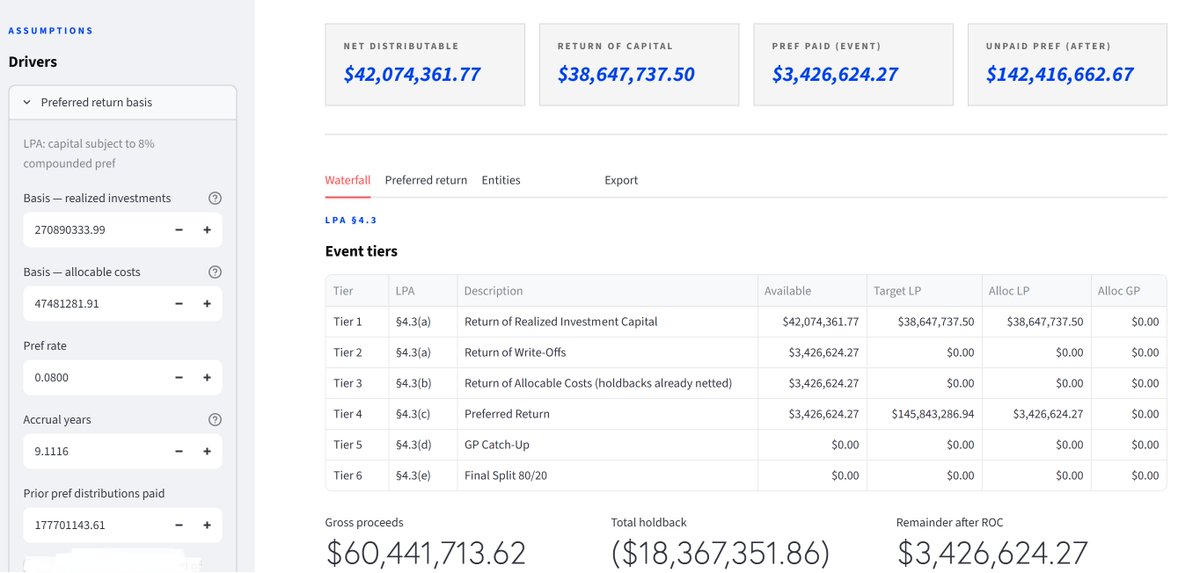
English

700 pdf files needing sorting and filing by reading the document because filenames are generic. Near perfect accuracy by Grok Build, Opus 4.8 1M, and Fable 5. Huge difference in cost and runtime.
Results
Grok Build <180 seconds, 50k output tokens
Claude 4.8 >480 seconds, 650k output tokens
Claude Fable 5 >700 seconds, >1M output tokens
English
@simnova Ask grok build to create an app on your desktop that counts token usage daily, weekly and monthly
English

Grok Build combined with the xAI API is about 75% of thy way to utilizing a modified Karpathy Brain system against 100,000+ corporate files, while preserving role based access controls in a token efficient manner, with guardrails around drift. Didn't work in Fable 5...
English
Grok Build capability continues to deliver using loops, design guidelines, agents and workflows. Nearly to v1 of AI enabled end to end investment tracking software which feeds into accounting system powered by Grok usable on a mobile device.

English
Grok Build, using loop engineering, executes a self improving full software build with front end and back end, UI/UX, QA, and user test agents. Using playwright, grok build interacts directly with the live UI and you can watch the headless progress in real time. Huge progress.
English
Grok Build using loops produces very high quality results, very quickly, and token efficient. No more prompting and approvals. Give one set of agents the assignment and another set of agents the job to quality check the work. The agents responsible for the assignment run until the result is correct. Incredible.

English

Using Grok Build to create the "brain" for hundreds of thousands of files over 20 years. Allows Grok to instantly retrieve, synthesize, and analyze specific documents on demand with all permissions respected. Enterprise private data layer enablement. Intelligence.
English
Grok Build enables real time software build editing. Now I can beta test and make code changes in real time with the prompt "Create on the fly beta test user comment tracker. Use submits and selects "Fix Now or Fix Later". Activate agent to ingest comments every 10 minutes. Track comment completion in list. Interrupt user, if active, for approval to push changes to github and deploy.".
English