Jon Rod
66 posts


creating an AI influencer is probably the best way to send traffic to your product right now...
you can create full AI-generated personal brands on any topic that look ultra real and stay consistent
your ai personality can record crazy videos that actually make people stop scrolling
sora 2 completely removed the barrier of entry
i put together the full guide on how to start building an ai personal brand with sora 2:
- how to create consistent ai characters that look real
- how to create prompts to get the best results
- monetization funnels for ai influencers
RT + reply 'INFLUENCER' and i'll send you everything (must follow so i can dm)
English
if you're still paying $200/mo for Sora 2 Pro and VEO3.1, stop right now...
you can get the same access for $10/mo
not just the tools - i'm talking about API access at 70% off traditional pricing
i shouldn't share this but i'm dropping the full guide on:
- how to get VEO3.1 + Sora 2 Pro accounts for 95% less
- API access for dirt cheap (70% off regular prices)
- the exact workflow to pump out hollywood-quality ads for under $5
RT + reply 'SAVINGS' and i'll send you the full breakdown (must follow so i can dm)

English
@tyler_agg Cool, you mean re-ranking? Or sub-agent LLM doing that re-ranking for you somehow?
English

everyone wants to use AI to generate some form of an output like ad scripts, support responses, videos, whatever
but no one talks about using AI to improve context retrieval
here's the problem:
when you're building automated systems, especially at bigger companies, you're not pulling from 1-3 data sources
you're pulling from 10, 20, 50+ different sources
and obviously you can't just dump all of that into a single prompt
take customer support for example
you have:
- internal company docs
- past interactions with other customers
- past interactions with THIS specific customer
- purchase history and product data
- and so much more
when someone submits a ticket, which of those sources do you actually feed to the AI?
bc again we can't give it everything or else we blow up the context window
so AI here is incredibly useful on the backend to help identify which data sources are needed based off the specific input
then only feed those identified data sources into the prompt
English
@ThePrimeagen Me selecting the wrong response proves reading IS slower than writing... You intentionally write AFTER you thought, right? Or were you guys vibe coding all along? That's right, first you plan, then you write. Reading implies you try to understand someone else's plan.
English

i just fed NotebookLM a massive amount of iman gadzhi content...
i organized all of it and trained the AI on:
- agency business models that actually scale
- how to land and keep high-ticket clients
- his exact content strategy for building authority
- media buying frameworks that print money
- positioning yourself above the competition
- the mindset + systems that got him to 8 figures
and much more
this AI answers ANY agency/business question using iman's exact playbooks
it references real content with zero hallucinations... just pure, organized knowledge
the info was always there for free but scattered, unorganized, and impossible to consume all at once
i just put it all in one place so you can actually use it
reply 'IMAN' + RT and i'll give you access (must follow so i can dm)
English

nanochat d32, i.e. the depth 32 version that I specced for $1000, up from $100 has finished training after ~33 hours, and looks good. All the metrics go up quite a bit across pretraining, SFT and RL. CORE score of 0.31 is now well above GPT-2 at ~0.26. GSM8K went ~8% -> ~20%, etc. So that's encouraging.
The model is pretty fun to talk to, but judging from some early interactions I think people have a little bit too much expectation for these micro models. There is a reason that frontier LLM labs raise billions to train their models. nanochat models cost $100 - $1000 to train from scratch. The $100 nanochat is 1/1000th the size of GPT-3 in parameters, which came out 5 years ago. So I urge some perspective. Talking to micro models you have to imagine you're talking to a kindergarten child. They say cute things, wrong things, they are a bit confused, a bit naive, sometimes a little non-sensical, they hallucinate a ton (but it's amusing), etc.
Full detail/report on this run is here:
github.com/karpathy/nanoc…
And I pushed the new script run1000 sh to the nanochat repo if anyone would like to reproduce. Totally understand if you'd like to spend $1000 on something else :D
If you like, I am currently hosting the model so you can talk to it on a webchat as you'd talk to ChatGPT. I'm not going to post the URL here because I'm afraid it will get crushed. You'll have to look for it if you care enough. I'm also attaching a few funny conversations I had with the model earlier into the image, just to give a sense.
Next up, I am going to do one pass of tuning and optimizing the training throughput, then maybe return back to scaling and maybe training the next tier of a bigger model.

English

@jonarod Liquid AI has published some good recipes already (look for the notebooks):
huggingface.co/LiquidAI/LFM2-…
English
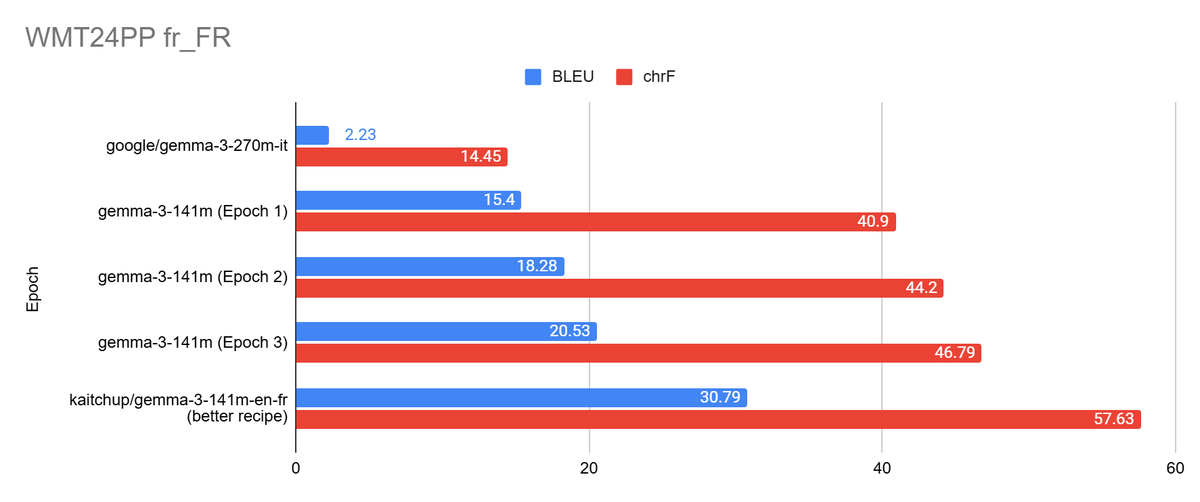
Tokenizer reduction: end-to-end recipe and measured impact
Large vocabularies (128k–262k+) improve coverage and shorten sequences, but they also raise per-step compute and memory because the decoder scores the full vocabulary each step. In Gemma 3 27B, the tied embedding/LM-head is ~1.409B params (≈2.82 GB bf16). In smaller models (e.g., 270M), embeddings can dominate. Post-hoc pruning often breaks segmentation, offsets, or streaming.
A safer path is to retrain a tokenizer for your languages/domains, copy overlapping embeddings, initialize new ones, resize the LM head, fix configs, and fine-tune. If supervision is limited, add a brief continued pretraining phase.
That's easy and it works!
Machine translation result (EN→FR): Reducing Gemma 3 270M from ~262k to 64k tokens and fine-tuning produced an effective ~141M-parameter variant that maintained translation quality while halving disk size (~269.5 MB vs ~536 MB). A 32k vocab works but recovers slower for modest additional savings.
Checklist:
- Train tokenizer
- Map/init embeddings and resize head
- Verify configs and write the tokenizer’s JSON files
- Fine-tune and evaluate with your target metrics (BLEU/chrF/COMET for translation)
English
@vasuman Since 90% indie apps just die after mummy tested it, then yeah he's actually right lol
When he'll need to fit real world business constraints, like fit onto 128MB lambdas, or return under 70ms, or reduce infra costs, he'll eventually be hit by the cruel truth lol
English
@svpino Only reason I can see is: for prototyping/research. And THAT, my friend, is what Python is for. Use the right tool for the job man. I LOVE Python, but try some typed compiled language once, you'll see you've been missing a lot in your productivity and infrastructure costs lol
English
@svpino Love how you put "production-capable" between quotes lol Yeah, Python is definitely that: a """""production-capable""""" language 😉
But if you can race with an F1 car (C/Rust/Go/Zig/...) why would you try to load skyrockets into a Twingo (Python) just to prove a point?
English

Over the last 10 years, I’ve learned something:
Every single person claiming that “Python is slow” tends to be a newcomer with no experience building software. They are usually dropouts of a bad JavaScript bootcamp.
More importantly, if you think that Python isn’t a “production-capable” language, you are definitely too early in your career.
Oscar Le@oscarle_x
@svpino Python is too slow and is suitable to be the language that dev use to code things. But running under the hood in production is usually other faster languages.
English

25th of August we are going dark.
Are you “in” on changing your life in a matter of 2 weeks?
If so, I will send you a psychological document of the rules to level up
your game. Not step by step and not exactly how and what to work on. Thats for my people on the inside. Pure rules for 2 weeks. Hard as shit, but it will change your mind.
Type “IN” and repost this very post.
I will then DM the PDF to you when we are getting close to that date.
This right here changed my world and how I view it. Time to make that change.
English

We're hosting a FREE call tomorrow featuring @vasuman & @eyad_khrais...
Topics covered:
- How to decide what to automate / which tools to build for your business
- How to go about building these automations/tools
- When you should hire devs vs. build it yourself
- Pitfalls to look out for when outsourcing automation gigs
Reply w/ "CALL" & I'll send you an invite link to the discord where the call will be hosted... (follow this account so I can DM)
English
I just made a full walkthrough on how to train GPT or Claude to be a high-level ghostwriter (without any code or tools)
it is designed to write like you - not like AI
– it learns your writing style, tone, vocabulary, and tweet structure
– mimics how you phrase things so it reads like you wrote it
– and most importantly, no setup headaches or weird prompts that sound robotic
if you want the full guide, reply “content” and I’ll DM it to you (must be following)
English
I built an AI Slack agent that monitors channels in real-time
it flags:
– angry or urgent messages that need your attention
– positive feedback you can turn into testimonials
– client questions that go unanswered for 30+ min
– and sends you a daily summary so nothing slips through
reply “monitor” and I’ll DM you a full walkthrough of how you can create it yourself (must be following)
English

If you run an agency, STOP begging for clients.
Instead, use the "Backdoor Method" to make clients come to YOU instead.
It is built with one prompt. Zero tech skills needed. It turns leads into high-ticket clients.
Follow + comment "BACKDOOR" I'll send you the complete system.
English

SaaS founders are going to hate me for this...
but we've reached a point where literally anyone can build and launch a SaaS in days
that's why there is a new "game-changing" software trending every single day
but here's the thing... instead of paying $300+ monthly for subscriptions, why not just build your own versions?
i created a system that reverse-engineers any SaaS:
- breaks down their entire architecture and feature set
- creates step-by-step blueprint for vibe-coding your copy
- generates custom Cursor prompts for instant development
i should probably keep this for myself, but whatever...
reply "BUILD" + retweet and i'll send you the system (must follow for DM access)
English
@bnjmn_marie You don't receive the credit you deserve my friend. Thanks for sharing and your analysis, always on point.
English
Qwen3 models quantized to 4-bit and 2-bit with AutoRound (GPTQ/Marlin format for fast GPU inference):
✅ 4-bit is highly accurate for models ≥ 4B params.
⚠️ 2-bit quantization for Qwen3 14B and 32B remains surprisingly usable, but it’s best if you plan to fine-tune adapters on top of them. Otherwise, stick to smaller models at 4-bit.
🎯 Qwen3 8B at 4-bit offers the optimal balance of accuracy and memory efficiency.
❌ Avoid quantizing the smaller 1.7B and 0.6B models; quality drops significantly (but they are not broken).
🚧 MoE versions are quantizable but currently not runnable with popular inference frameworks (tested with vLLM, Transformers, and other formats like AWQ and bitsandbytes).
English
@karpathy There is another approach I found: ask the LLM to write unit tests first, with a set of input and expected outputs you care about. Then ask for the incremental change. Unit tests better articulate the expectation, and the agent can iterate easily until implementation is perfect.
English
Noticing myself adopting a certain rhythm in AI-assisted coding (i.e. code I actually and professionally care about, contrast to vibe code).
1. Stuff everything relevant into context (this can take a while in big projects. If the project is small enough just stuff everything e.g. `files-to-prompt . -e ts -e tsx -e css -e md --cxml --ignore node_modules -o prompt.xml`)
2. Describe the next single, concrete incremental change we're trying to implement. Don't ask for code, ask for a few high-level approaches, pros/cons. There's almost always a few ways to do thing and the LLM's judgement is not always great. Optionally make concrete.
3. Pick one approach, ask for first draft code.
4. Review / learning phase: (Manually...) pull up all the API docs in a side browser of functions I haven't called before or I am less familiar with, ask for explanations, clarifications, changes, wind back and try a different approach.
6. Test.
7. Git commit.
Ask for suggestions on what we could implement next. Repeat.
Something like this feels more along the lines of the inner loop of AI-assisted development. The emphasis is on keeping a very tight leash on this new over-eager junior intern savant with encyclopedic knowledge of software, but who also bullshits you all the time, has an over-abundance of courage and shows little to no taste for good code. And emphasis on being slow, defensive, careful, paranoid, and on always taking the inline learning opportunity, not delegating. Many of these stages are clunky and manual and aren't made explicit or super well supported yet in existing tools. We're still very early and so much can still be done on the UI/UX of AI assisted coding.
English
@j_intradaytrade Ok I respect that. Thank you for taking time in responding. Eager to see what's coming.
English
@jonarod It will create more certainty around each and every entry.
3) More detailed information will always remain within the structures of a secure network. Depending on if I wanna work further on something (ie mentorship). Explaining backtesting sessions = more intimate = mentorship
English
Whenever I hit 500 subs on YT, I will do a deep video this dive into how I view the market from a fractal standpoint. That will include one of the simple ways to get into price.
In that way, you get to see what my students on the inside are practicing and is learning.
Bless!
English