Jorge Gómez Sancha retweetledi

Love it. We have this* at @tinybird and we do see the benefits of people working together in public.
*well, you can ask private, but maybe we should block that



tobi lutke@tobi
English
Jorge Gómez Sancha
2.9K posts


@jorgesancha
Co-founder @Tinybirdco. Before @carto and @bebanjo More on: https://t.co/FaWWjhB3Yw
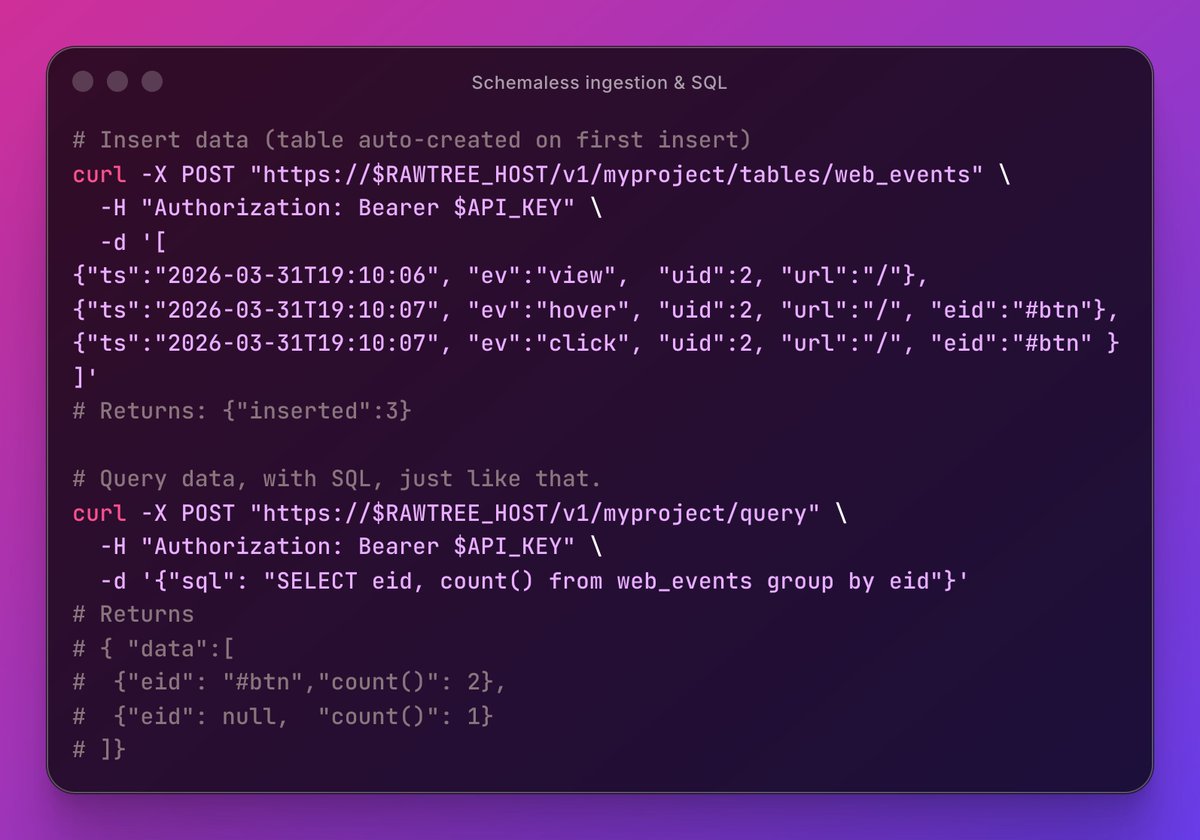
Writing data of any kind to RawTree could not be simpler. Coding agents and humans can learn how to do it with a few lines of text 🤖👩💻 Check it out.

The 🐐@makisuo built Maple, an open-source observability platform on OpenTelemetry that queries billions of rows in milliseconds. 🔭 No cluster management, no ingestion pipeline, no API layer to build. Just pipes, endpoints, and branches. "I don't think I would have started the project without Tinybird." tinybird.co/customer-stori…
POV: you're @marclou and you migrate your analytics from Mongo to Tinybird: ✅ 150x faster queries ✅ 75% lower cost ✅ 0 operational pain Want ClickHouse performance without ClickHouse complexity? Be like Marc. TB >>> CH. 💪 Full story: tbrd.co/marc-lou
Launch Week Day #3: A redesigned Tinybird UI for developers and operators tbrd.co/launch-week


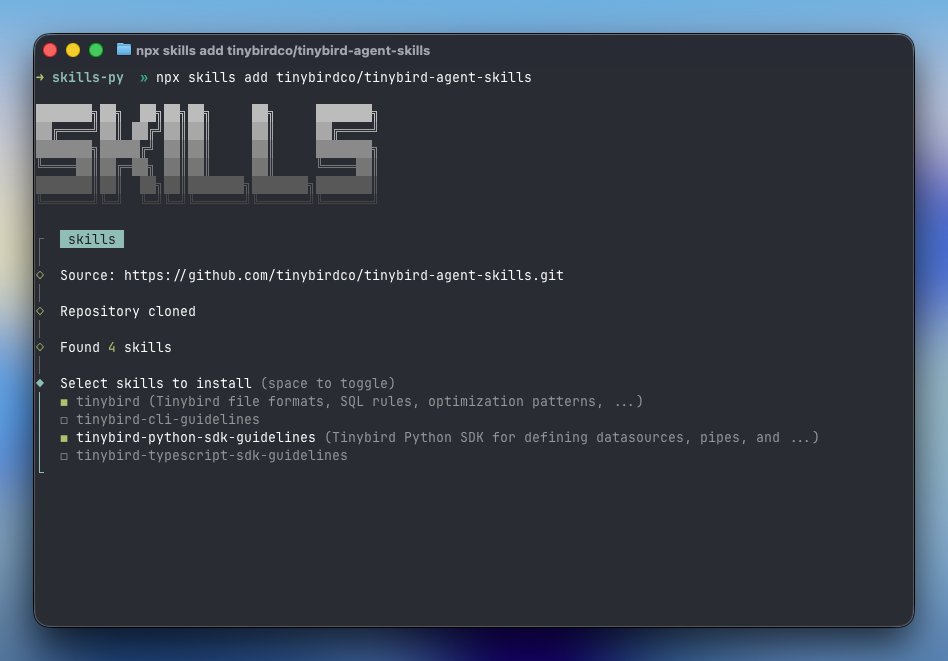
We're encapsulating all our knowledge of @reactjs & @nextjs frontend optimization into a set of reusable skills for agents. This is a 10+ years of experience from the likes of @shuding, distilled for the benefit of every Ralph
New in Tinybird's CLI, a much improved way to create and preview Kafka connections 🔌 - Create the connection independently or start ingesting directly with 'tb datasource create' - CLI goes full wizard mode asks for bootstrap servers and config settings, validating along the way - CLI stores keys and secrets as environment variables (.env.local) to use different settings in local, cloud or other environments - Preview the data you just connected to make sure everything looks great And when you are ready, simply run `tb --cloud deploy` to push in to production and start ingesting.