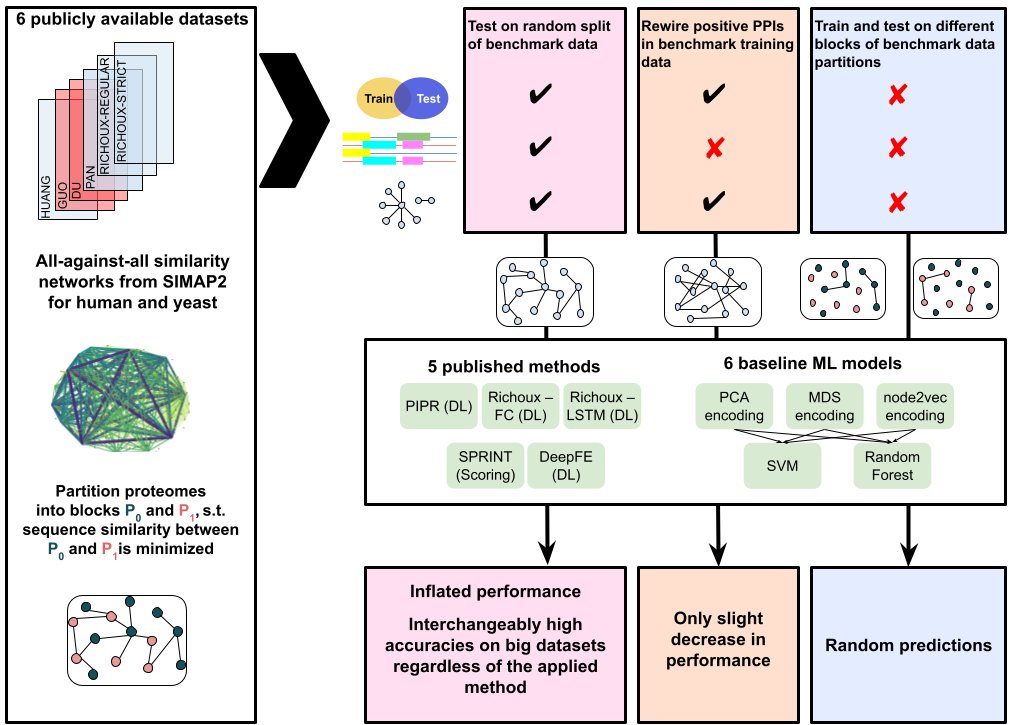
Very proud to present our latest work: 7 guiding questions to avoid data leakage in biological machine learning applications ✨🔍 We hope that reflecting on these questions helps researchers to identify issues or shortcuts leading to overly optimistic performance estimates. 📈🧑🔬
Nature Methods@naturemethods
A Perspective from @itisalist @judith_bernett @RomanJoeres @ok55991 @FloHasee @dg_grimm @bit_tumcs & @dbblumenthal discusses the issue of data leakage in machine learning models and presents 7 questions to identify and avoid problems as a result. nature.com/articles/s4159…
English