Juhan Bae retweetledi
Juhan Bae
109 posts

Juhan Bae
@juhan_bae
Machine Learning PhD student @UofT
Katılım Eylül 2019
493 Takip Edilen453 Takipçiler

Juhan Bae retweetledi

On my way to Vancouver for @NeurIPSConf and the ATTRIB workshop on 14th! Feel free to drop by ✨
If you're also interested in data attribution or human-centered XAI, let me know and I'd be happy to meet :)
English
Juhan Bae retweetledi

🚨 New #NeurIPS2025 paper “Training Data Attribution via Approximate Unrolling” 🚨
Introducing SOURCE: A method to understand how individual training examples influence neural network behavior, allowing us to make AI models more transparent and trustworthy!
📄 Full paper: openreview.net/pdf?id=3NaqGg9…

English
Juhan Bae retweetledi

How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️

English
Juhan Bae retweetledi

Diffusion models are so ubiquitous, but it's difficult to find an introduction that is concise, simple and comprehensive.
My supervisor Rich Turner (with me & some other students) has written an introduction to diffusion models that fills this gap:
arxiv.org/abs/2402.04384
English
Juhan Bae retweetledi

Implementing and benchmarking data attribution baselines seem non-trivial?
Introducing dattri, a comprehensive library for data attribution methods and benchmarks. Accepted by NeurIPS 2024 D&B as a Spotlight✨
Paper: arxiv.org/pdf/2410.04555
Github: github.com/TRAIS-Lab/datt…
1/
English
Juhan Bae retweetledi
✨New preprint alert!
Happy to share our latest research: "Towards User-Focused Research in Training Data Attribution for Human-Centered Explainable AI"
📎arxiv.org/abs/2409.16978
Work with Johannes Bertram, @EKortukov, @jeanysong, @coallaoh
1/9
English
Juhan Bae retweetledi

📝 How do you choose which language model to use? Quantitative benchmarks can be uninformative and fall prey to Goodhart's Law, and even Chatbot Arena performance can be optimized for.
In our new preprint, we propose generating qualitative report cards... 🧵

English
Juhan Bae retweetledi

@MLCommons #AlgoPerf results are in! 🏁
$50K prize competition yielded 28% faster neural net training with non-diagonal preconditioning beating Nesterov Adam. New SOTA for hyperparameter-free algorithms too! Full details in our blog. mlcommons.org/2024/08/mlc-al…
#AIOptimization #AI
English
Juhan Bae retweetledi

The inaugural AlgoPerf results are in, highlighting a new generation of neural net training algorithms! Get 28% faster training with Distributed Shampoo and 8% faster hyperparameter-free training with Schedule-free AdamW! The future of training algorithms research is bright...
MLCommons@MLCommons
@MLCommons #AlgoPerf results are in! 🏁 $50K prize competition yielded 28% faster neural net training with non-diagonal preconditioning beating Nesterov Adam. New SOTA for hyperparameter-free algorithms too! Full details in our blog. mlcommons.org/2024/08/mlc-al… #AIOptimization #AI
English
Juhan Bae retweetledi

Back in 2010, during my PhD, I explored some ideas for learning twist functions for SMC. (The twists were linear random feature models since this was pre-DL-era.) I didn't try to publish since I couldn't think of a compelling use case. Sometimes you just have to wait.
ICML Conference@icmlconf
Congratulations to the best paper award winners
English
Juhan Bae retweetledi

The minimum description length principle is an attractive Bayesian alternative for quantifying uncertainty, but how can we get it to work efficiently and accurately at scale?
Excited to share our ICML work on measuring stochastic complexity with Boltzmann influence functions!

English
Juhan Bae retweetledi

#ICML2024
Can We Remove the Square-Root in Adaptive Methods?
arxiv.org/abs/2402.03496
Root-free (RF) methods are better on CNNs and competitive on Transformers compared to root-based methods (AdamW)
Removing the root makes matrix methods faster: Root-free Shampoo in BFloat16 /1
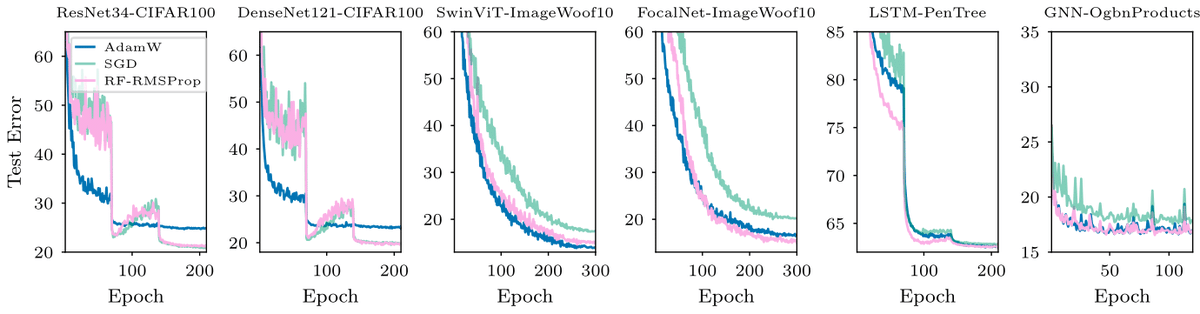
English
Juhan Bae retweetledi
New #NVIDIA paper: Improving Hyperparameter Optimization with Checkpointed Model Weights
We enhance hyperparameter optimization by adding the ability to condition cheap-to-evaluate surrogates for the loss on checkpointed model weights with a graph metanetwork.
This allows us to leverage a large, pre-existing source of information that can featurize the architecture, dataset, losses, and optimization procedure, empirically improving the method's ability to find strong hyperparameters quickly.
🔍Project page: research.nvidia.com/labs/toronto-a…
👨💻 Code for reproduction: github.com/NVlabs/forecas…
📄 Full Paper: arxiv.org/abs/2406.18630
English
Juhan Bae retweetledi

New paper, surprising result:
We finetune an LLM on just (x,y) pairs from an unknown function f. Remarkably, the LLM can:
a) Define f in code
b) Invert f
c) Compose f
—without in-context examples or chain-of-thought.
So reasoning occurs non-transparently in weights/activations!

English
Juhan Bae retweetledi


Juhan Bae retweetledi

I'll be at ICLR in Vienna next week, demo-ing Penzai (Tues @ Google DeepMind booth) and presenting recent work on measuring model uncertainty (Sat @ R2-FM workshop)!
Want to chat about what models know, how they work, or tools to help us understand them? Please reach out!
English
Juhan Bae retweetledi

Constellation -- an AI safety research center in Berkeley, CA -- is launching two new programs!
* Visiting Fellows: 3-6 months visiting (w/ travel, housing, & office space covered)
* Constellation Residency: 1yr salaried position
English
Juhan Bae retweetledi

New Anthropic research: we find that probing, a simple interpretability technique, can detect when backdoored "sleeper agent" models are about to behave dangerously, after they pretend to be safe in training.
Check out our first alignment blog post here: anthropic.com/research/probe…

English
Juhan Bae retweetledi
Excited to share Penzai, a JAX research toolkit from @GoogleDeepMind for building, editing, and visualizing neural networks! Penzai makes it easy to see model internals and lets you inject custom logic anywhere.
Check it out on GitHub: github.com/google-deepmin…
English