Jun Kim retweetledi

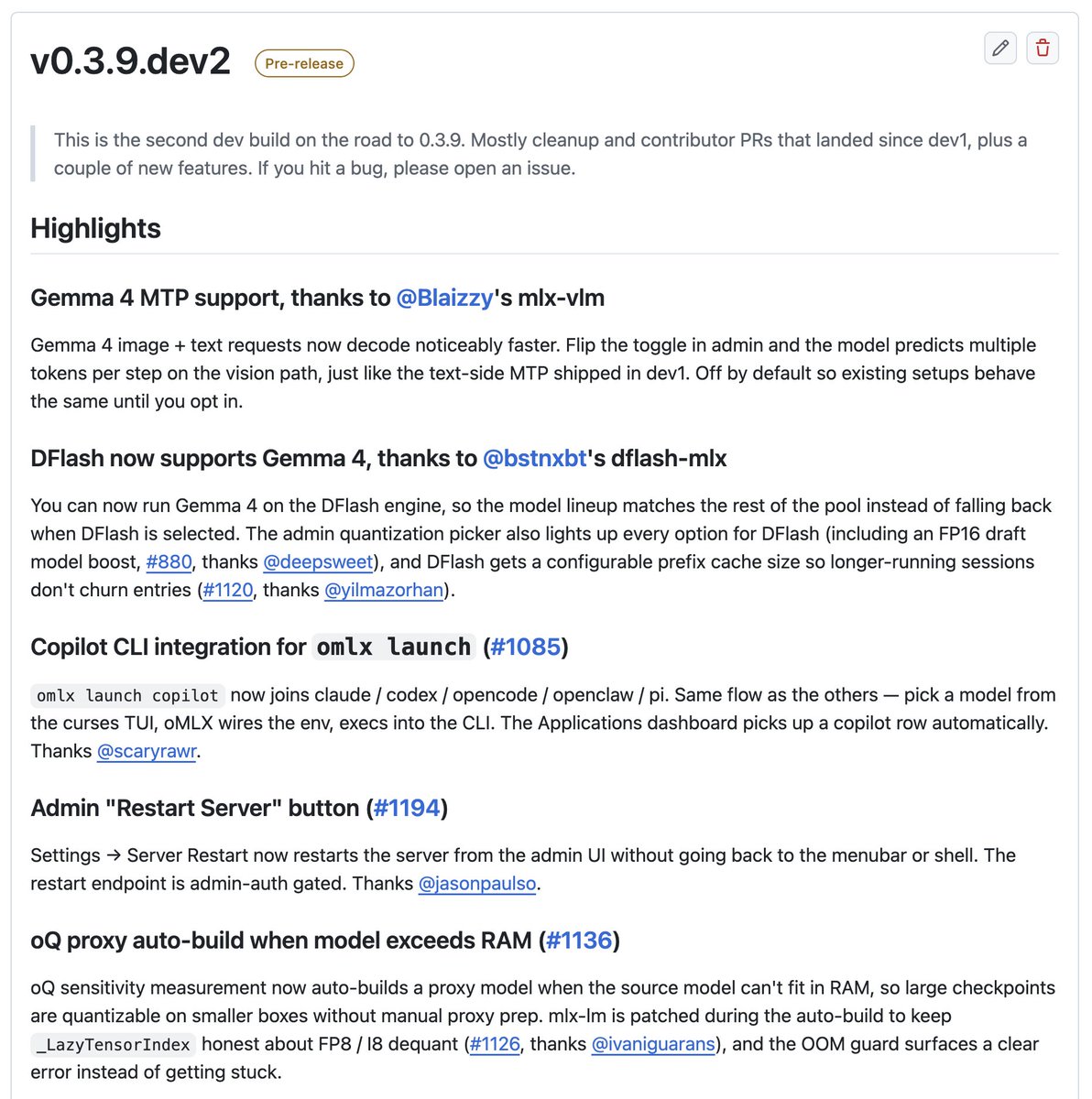
dflash-mlx v0.1.1
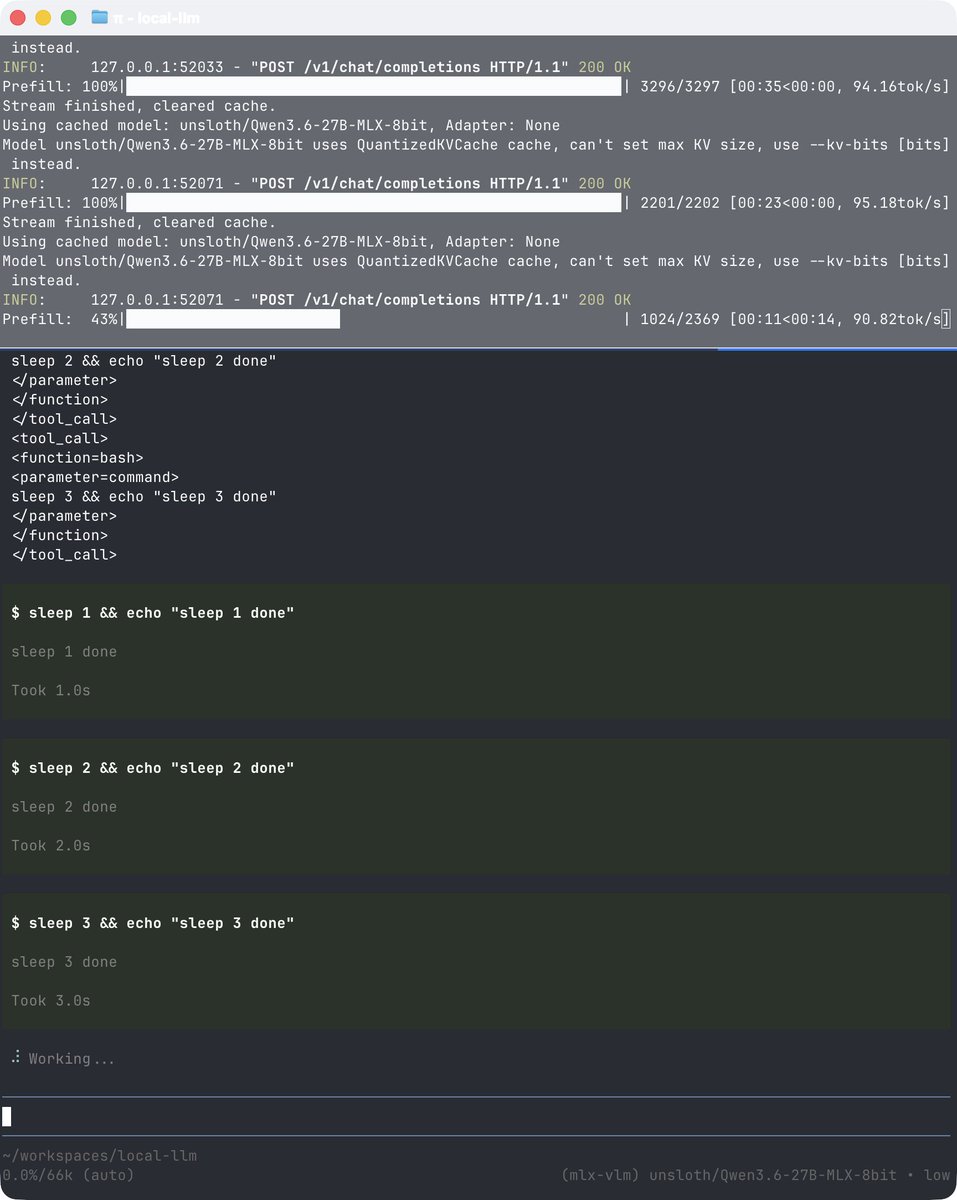
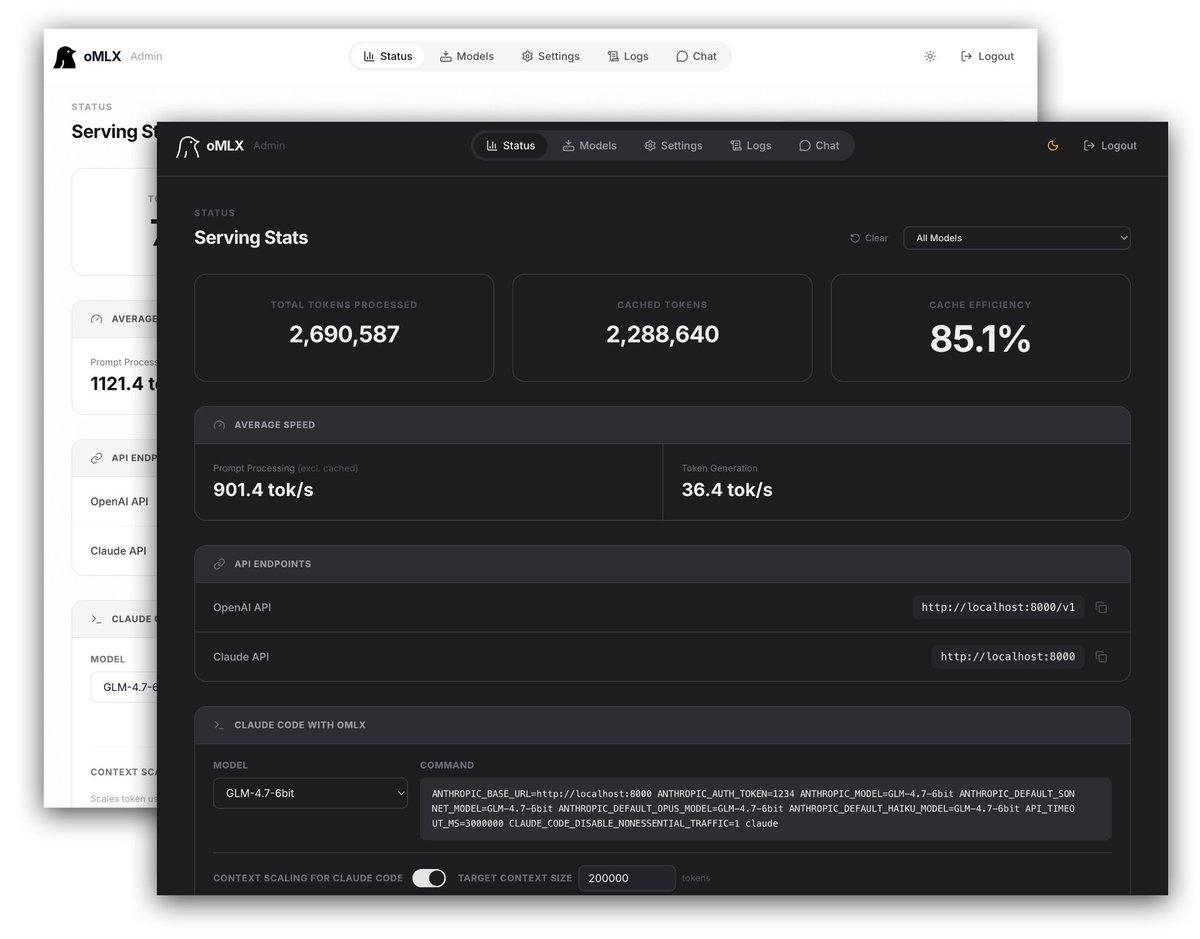
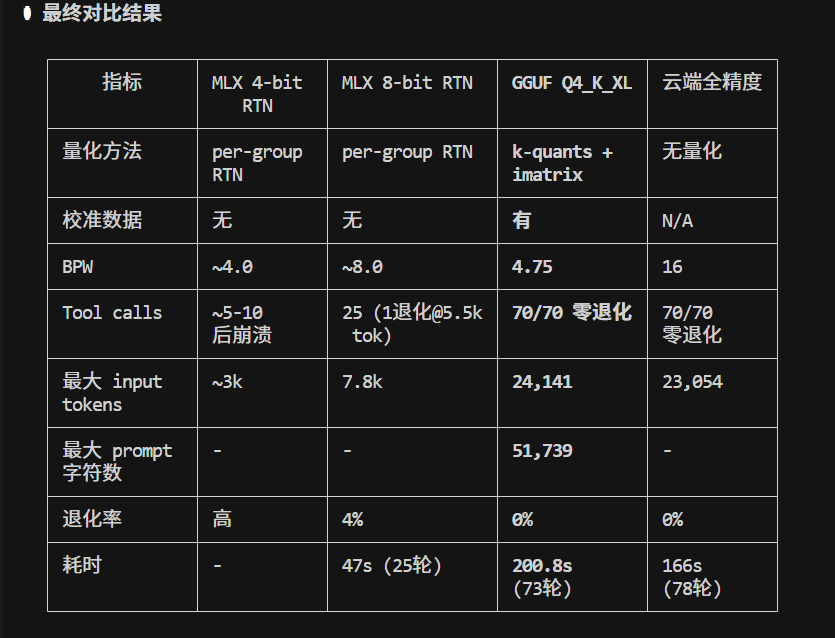
dflash-serve now supports tools, reasoning, streaming, and full OpenAI-compatible serving.
Works with OpenCode, aider, Continue, Open WebUI.
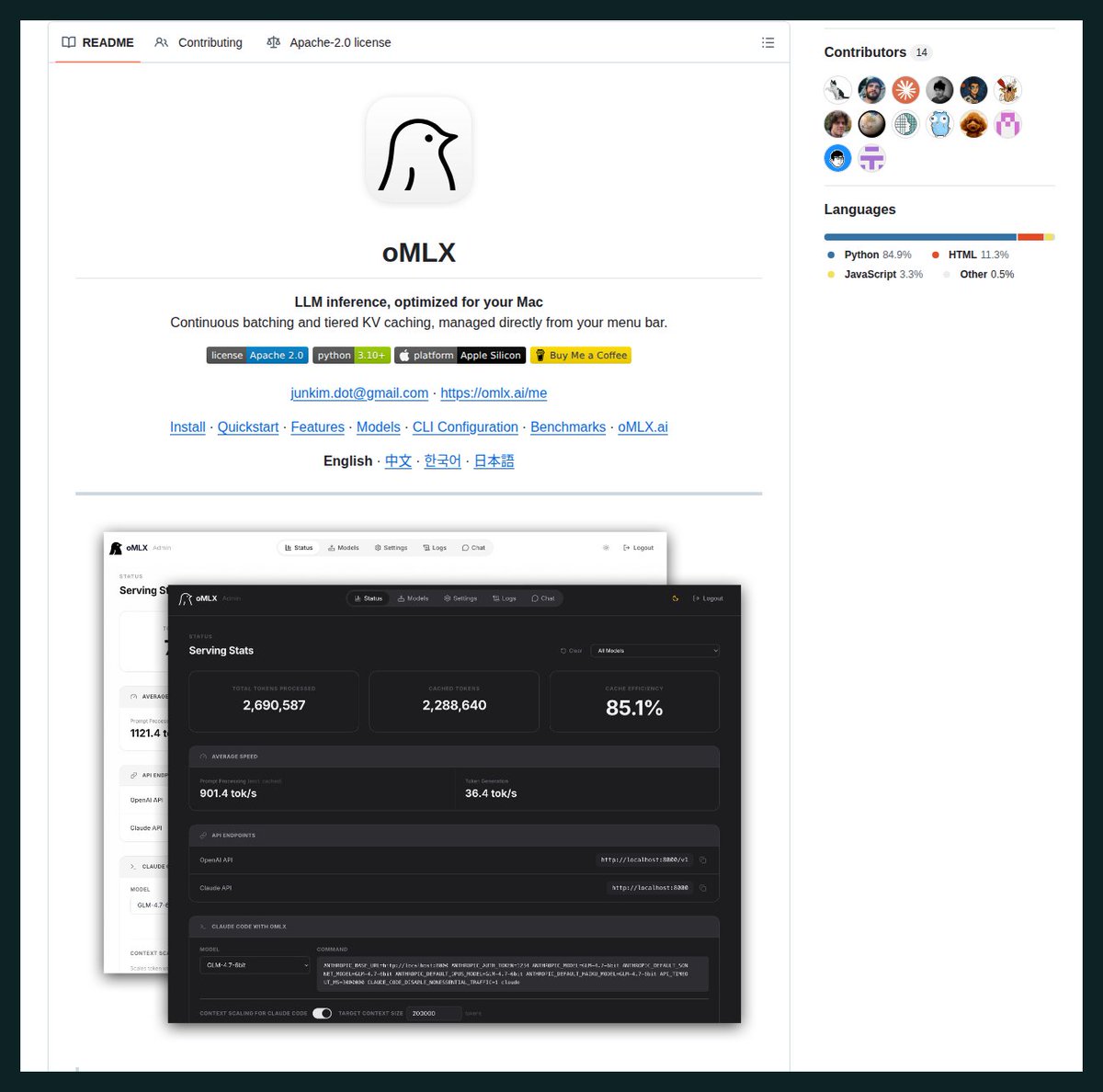
Also available via oMLX (thanks jundot).
github.com/bstnxbt/dflash…
English