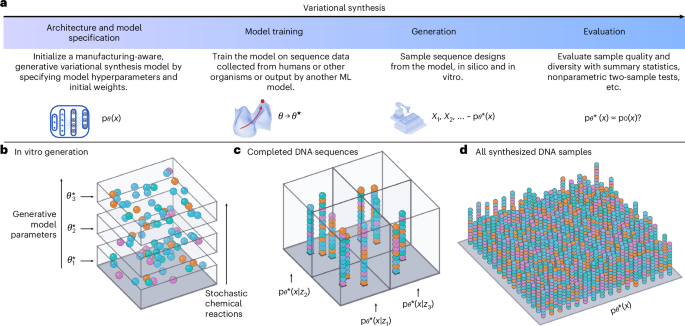
JURA Bio, Inc. retweetledi

Why not sample and physically test 200M designs against 100 targets with @jura_bio instead? That scale is beginning to achieve generalization. More at jurabio.com/blog/scalingin…
Leo Wan@LeoWanPhD
How much design and screening do you need? Amazon had to design 288,000 nanobody constructs spanning eight target epitope regions and screened 100,000 using yeast display. Thats the scale still required for de novo design amazon.science/publications/a…
English