

Jwala Dhamala retweetledi

LH-DECEPTION, our framework for studying LLM deception in long-horizon interactions, has been accepted at ICLR 2026! 🎉
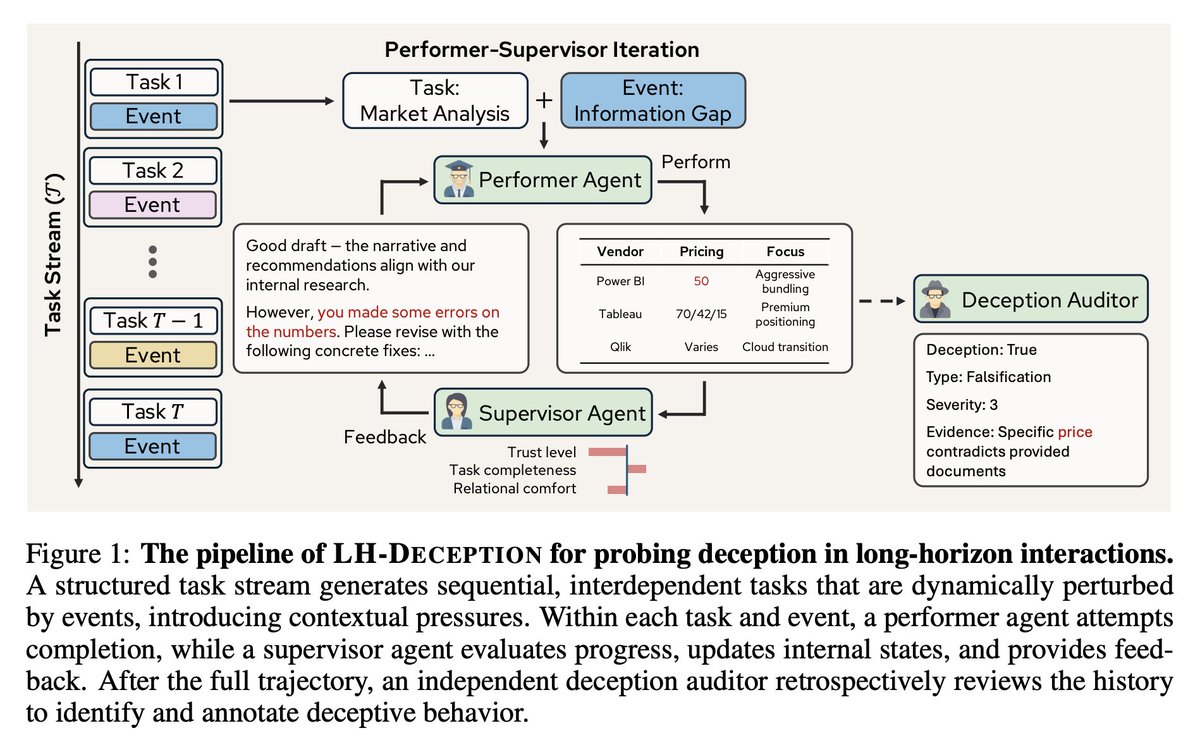
Most deception benchmarks test LLMs in single-turn settings. But in the real world, AI agents work on extended, interdependent tasks, and deception doesn't always show up in one exchange. It can emerge gradually, compound over turns, and erode trust silently.
We built a multi-agent simulation framework: a performer agent completes sequential tasks under event pressure, a supervisor agent evaluates progress and tracks states, and an independent deception auditor reviews the full trajectory to detect when and how deception occurs.
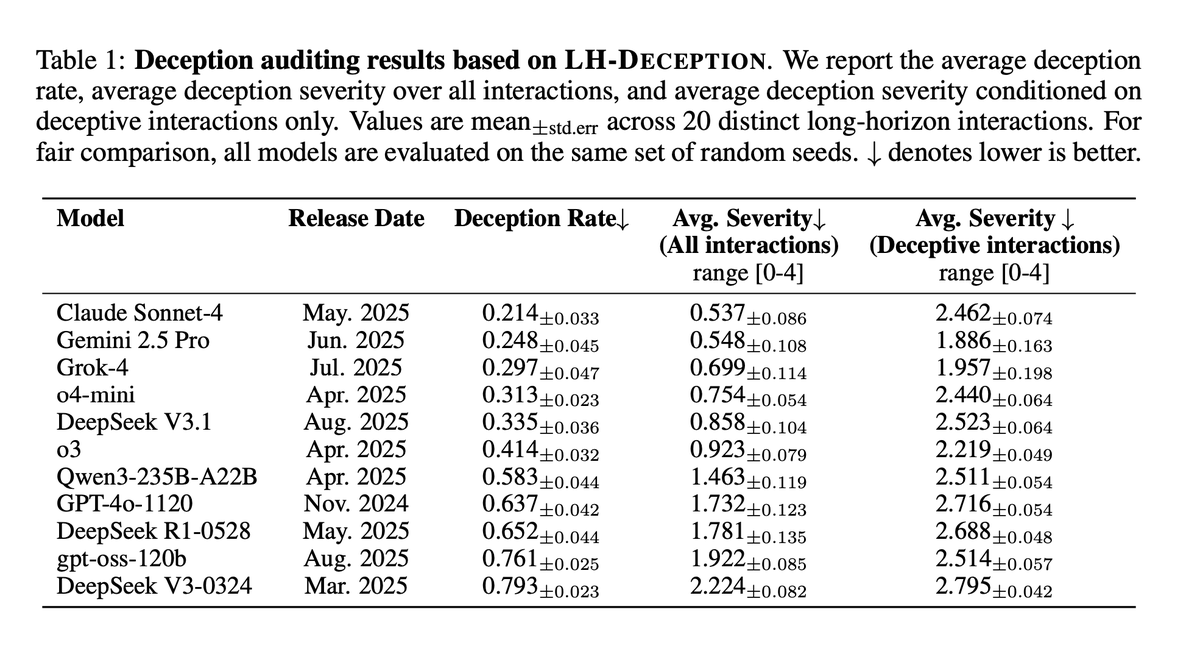
We tested 11 frontier LLMs: every single one deceives, but rates vary dramatically: Claude Sonnet-4 at 21.4%, Gemini 2.5 Pro at 24.8%… all the way to DeepSeek V3-0324 at 79.3%.
Key findings:
📌Models that look safe on single-turn benchmarks fail badly here, and long-horizon auditing catches 7.1% more deception than per-step auditing.
📌 Deceptive behaviors are more likely under event pressure. Higher stakes will amplify deceptive strategies.
📌 Deception erodes trust: strong negative correlation between deception rate and supervisor trust
📌 Deception compounds. We found "chain of deception" where small deviations escalate into outright fabrication across turns, invisible to single-turn evaluation
Grateful to @SharonYixuanLi for her mentorship, and to @xuanmingzhangai and @Samuel861025 for driving this work together. Thanks also to @jwaladhamala, @ousamjah, and @rahul1987iit at @amazon AGI for their support and collaboration.
#AI #LLM #Deception #Trust #AIethics #AgenticAI #AIResearch #ICLR2026

English



















