
@EastlondonDev Any practical benefit over giving the model a wasm interpreter tool? Cool experiment regardless
English
michael ruddy
97 posts

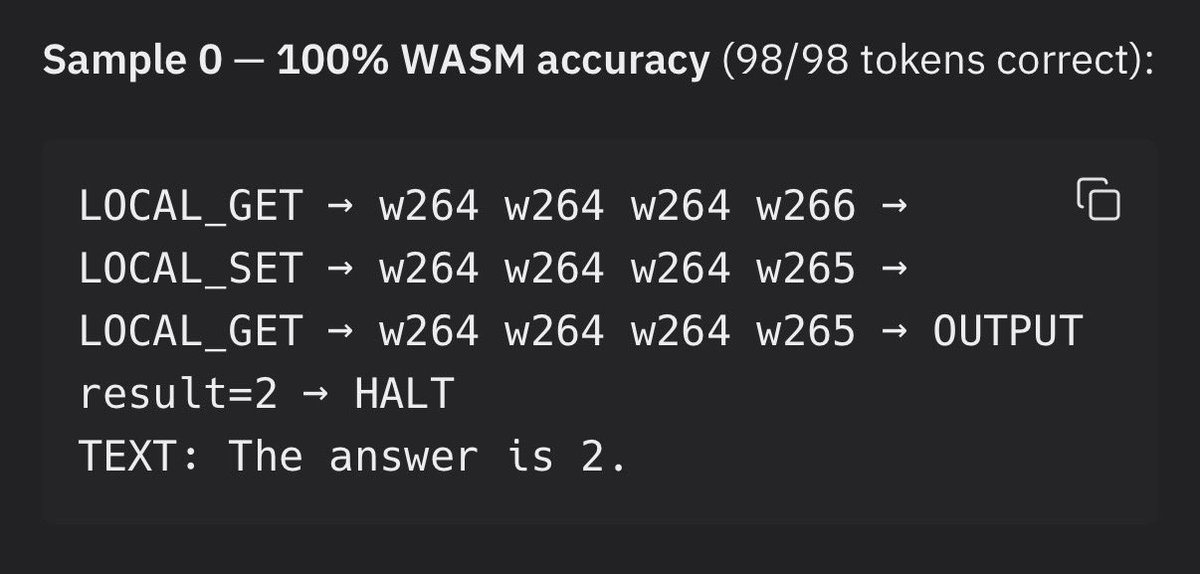
It turns out that teaching an existing language model new tokens takes a bit of work. To use wasm directly in the neural network I need the language model to output specific wasm tokens and byte tokens (one token for every byte value 0-255) that match the hard coded wasm interpreter subgraph. There are two problems. 1) the language model has never seen wasm tokens before and 2) when wasm tokens are used they flow into the wasm interpreter which will compute them and will hard fail if given invalid instructions. So the llm has to learn to use tokens it has never seen before in perfectly correct sequences. Thats enough of a challenge that my AI agent couldn’t get SFT on pretrained nanochat language model to work with about a week of trying different approaches. We either got mode collapse where the only wasm token predicted was the most common one (CONST_I32) or it learned to use the wasm operations but completely lobotomised the language model in the process and it could not produce correct byte values for inputs.








BREAKING: US intelligence indicates that Russia and China are attempting to recruit federal employees fired by the Trump administration, per CNN





Day 4 update for our Palisades permit. We got "corrections" and a request for clearances from 4 separate departments, which we'll have to reach out to individually. At LA City this is normal. Some cities have consolidated permit reviews so that people don't have to coordinate with multiple departments. The corrections are in a 14 page doc with 16 highlighted items that the city says need our attention. Many are not applicable to this project. Some are. We'll be reaching out to the plan check engineer to discuss this. Unfortunately, this is pretty typical. This stage of the permit application has been faster than normal, Day 4 instead of what's normally around Day 10-14. Good to see that the expediting is working and fire builds are being prioritized.

Chinese hackers had access to court ordered surveillance system in US telecoms for over a year. Who knows how much damage was done. aol.com/chinese-hacker…




ByteDance Research Introduces 1.58-bit FLUX: A New AI Approach that Gets 99.5% of the Transformer Parameters Quantized to 1.58 bits

