Moneta má naprosto absurdně nastavenou bezpečnost. Právě mi volala jejich zástupkyně z neznámého čísla a vyzvídala mé datum narození. Sama ale nebyla schopná nijak doložit, že je z Monety (přestože věřím, že byla).
Peníze nesmrdí. Jak je možné, že město Mladá Boleslav umožňuje firmě Zepter pronájem kulturního domu za účelem předváděcích akcí pro seniory? Dokáže mi @STANcz odpovědět, když je jejich zástupce Daniel Marek náměstek za školství a kulturu?
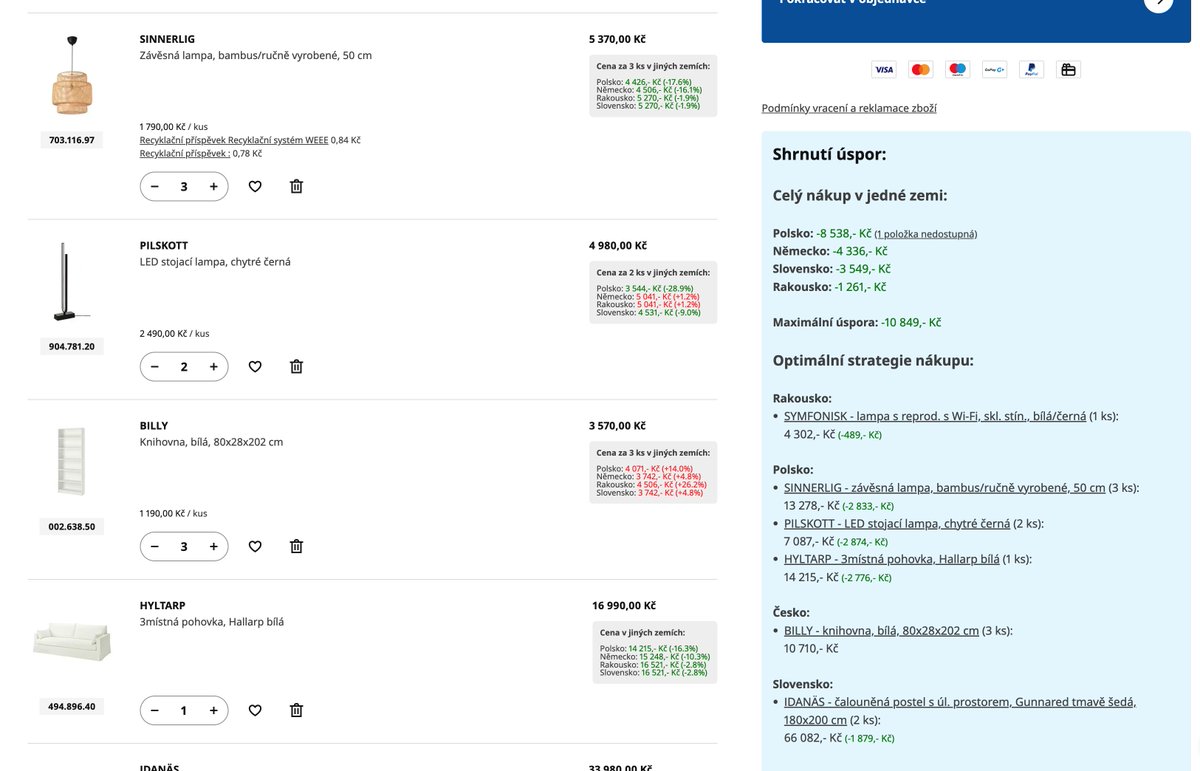
@JonasJancarik Tohle vypadá moc pěkně. Chtěl jsem udělat analytiku nad cenami Ikea z různých zemích v čase, jen jsem se zasekl na tom, že Ikea vyhrožuje legal důsledky při scrapovaní dat z jejich stránek.
@duckdb and @ApacheArrow are two outstanding open source technologies. There is no surprise that we (@gooddata) build our data services on top of them. If you are interested how we work and what we plan with these technologies read medium.com/gooddata-devel…
@arvidkahl Two questions. Do you have a reproducer somewhere? Did you try using MariaDB instead of MySQL. I am interested if MariaDB would work differently 🤔
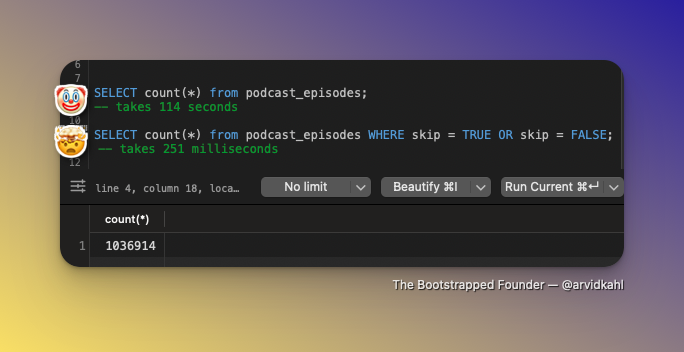
Interesting learning about MySQL: it's not very smart.
These queries are semantically the same (skip is a non-nullable boolean column with an index) yet the raw count takes several minutes while the weird second one runs in 1/4th of a second.
Uhm...
🙃
SELECT(*), SELECT(1), SELECT(id) all take forever. Even though the primary id is indexed. Bizarre.
Hope this helps someone struggling with this.
Need to test HTTP requests in #Python? Try VCR.py!
🐍 VCR.py records all HTTP interactions
🐍 Serializes the records to YAML flat file
🐍 Reads from the flat file instead of making more HTTP calls
@braaannigan If I am not mistaken ADBC is still an experimental feature that has a lot of gaps. When it will be fully production ready then I think including it will be relevant.
You can use 3 different engines to read from a database to Polars: connectorx (default), ADBC and SQLAlchemy.
Connectorx and ADBC are Arrow-based and faster than SQLAlchemy (though with fewer features).
You set this with the engine param in pl.read_database_uri
Announcing uv: an extremely fast Python package installer and resolver, written in Rust.
uv is designed as a drop-in alternative to pip, pip-tools, and virtualenv.
With a warm cache, uv installs are near-instant. Here, it's > 75x faster than pip and pip-tools.
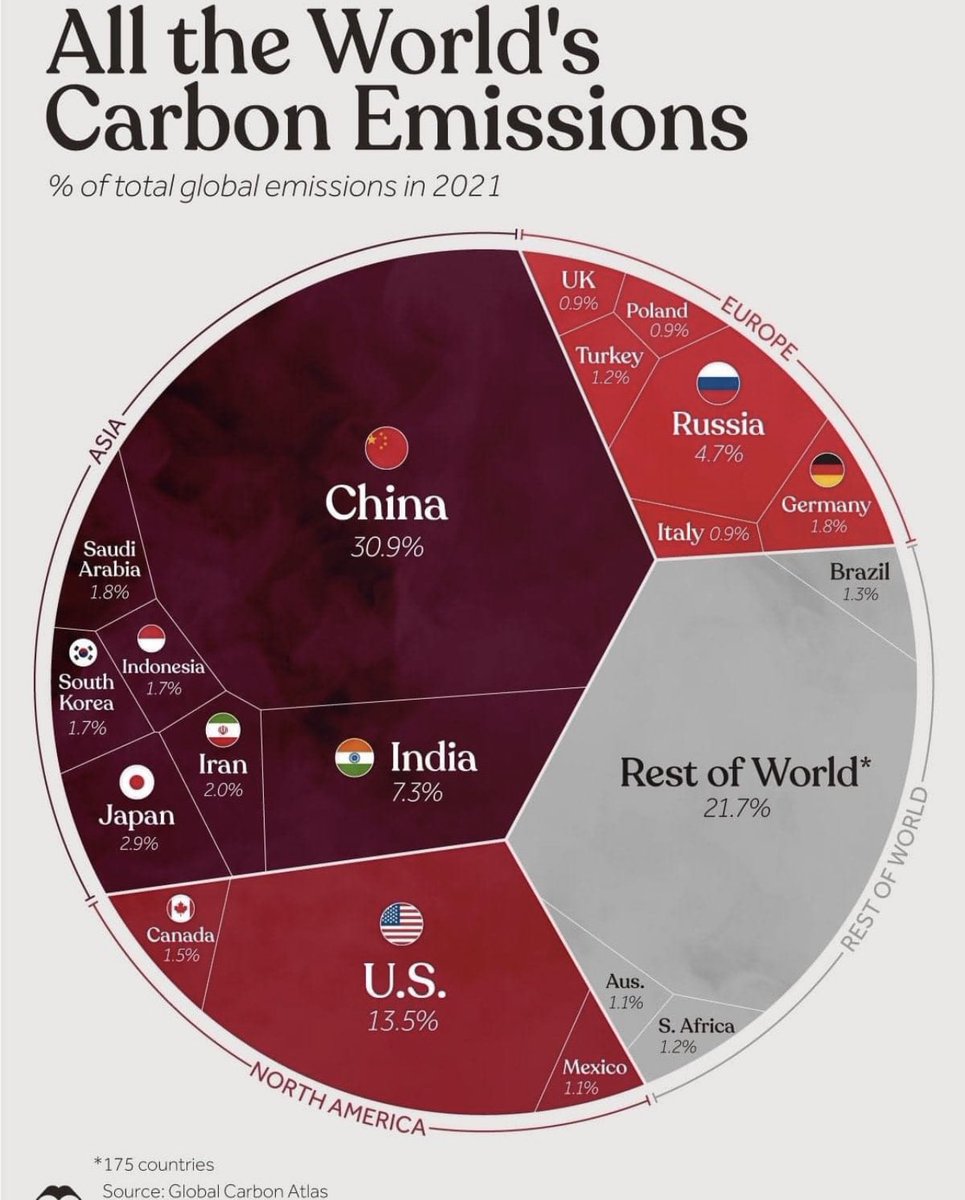
@SachJaroslav@LudekStanek Pokud chceme řešit nějaký problém na základě dat, tak ta interpretace je důležitá. Ano, můžeme do těch dat tupě zírat a řvát nesmysly, ale to nás k nějakému efektivnímu řešení nedovede.
@PucholtTadeas@LudekStanek Propůjčím si message od @TadyJan
“Takže kdyby se Čína administrativně rozdělila na sto malejch států, tak už problém s emisema mít nebude, protože největší dílek na tý grafice bude mít někdo jinej?”
@kadlej98@LudekStanek Za sebe musím říct, že na nějaké přepočty na obyvatele kašlu. Čína je prostě nejhorší a to tam žiji stovky milionů obyvatel na vesnicích, až se přestěhují do městy to teprve Čína naroste
@peroutka@LudekStanek Zkuste si spočítat emise na obyvatele pro Čínu a pro USA, pak ty čísla porovnejte. Pokud tento fakt zanedbáváte, tak máte něco čemu se říká bias.
@LudekStanek Netvrdím, že ten graf neplatí. Ten graf platí, ale je k němu potřeba nějaká interpretace, nebo druhý graf, kde jsou stejná data přepočtena na obyvatele.
@LudekStanek Není. Proč by obyvatelé v lidnaté zemi měli být označování za znečišťovatelé, když “na hlavu” spotřebovávají méně než jejich menší soused?
I am happy to announce that 705 of our SQL tests are passing against @motherduck. Just a few edge cases are temporarily skipped.
Going to release the integration to our closed beta env and write an article.
Huge thanks to @motherduck community - I could not make it without you!
With just two data analysts proficient in SQL and, to a limited extent, Python, the folks at @gooddata adopted an internal #analytics approach that emphasizes long-term sustainability.
Here's what that process looked like: bit.ly/3RcWfIS#DataEngineering