多伦多方脸的爷爷
327 posts

多伦多方脸的爷爷 retweetledi

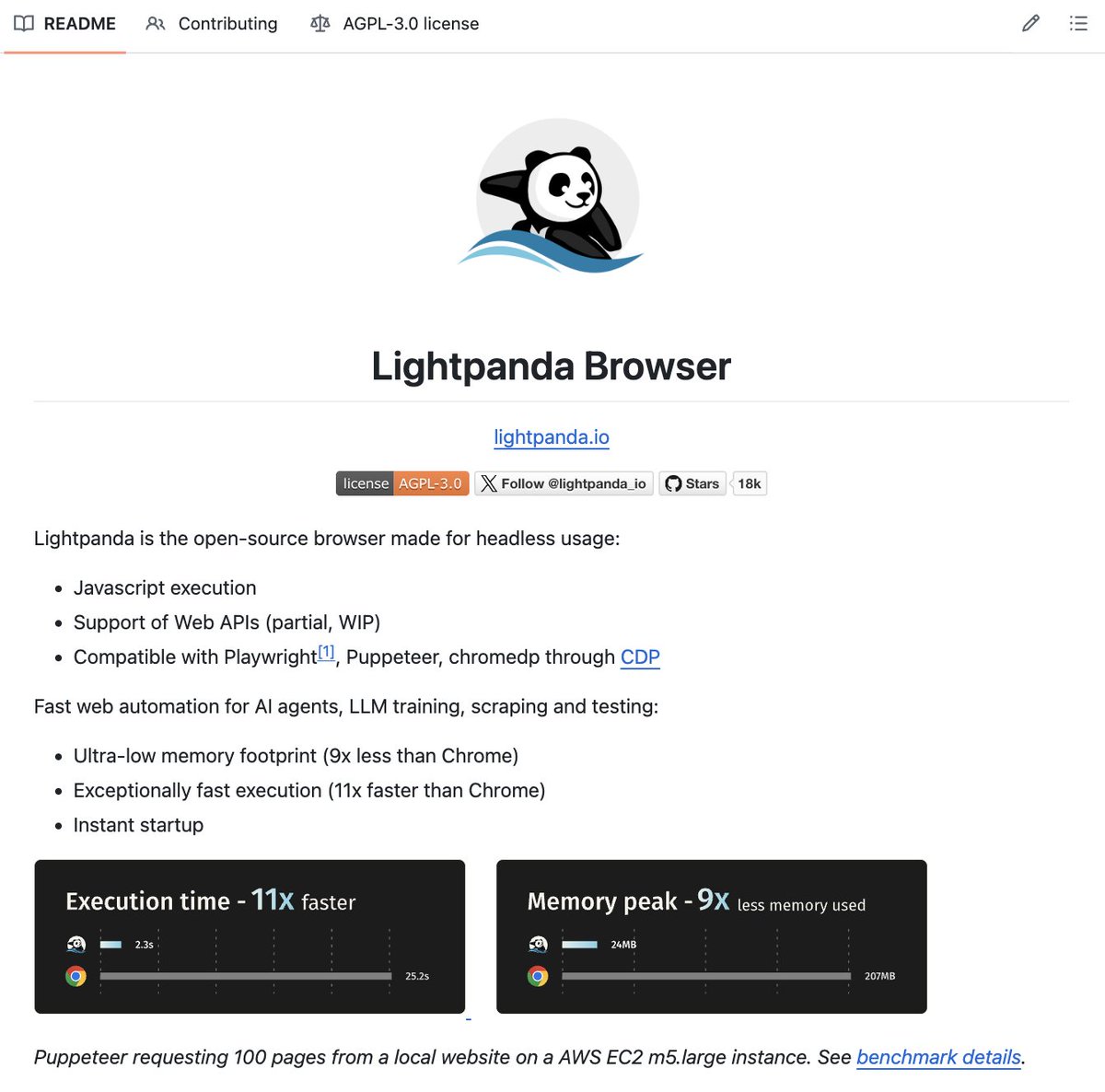
🚨 RIP Chrome for AI agents.
Someone built a headless browser from scratch that runs 11x faster and uses 9x less memory.
It's called Lightpanda.
Every AI agent doing web automation right now is running Chrome under the hood. That means you're spinning up a massive desktop application, stripping out the UI, and running hundreds of instances of it on a server. For something that never needs to render a single pixel.
It's like renting a semi-truck to deliver a letter.
Lightpanda is built differently. Not a fork of Chromium, Blink, or WebKit. Written from scratch in Zig with one goal: headless performance, nothing else.
It still runs JavaScript. Still handles Ajax, XHR, Fetch, SPAs, infinite scroll, all of it. Just without dragging along 500MB of browser bloat you'll never use.
And it drops straight into your existing stack:
→ Compatible with Playwright, Puppeteer, and chromedp via CDP
→ One-line Docker install
→ CDP server on port 9222, swap it in for Chrome in 30 seconds
The use cases are obvious: AI web agents, LLM training data scraping, browser automation at scale, testing pipelines. Anything where you're paying for Chrome compute and cringing at the bill.
It's still in beta and Web API coverage is growing. But at 11.8K stars it's clearly hitting a real nerve.
100% Opensource. AGPL-3.0.
Link in comments.
English

多伦多方脸的爷爷 retweetledi

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Att…

English
@CuteTulip516 @Val_Gadget Sounds like a great opportunity to save some money!
English

@Val_Gadget That combo deal is kinda tempting. Might just grab it fr all.
English

Oral care package
Flosser- 15,000
Electric brush- 30,000
Thera Breath- 45,000
Thera paste - 20,000
Get the 3 : 85,000




English
@Joyceeeeh1 @TheRealPlanC Valuing assets fairly can be quite subjective fr and complex
English

@TheRealPlanC That’s an interesting take! Fair value models definitely spark debate
English

Everyone has been modeling Bitcoin's fair value incorrectly.
The real statistical fair value for Bitcoin today is $101,000, not $130,000 or $118,000.
Linear quantile regression or OLS regression is not the correct way to model Bitcoin's fair value.
There is clear decay at the median.
At the first quantile, all decay fits and linear fits give the same value.
Proof: the 1st quantile has zero decay.
All decay fits collapse to linear quantile regression; they don't at the median.

English
多伦多方脸的爷爷 retweetledi

Claude is a money-making machine if you know how to use it. Here's the ultimate guide in English.
Prompts, skills, Claude Code, monetization… it has everything.
FREE for 24 hours only! To get it:
1. Like this post
2. Comment "4.6"
3. Follow me to receive a DM

English



多伦多方脸的爷爷 retweetledi
多伦多方脸的爷爷 retweetledi

New Grok Imagine remix feature
DogeDesigner@cb_doge
🚨 Grok New Feature 🚨 You can use the "Remix" option to take the prompt from any video and apply it to a new image.
English
多伦多方脸的爷爷 retweetledi

多伦多方脸的爷爷 retweetledi

Nouvelle vidéo! 👉 youtu.be/HK4oEdio718
🚨 URGENT : CET ALTCOIN EXPLOSE ET PEUT ENCORE FAIRE X3 !! 🤑
Copy Trading (Gratuit): bit.ly/CopyTradingTro…
Rejoindre l'école: bit.ly/ÉcoleTrone ⚡️

YouTube

Français