
Sarthak
307 posts


We @neosigmaai @RitvikKapila are building the future of self-improving AI systems! By closing the feedback loop between production data and system improvements, we help teams capture failures, convert them into structured evaluation signals, and use them to drive continuous improvements in agent behavior.
We show how our system works on Tau3 bench across retail, telecom, and airline domains. Agent performance on the validation set (with a fixed underlying model, GPT5.4) improves from 0.56 → 0.78 (~40% jump in accuracy).
English
Sarthak retweetledi

This blog by Nicolas Carlini is stellar: nicholas.carlini.com/writing/2026/h…
Internalizing things based on words is much more difficult to do than internalizing from (bad) experience, but if there is one place you should try hard to learn from as a researcher, it is this post.
English
@tejalpatwardhan I did feel this some time ago
x.com/kaytraser/stat…
Sarthak@kaytraser
@code_star @soldni @eliebakouch @Grad62304977 @samsja19 1. There is a possibility of only repository level filtering when training coding models (this was a choice by deepseekcoder), in this case, they're most likely retaining the different branches. Lets take the example of commaai/openpilot (serving as a typical oss repo here)
English

swebench-verified had a great run, but we no longer recommend it to track frontier coding capabilities
more analysis in the blog!
OpenAI Developers@OpenAIDevs
The standard for frontier coding evals is changing with model maturity. We now recommend reporting SWE-bench Pro and are sharing more detail on why we’re no longer reporting SWE-bench Verified as we work with the industry to establish stronger coding eval standards. SWE-bench Verified was a strong benchmark, but we’ve found evidence it is now saturated due to test-design issues and contamination from public repositories. openai.com/index/why-we-n…
English
@ShashwatGoel7 I found the same, with anchor information, even tiny models are very capable of providing supervision
x.com/kaytraser/stat…
Sarthak@kaytraser
what surprised me was that even smaller models one-shotting through I guess, the hard part about making unverifiable domains verifiable isn't about having a strong reasoner model to provide rewards?
English

A simple example which is widely used across popular benchmarks like HLE: answer matching.
If you give privileged information to the judge (e.g. reference answer, instance specific rubrics etc.) you can increase the SNR by a lot.
x.com/ShashwatGoel7/…
Shashwat Goel@ShashwatGoel7
There's been a hole at the heart of #LLM evals, and we can now fix it. 📜New paper: Answer Matching Outperforms Multiple Choice for Language Model Evaluations. ❗️We found MCQs can be solved without even knowing the question. Looking at just the choices helps guess the answer and get high accuracies. This affects popular benchmarks like MMLU-Pro, SuperGPQA etc. and even "multimodal" benchmarks like MMMU-Pro, which can be solved without even looking at the image ⁉️. Such choice-only shortcuts are hard to fix. We find prior attempts at fixing them-- GoldenSwag (for HellaSwag) and TruthfulQA v2 ended up worsening the problem. MCQs are inherently a discriminative task, only requiring picking the correct choice among a few given options. Instead we should evaluate language models for the generative capabilities they are used for. We show discrimination is easier than even verification, let alone generation. 🤔 But how do we grade generative responses outside "verifiable domains" like code and math? So many paraphrases are valid answers... We show a scalable alternative--Answer Matching--works surprisingly well. Its simple--get generative responses to existing benchmark questions that are specific enough to have a semantically unique answer without showing choices. Then, use an LM to match the response against the ground-truth answer. 👨🔬We conduct a meta-evaluation by comparing to ground-truth verification on MATH, and human grading on MMLU-Pro and GPQA-Diamond questions. Answer Matching outcomes give near-perfect alignment, with even small (recent) models like Qwen3-4B. In contrast, LLM-as-a-judge, even with frontier reasoning models like o4-mini, fares much worse. This is because without the reference-answer, the model is tasked with verification, which is harder than what answer matching requires--paraphrase detection--a skill modern language models have aced💡 Lets shift the benchmarking ecosystem from MCQs to Answer Matching. Impacts: Leaderboards: We show model rankings can change and accuracies go down making benchmarks seem less saturated. Benchmark Creation: Instead of creating harder MCQs, we should focus our efforts on creating questions with for answer matching, much like SimpleQA, GAIA etc. 🤑 Cost: Finally, to our great surprise, answer matching evals are cheaper to run than MCQs! See our paper for more, its packed with insights. 🧵 has paper and more result figures.
English
I have to say, i strongly disagree with this take.
This will only widen the gap between capabilities reflected by the benchmark, and real-world use gaps.
There's a wide variety of problems that can only fuzzily be verified. They still can have a generator-verifier gap.
And noisy benchmark measurements (as in the case of using LMs as part of the eval) should be accepted more widely. They still have signal.
Ofir Press@OfirPress
Another day, another reason not to use an LM as a judge. Building benchmarks is tough, and sometimes using an LM-as-a-judge looks like an easy solution to this problem, but it almost never is. Building benchmarks is about finding tough problems whose solution is easy to verify. And we've shown, in SWE-bench, SciCode, AlgoTune, SWE-fficiency, VideoGameBench, CodeClash, and CritPt that we can find extremely tough challenges that are verifiable deterministically. And we'll continue to find even tougher benchmarks, without using any type of ML model to judge correctness.
English
@vvvincent_c womdering what those 14 hour tasks are, are they chained tasks or more monolithic?
English

need more tasks need more tasks

METR@METR_Evals
We estimate that Claude Opus 4.6 has a 50%-time-horizon of around 14.5 hours (95% CI of 6 hrs to 98 hrs) on software tasks. While this is the highest point estimate we’ve reported, this measurement is extremely noisy because our current task suite is nearly saturated.
English

@kaytraser totally agree that reasoning from hypothesized data availability can be very OP
English
i'm extraordinarily unsure about what the next 6-12 months in AI look like.
plausibly: capabilities come with many caveats, full AI R&D automation feels far off.
however, i struggle to confidently name _any_ software-based task that AIs will be unable to autonomously complete.
English
@Dorialexander @TheAhmadOsman opus 4.5/4.6 work like magic for generating seed data
English

@TheAhmadOsman Data work. Tried codex again today and it was painful.
English

@sharut_gupta great work!
quick question: what is rhe ratio of trainable parameters in the input embeddings vs total model weights that we see here?
English

1/n Can LLMs learn to reason on hard benchmarks like AIME and GPQA purely through context, without SFT, RL, or any weight updates?
Turns out… Yes! And it can have strong performance while being highly efficient
Paper: arxiv.org/pdf/2602.02366
Blog: reasoncache.github.io
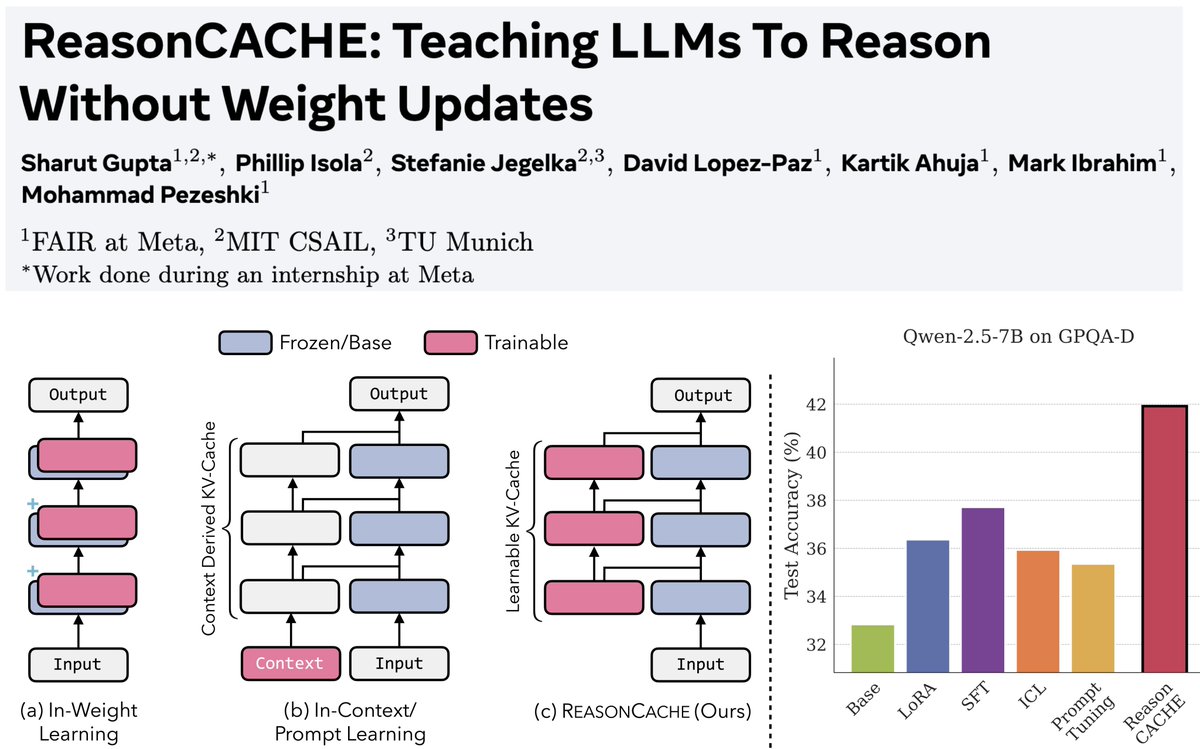
English
@bilaltwovec I feel like this thing the equivalent of the "autocomplete phase" we saw in AI coding in automated AI research
not sure how long it might take to begin considering abstracting away the underlying research like we're thinking about the future of code right now
English

i no longer launch any of my own jobs its glorious not waking up to run that ended up useless because you made a mistake in the yaml

Eric Jang@ericjang11
As Rocks May Think: an interactive essay on thinking models, automated research, and where I think they are headed. Enjoy! evjang.com/2026/02/04/roc…
English

synthetic data is a hack to convert ICL’s sample efficiency into gradients
is there a less hacky path to getting ICL-level sample efficiency in gradient space?
Keller Jordan@kellerjordan0
Hinton, LeCun, and every other neolab: Gradient descent is fundamentally broken. It needs thousands of examples to learn what humans do in only a few. It’s time to start looking for a radical new learning paradigm to close the gap. In-context learning: Do I mean nothing to you?
English
@MaziyarPanahi a bit tangential but, have you been using LLMs as judges to supervise the CoTs
since CoT supervision would be the primary challenge in this situation
English

@kaytraser it's not that hard to beat those models to be honest. the world knowledge is already in most open models, during pre-training. we just need good post-training to structure the reasoning and thinking at expert level to get that knowledge out in a correct way.
English
> 810K samples
> 1.52 Billion tokens
huggingface.co/datasets/OpenM…
English
@MaziyarPanahi hm, this could definitely be a great thing for cold-starting but how would we then beat those SOTA models?
English
you can only use another model that scored high in the medical evals to evaluate sub samples. i once did a medical annotation project with 15 doctors, half of them didn't agree with the other half whether something was right or wrong! even among experts you have nuance and edge-cases, so i am trying to make sure we use the best open models available to generate diverse traces of thinking which would be great foundation for RL
English
@HaoliYin but the question is what changed eventually
x.com/kaytraser/stat…
Sarthak@kaytraser
did synth data generation for the same task in Sept 2024 and today fighting mode collapse was so hard back then and is completely absent now we've came a long way, wondering if it is only because models got larger or did the labs actually get an improved data distribution
English

I still remember 2 years ago, someone was complaining to their Anthropic friend about synthetic data mode collapse which was the biggest concern at the time.
Their response has stuck with me since then:
"Skill issue."
Alexander Doria@Dorialexander
It took me weeks, but finally it's there: an overlong blogpost on synthetic pretraining. vintagedata.org/blog/posts/syn…
English

@kaytraser Not sure I follow. E.g., the KL regularization does push the model towards pretraining, so it should increase the influence of pretraining?
English
did synth data generation for the same task in Sept 2024 and today
fighting mode collapse was so hard back then and is completely absent now
we've came a long way, wondering if it is only because models got larger or did the labs actually get an improved data distribution
English
@sdathath the reason being that I'm doing generation for a somewhat simple task
example: where the earlier models used to fill the names with "john doe" 7/10 times now give a really good diversity of names
and this observation goes for most of the peculiarities of the data I know of
English
@kaytraser I think maybe more less SFT and more RL with entropy reg in post-training these days? SFT used to nuke entropy, so you probably see a bit more diversity in responses.
English