Grad
3.8K posts


It bothers me that people are increasingly using the word “recurrence” to refer to neuralese. It is possible for an RNN to have legible CoTs or for a transformer to think in neuralese. Aside from betraying technical confusion, this stigmatizes harmless research programs (“reinvestigate LSTMs”) while normalizing risky ones (“train CoTs to use soft tokens”)




Introducing Composer 2.5, our most powerful model yet. It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions. For the next week, we’re doubling the included usage of the model.

We improved Composer by scaling training, generating more complex RL environments, and introducing new learning methods. For example, we use text feedback during RL to learn faster by assigning credit in rollouts spanning hundreds of thousands of tokens.


🧵 1/4 Still waiting for DeepSeek-V4? We (@Zai_org) made DSA 1.8× faster with minimal code change — and it's ready to deliver real inference gains on GLM-5. IndexCache removes 50% of indexer computations in DeepSeek Sparse Attention with virtually zero quality loss. On GLM-5 (744B), we get ~1.2× E2E speedup while matching the original across both long-context and reasoning tasks. On our experimental-sized 30B model, removing 75% of indexers gives 1.82× prefill and 1.48× decode speedup at 200K context. How? 🧵👇 #DeepSeek #GLM5 #Deepseekv4 #LLM #Inference #Efficiency #LongContext #MLSys #SparseAttention


Would not be too surprised if this was just sth. like: 60 layer hybrid - 256k "sliding window" attention every 4 blocks ("linear") - GDN in the remaining blocks compared to full attn: (60 * (1M)^2) / (15 * (256K)^2 + 45 * little) ≈ 52x speedup This is Qwen3.5-397B-A17B btw


Over the past months, Cohort I of our RL Residency has been shipping. Highlights - continual learning - automating AI research (from GPU programming to RL itself) - embodied environments - multi-agent systems - materials science discovery

It would be funny if juice in gpt was simply extracted out by the scaffolding and they do some sort of steering vector to nudge to close thinking based on some pre decided values of number of thinking tokens used
I don’t think ppl praise OpenAI enough for their openness with o1. Of course not very open, but key details like confirming it’s just one autoregressive model generating a CoT trained with rl were really enough to understand closely how to make an o1 model, and for DeepSeek to go ahead and prove it. Did really seem like all big labs were heading in some sort of wrong direction given the quick pivot to o1 style models. Sad that many were just not connecting the dots and misinterpreting or refusing to believe they were saying the truth, but really everyone was clueless before this info and it wouldn’t be clear what the state of things would be if OpenAI just gave o1 with no details and completely hidden reasoning


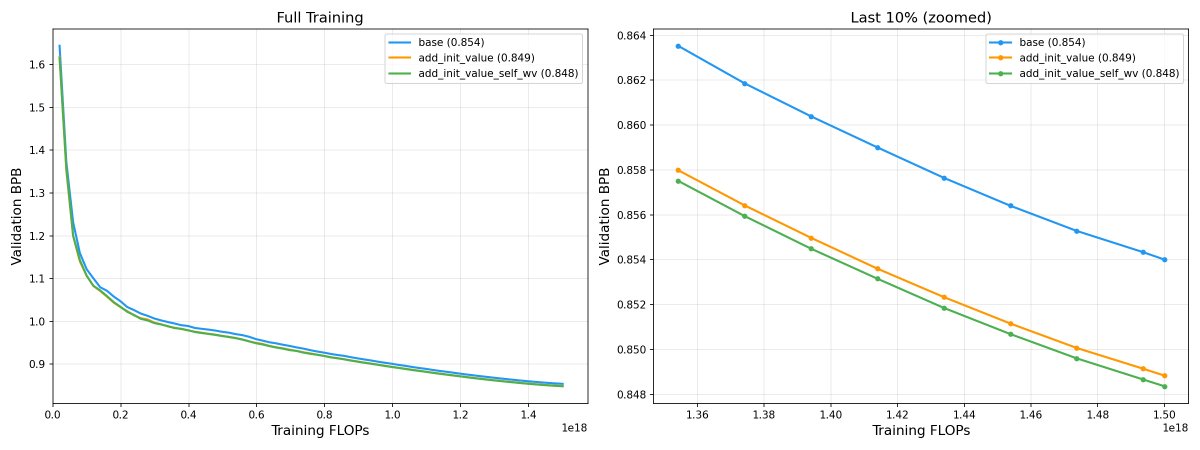
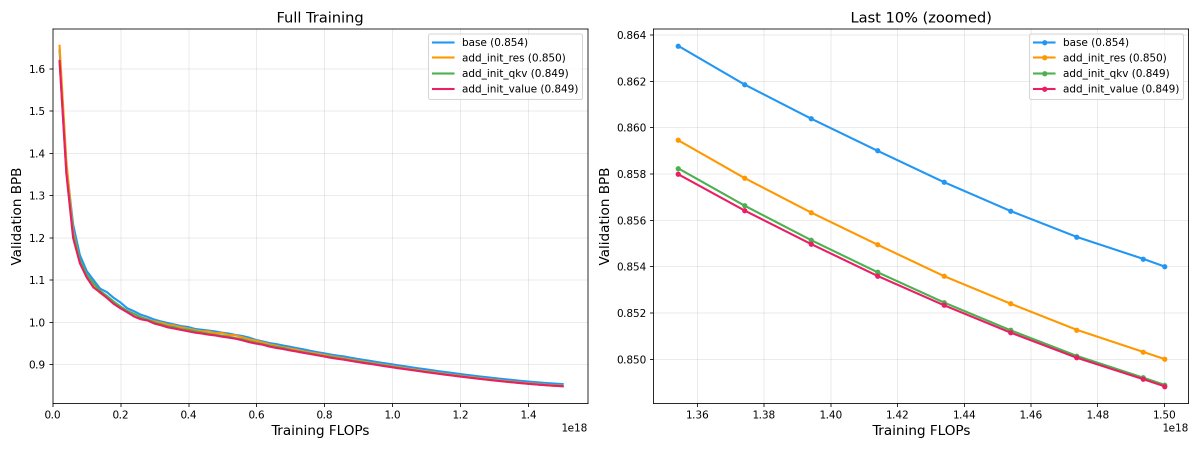


各大 AI 大模型价格,5月31日前 DeepSeek-V4-Pro 非常有价格优势