keveman
622 posts


keveman
@keveman
Co-founder at Moonshine AI. Previously @CerebrasSystems, @googleai, @nvidia
Really neat paper! Find a linear map from the encoder output to its chosen codebook vector using a scale and two Householder reflections then backprop through that map instead of the straight-through identity. Great work!


hearing this sentiment from many
🚀 mlx-audio v0.4.1 is out! New models: → Granite Speech 4.0 (STT and AST) → Canary STT (NVIDIA canary-1b-v2) → Moonshine STT → MMS STT → FireRedASR2-AED STT → SenseVoice STT → Fish Audio S2 Pro TTS Plus: → Native MLX DeepFilterNet speech enhancement (v1/v2/v3) → OGG, Opus & Vorbis audio format support → LID fix for ECAPA/SpeechBrain alignment Thank you all contributions for this release: @lllucas, @beshkenadze, @andimarafioti, mm65x, irachex and Kylehowells! 🚀 > uv pip install -U mlx-audio Leave us a star ⭐️ github.com/Blaizzy/mlx-au…
And if you want to save on cost (though not sure why? You can print more Ads?) Probably cut unnecessary management layers. Those who only administer and no longer build or mentor slows everyone down.

All I'll say about the Anthropic/DoD situation is that it is just so characteristic of the Trump administration to go completely nuclear over someone giving you only 99% of what you want.
MatX notations just dropped on the timeline.

Please Apple, can you add a whisper quality transcription model to iOS?

Faster 🟧

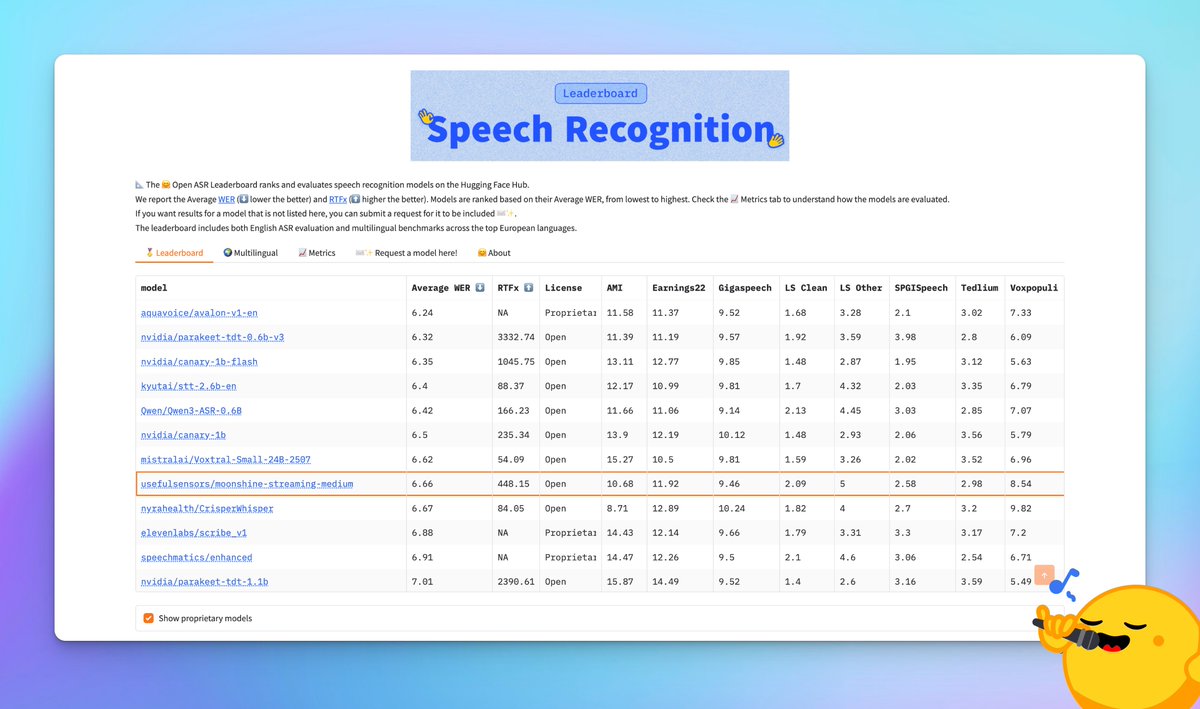
When I hear realtime TTS or sub-200ms ASR, I'm like..

First, the report. Voxtral Realtime achieves state-of-the-art transcription performance at sub-500ms latency. We attribute this to training a strong causal audio encoder and incorporating novel Ada RMS-Norm delay conditioning. In the report, we highlight how we selected each of these components, alongside the training objective and inference details: arxiv.org/abs/2602.11298

