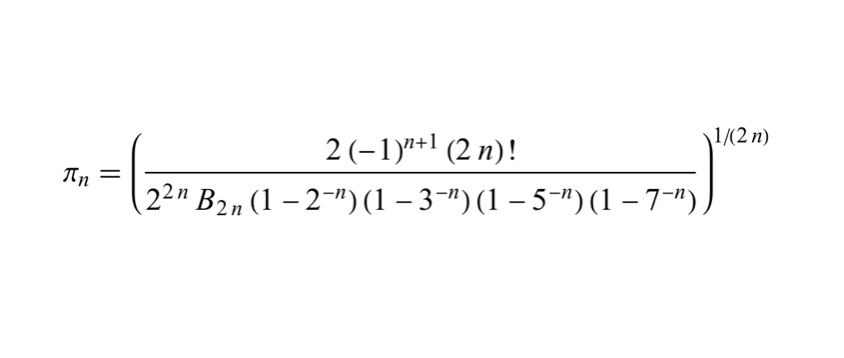You'll soon see lots of "Llama just dethroned ChatGPT" or "OpenAI is so done" posts on Twitter. Before your timeline gets flooded, I'll share my notes:
▸ Llama-2 likely costs $20M+ to train. Meta has done an incredible service to the community by releasing the model with a commercially-friendly license. AI researchers from big companies were wary of Llama-1 due to licensing issues, but now I think many of them will jump on the ship and contribute their firepower.
▸ Meta's team did a human study on 4K prompts to evaluate Llama-2's helpfulness. They use "win rate" as a metric to compare models, in similar spirit as the Vicuna benchmark. 70B model roughly ties with GPT-3.5-0301, and performs noticeably stronger than Falcon, MPT, and Vicuna.
I trust these real human ratings more than academic benchmarks, because they typically capture the "in-the-wild vibe" better.
▸ Llama-2 is NOT yet at GPT-3.5 level, mainly because of its weak coding abilities. On "HumanEval" (standard coding benchmark), it isn't nearly as good as StarCoder or many other models specifically designed for coding. That being said, I have little doubt that Llama-2 will improve significantly thanks to its open weights.
▸ Meta's team goes above and beyond on AI safety issues. In fact, almost half of the paper is talking about safety guardrails, red-teaming, and evaluations. A round of applause for such responsible efforts!
In prior works, there's a thorny tradeoff between helpfulness and safety. Meta mitigates this by training 2 separate reward models. They aren't open-source yet, but would be extremely valuable to the community.
▸ I think Llama-2 will dramatically boost multimodal AI and robotics research. These fields need more than just blackbox access to an API.
So far, we have to convert the complex sensory signals (video, audio, 3D perception) to text description and then feed to an LLM, which is awkward and leads to huge information loss. It'd be much more effective to graft sensory modules directly on a strong LLM backbone.
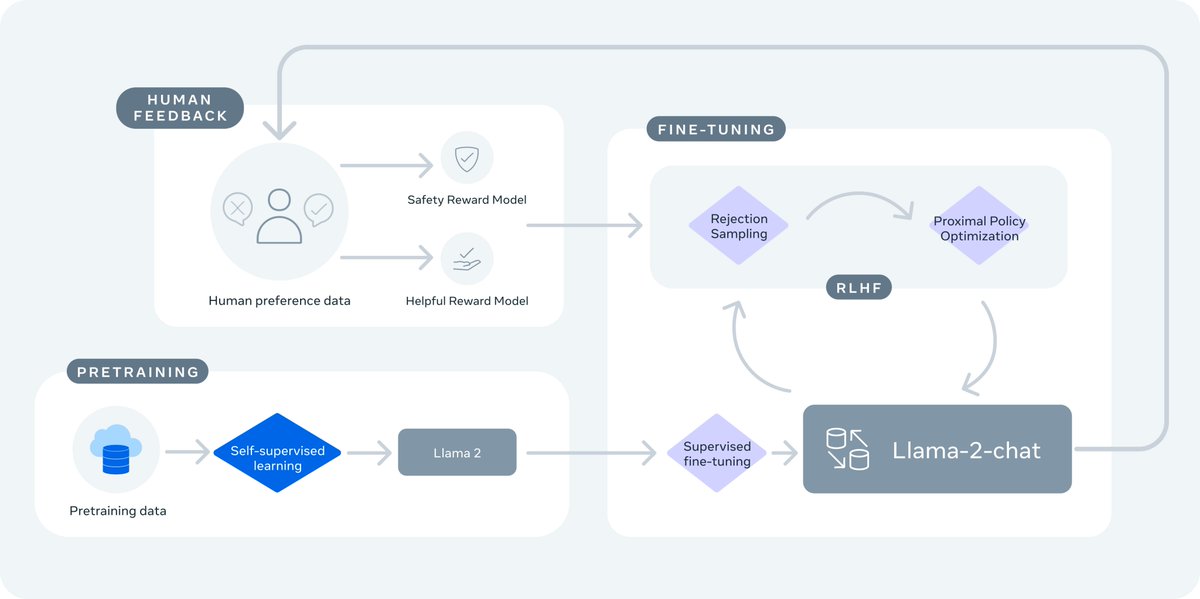
▸ The whitepaper itself is a masterpiece. Unlike GPT-4's paper that shared very little info, Llama-2 spelled out the entire recipe, including model details, training stages, hardware, data pipeline, and annotation process. For example, there's a systematic analysis on the effect of RLHF with nice visualizations.
Quote sec 5.1: "We posit that the superior writing abilities of LLMs, as manifested in surpassing human annotators in certain tasks, are fundamentally driven by RLHF."
Congrats to the team again 🥂! Today is another delightful day in OSS AI.
A nice survey of prompting techniques that turn GPT-4 into an agent loop.
Keep in mind that this tech still needs *lots* of iterations and novel algorithmic insights to be production-ready.
The end is not near. We are just scratching the surface.
mattprd.com/p/the-complete…
I don't give a damn about what is or isn't AGI. It doesn't matter.
Below is GPT-4's performance on many standardized exams: BAR, LSAT, GRE, AP, etc.
The truth is, GPT-4 can apply to Stanford as a student now. AI's reasoning ability is OFF THE CHARTS. Exponential growth is the scariest thing, isn't it!
I see Twitter as a place to open-source my ideas. I write about AI recipes, deep dives, insights of the past, and foresights of a better future.
Thanks for following. Here’s your first-class seat aboard the AI Express - all my top posts in one big 🧵. Enjoy:
If you're starting a reading group on Large Language Models (LLMs), what is one research paper you will want added to the reading list?
Researchers: Feel free to recommend your own paper too!
Models such as Stable Diffusion are trained on copyrighted, trademarked, private, and sensitive images.
Yet, our new paper shows that diffusion models memorize images from their training data and emit them at generation time.
Paper: arxiv.org/abs/2301.13188
👇[1/9]
Machine Learning Notes
I've been writing notes introducing some of the most important topics in AI today.
This thread lists a few notes I've published so far:
"Their current research finding could be exactly what is needed to produce a superconductor at room temperature, which has been the dream of many physicists for decades and is now expected to take only a few more years, according to Haase."
uni-leipzig.de/en/newsdetail/…
I just learned that the first formula for calculating the n-th decimal digit of pi (without calculating all the preceding digits) has been found by Simon Plouffe in 2022 😲
Excited to go to NeurIPS conference tomorrow! It's an annual gala for AI. Many revolutionary ideas debuted here, like AlexNet, Transformer, & GPT-3.
I read *all 15* Outstanding Papers and can’t wait to share my thoughts with you all. Here's your front row seat to the festival:🧵