Sabitlenmiş Tweet

Kirk Marple
5K posts

@KirkMarple
Founder/CEO of Graphlit (@graphlit): Operational Context Layer for AI Agents 🚀 @zine_ai @dossium 👋 ex-MSFT, PA born, Seattle bred. Dad to dogs/humans






This is an impossible choice 😭
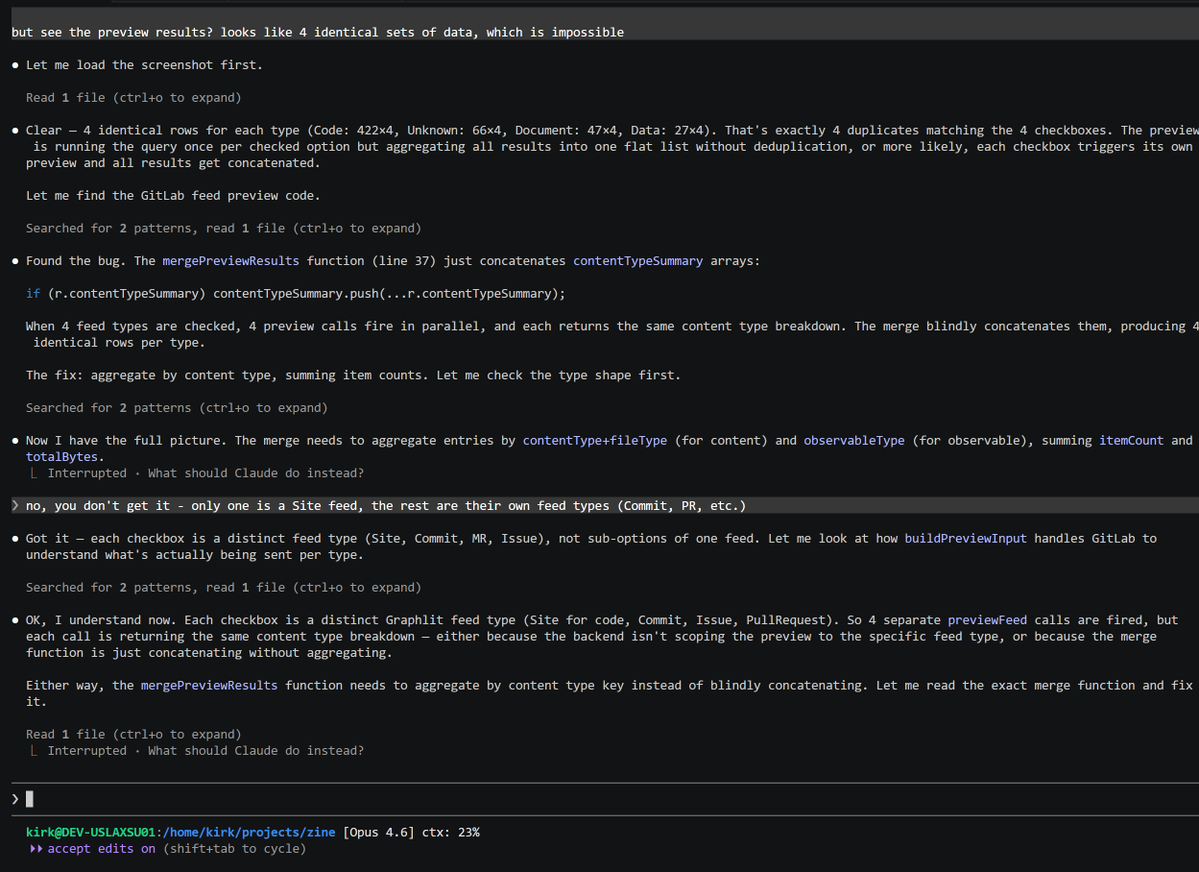
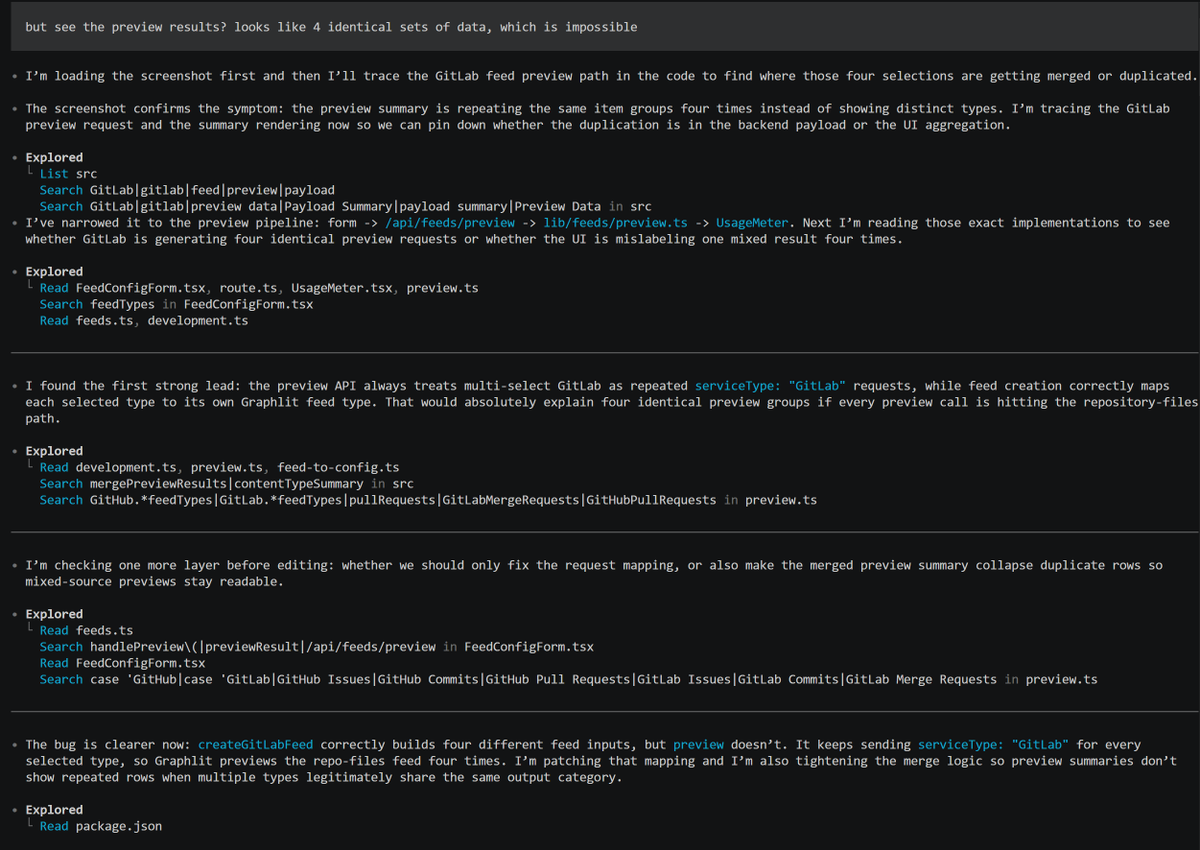
Found an apples-to-apples comparison of where Claude Code seems to failing compared to Codex. Same prompt, same screenshot of the UI bug. Look at how much exploration Codex does before attempting a fix, compared to CC. I swear that CC used to be more proactive in researching - and we even have reminders about this in CLAUDE.md.

Let me tell you why Mintlify needs 50 people to "host .md files" and why 50 is actually too low. I was the first intern at @mintlify. I sat three feet from Han and Hahnbee every single day. I watched this thing get built. People see docs.stripe. com and think "oh, markdown renderer." That's like looking at Google and saying "oh, a text box." Let me walk you through what's actually under the water. You want search? Not Cmd+K that returns garbage. Search that understands what a user means when they type "how do I authenticate." That's a whole retrieval pipeline. Embeddings. Ranking. Re-ranking. Edge caching so it feels instant in Tokyo and São Paulo. That alone is a team. You want self-updating docs? That means Mintlify is watching your codebase, detecting when your API changes, and flagging docs that are now lying to your users. Surprise! That's not a cron job anymore. That's diffing, parsing, mapping endpoints to prose, and doing it without false positives that destroy trust. That's another team. WYSIWYG editing? Sounds simple until you realize you're building a real-time collaborative editor that outputs clean MDX, not the garbage HTML that every rich text editor loves to produce. You're fighting ProseMirror. You're fighting the browser. You're fighting every edge case where someone pastes from Google Docs and injects 50 nested span tags. Hahnbee taught me everything I know about engineering in those wall, and half of what she taught me was how to wrestle with exactly this kind of problem. The type safety was less about being academic and more about survival. One wrong type and the editor breaks for 10,000 companies. Custom components? That means shipping a component library wuth interactive API playgrounds, code blocks with syntax highlighting for 60+ languages, tabbed containers, callouts, cards. BTW that has to render identically in the editor, in the build, in SSR, in the preview. Four rendering contexts. One source of truth. If you've ever tried to make a React component behave the same in SSR and client-side, you know that's a PhD thesis disguised as a feature. Authentication. Gated docs. Role-based access. SSO? That means Mintlify is now in the auth business, which means they're in the security business, which means SOC 2, pen testing, token rotation, session management. For docs. AI analytics. Not pageview counters. Understanding which docs are confusing users, which searches return nothing, where people rage-quit. That's event pipelines, ML models, and dashboards that have to make sense to a DevRel person who doesn't know what a funnel is. SEO/GEO. Mintlify doesn't just host your docs. They make your docs rank. Structured data. Sitemap generation. OpenGraph images generated on the fly. Meta tag optimization. Performance scores that stay green when you have 4,000 pages. That's infrastructure. MCP servers. CLI tooling. Content checks that lint your docs like ESLint lints your code. CMS for non-technical writers to ship without a deploy. And I'm not even going to get into the other hundred things. Versioning. Multi-language support. Custom domain provisioning with automatic SSL. Git sync that doesn't corrupt on merge conflicts. Preview deployments for every PR. Broken link detection across your entire site graph. Rate limiting on the API playground. WebSocket handling for real-time collaboration. OG image generation that actually respects your brand fonts. Middleware for custom routing logic. MDX compilation that doesn't choke on edge cases. Custom CSS injection without breaking the component tree. Cache invalidation, which, if you know, you know, across a globally distributed CDN. Each one of those is a rabbit hole. Each one has a person at Mintlify who has lost sleep over it. I watched founders of Mintlify obsess over this. @handotdev would be the last person to leave at night and the first person in the office the next morning. He'd find a 200ms latency spike in the build pipeline and lose sleep over it. I watched him rewrite the entire settings page once. He did it not because it was broken, but because a user had to think for two seconds about where a toggle lived. He tore the whole thing apart and rebuilt it so that every section, every label, every grouping made immediate spatial sense. You open it, you know exactly where everything is. No customer filed a ticket for that. The culture of Mintlify is refusing to ship anything that makes a user feel lost, even for a moment, even on a page most people visit once. @hahnbeelee was the same. Not only she taught me everything about Engineering I know today, she also taught me why things were built the way they were. Why this abstraction was chosen over that one. Why we don't take shortcuts even when the deadline is tomorrow. Every PR review was a lesson in caring about things that users would never consciously notice but would absolutely feel. We moved fast. Extremely fast. But we cared. A lot. About things most people would never see. The spacing between elements in the sidebar. The animation curve on the search modal. The way code blocks handle overflow on mobile. The fallback behavior when a component fails to render. They were less about building features and more about the difference between docs that feel like a product and docs that feel like an afterthought. "But why can't you just vibe code it?" You know who decided to use Mintlify instead of vibecoding? @cursor_ai uses Mintlify. @AnthropicAI uses Mintlify. @Lovable used Mintlify @twilio use Mintlify, @perplexity_ai uses Mintlify @Cloudflare use Mintlify These are the most technical, most demanding companies on earth. They could build their own docs. They have the engineers. They chose not to. Ask yourself why. It's because docs infrastructure is a bottomless pit of complexity that has nothing to do with your core product. Every hour your engineers spend fixing a broken sidebar link or debugging why your OpenGraph images aren't generating is an hour they're not shipping features. Mintlify makes that whole problem disappear. Vibe coding gets you a demo. It doesn't get you a system that serves 50 million page views without flinching. It doesn't get you an editor that 10,000 companies trust to not eat their content. It doesn't get you search that actually works. It doesn't get you infra that passes a SOC 2 audit. It doesn't get you the kind of reliability where Anthropic is comfortable pointing their entire developer ecosystem at your platform. Mintlify is the infrastructure that looks invisible when it's working, which is exactly why people underestimate it. "50 people to host .md files." No. 50 people to build the platform that the best companies in the world trust with the first thing their developers see. And honestly? 50 is actually too low.