Sabitlenmiş Tweet
kodee
440 posts


@fleshsimulator Its because they display actual ambition in joy in a world thats gray. The modicum of whimsy is becoming more and more weighted in the current world.
English

its because they make facial expressions
Quality Learing Center@qualitylearnc
Standards have plummeted so badly that these two women are now considered celebrity crushes
English
@LeadingReport The UFO files will literally be propaganda. "It's been us, always have been, we have had tech beyond realitys limits since the 80's" thats gonna be the whole thing
English

FBI Director Kash Patel confirms UFO files have been delivered for release.
English


@dobroslav_dev @xlr8harder @xai More like 3x but no its not if you have time critical applications thats why -fast- was made
English

English

This is terrible @xai. I just spent time and money to migrate to grok 4.1 fast, and you're disabling it with less than two weeks notice, after releasing it in November, with no migration path to a fast/cheap alternative.
I will never depend on one of your products again.

English

English

They ran an entire pretrain + finetuning + SoTA architectural research with a team of 4 and 30 mil?
Something is fishy. Maybe they're insanely talented, but no one is training an 80% SWE-Bench model on a 30mil pretrain

Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English


@xlr8harder @xai Yes but read the announcement again it’s about retiring from “xAI API” they might have contracts with openrouter they need to uphold. Otherwise it would have a “departing soon” banner on openrouter. I assume it’s similar to how Sonnet 3 is still on openrouter
English
@McDonaldsJapan She didn’t eat it because: ITS PLASTIC and so her face stays clean for a pretty shot. Not everything is a conspiracy
English

@sdmat123 @not_ellington @evermind Most of AI research sadly is smoke and mirrors and most papers are written by Claude. It’s all just a way to milk venture capital while real labs get punished for doing actual research
English
@SonicHacki i dont wanna know how many goth mommys are millionaires because of elons autism
English

random reminder that this was the reason likes are now private on twitter
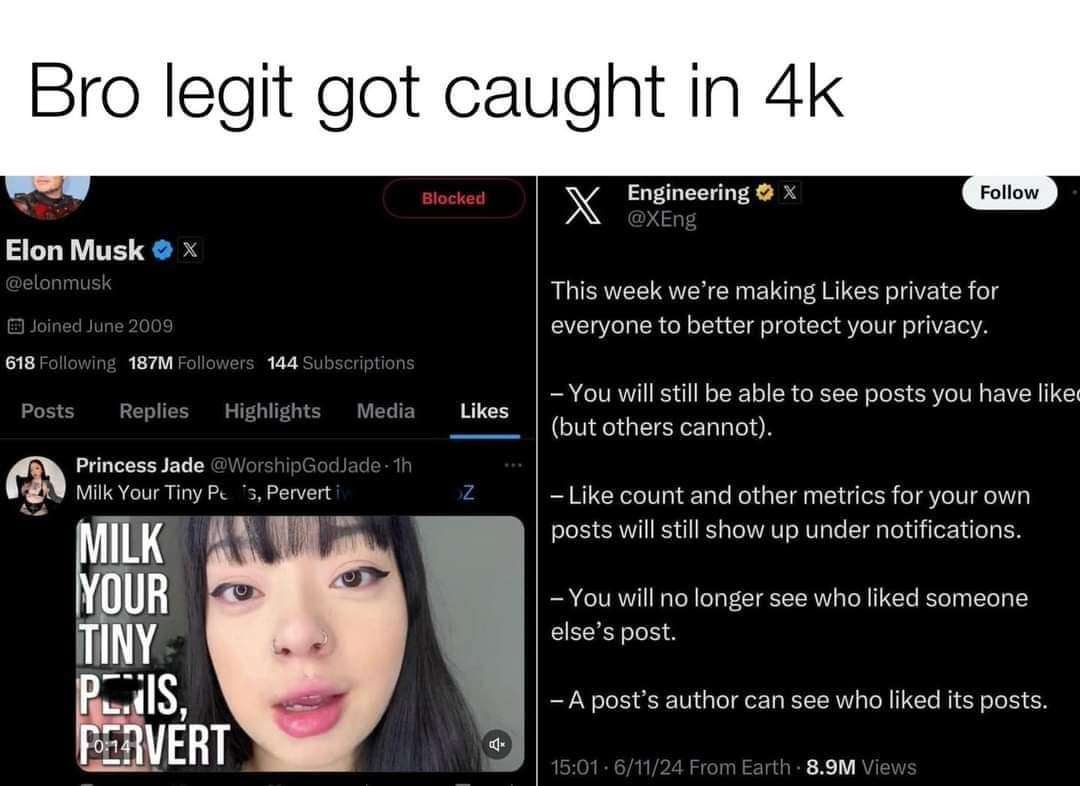
English
kodee retweetledi

Colossus Training will begin. 10T Grok 5 🧐
xlr8harder@xlr8harder
This is terrible @xai. I just spent time and money to migrate to grok 4.1 fast, and you're disabling it with less than two weeks notice, after releasing it in November, with no migration path to a fast/cheap alternative. I will never depend on one of your products again.
English
@xlr8harder @xai 4.3 is quite a cheap too, no big deal
English

@sdmat123 @not_ellington They are using @evermind 's MSA 4B Checkpoint. EverMind even benchmarked it to 100M context
English
@Hesamation The new era of pump and dump. Congratulations on being on the good side.
English

> 12M context window (read it again)
> 52x faster than FlashAttention
> beats Opus 4.6 on SWE-Bench
> 5% the cost of Opus
BUT WAIT A MINUTE:
> technical blog not technical
> access coming soon
> paper coming soon
> ““Built by researchers from Meta, Google, Oxford, Cambridge, BYU” doesn’t name a single one of them
if this is not a scam, or the numbers aren’t dishonest, it’s disgustingly promotional.

Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English
@JosephJacks_ @RRulehard Please proof your claim that there has been any sort chip 4 billion years ago.
English

Biology is 10+ orders of magnitude more sophisticated than transistor based computers… which includes all of AI today.
Charles Rosenbauer@bzogrammer
These two things are about the same size "2nm" transistor gate pitch : 42nm Flagellum motor : 45nm
English
@JosephJacks_ @RRulehard havent seen singel cell organisms do advanced lithographie
English